论文信息
题目:Local Map-Based DQN Navigation and a Transferability Metric Using Scene Similarity
作者:Shiwei Lian and Feitian Zhang
来源:arXiv
时间:2023
Abstract
在没有全球地图的未知环境中进行自主导航是移动机器人面临的长期挑战。
虽然深度强化学习(DRL)因其泛化能力而引起了人们对解决此类自主导航问题的兴趣迅速增长,但由于训练场景与实际测试场景之间的差距,DRL 在实践中通常会导致平庸的导航性能。大多数现有工作都集中在调整算法以增强其可迁移性,而很少研究如何量化或测量其之间的差距。
本文提出了一种基于局部地图的深度 Q 网络 (DQN) 导航算法,该算法使用从 2D LiDAR 数据转换而来的局部地图作为观测值,而无需全局地图。
更重要的是,本文提出了一种新的可转移性度量——通过改进的图像模板匹配算法计算出的场景相似度,以衡量训练场景和测试场景之间的相似度。以轮式机器人为案例研究平台,在总共20个不同的场景中进行了仿真和现实实验。
案例研究结果成功验证了基于本地地图的导航算法以及预测算法可转移性或成功率的相似性度量。
Introduction
传统的设计将导航分为地图、本地化、全局规划和局部规划等子模块。首先使用 gMapping [1]、Hector Slam [2] 等同步定位与建图 (SLAM) 技术构建全局地图,然后使用 A 等路径规划算法基于建立的地图设计全局路径。A [3] 和 RRT [4]。最后,局部运动规划器(例如动态窗口方法(DWA)[5])引导移动机器人遵循全局路径的路点。
这些传统方法依赖于全球地图的准确性。当在新的环境中使用时,需要更新设计参数。
为了克服传统方法的局限性,深度强化学习(DRL)算法越来越受到科学界和工程学界的关注,并已被应用于增强导航性能。 DRL算法通过智能体与环境的交互来学习动作策略,具有一定的泛化能力。常用的DRL算法包括DQN[6]、DDPG[7]、PPO[8]、TD3[9]、SAC[10]等。移动机器人DRL导航中使用的传感器数据包括但不限于2D LiDAR 、RGB 图像和深度图像。虽然直接使用原始传感器数据作为 DRL 输入很简单 [11]、[12],但更多的研究工作致力于在导航中预处理或融合传感器数据 [13]-[20],以提高导航系统的鲁棒性
上述导航算法依赖于在导航过程之前或过程中构建的全球地图,然而,许多实际应用没有这样的全球地图或构建它的时间,以进行灾难响应和搜救例如。
为了解决这个问题,研究人员研究了不依赖全球地图的基于 DRL 的端到端导航算法。
尽管这些没有全局地图的 DRL 导航算法通常声称可以推广到新环境,但当遇到与训练中的观察结果不同的新观察结果时,该算法很可能会输出不正确的操作。此外,DRL导航通常首先在模拟中进行训练,然后部署到现实环境中,其中训练和测试场景之间不可避免地存在差异。
目前针对这些问题主要有两种解决方案。
一、是更新DRL算法以增强可迁移性。
二、是让训练和测试场景的观察尽可能接近。
本文首先提出了一种不依赖于全局地图的基于本地地图的 DQN 导航算法。 2D LiDAR 数据、代理位置和目的地位置融合到本地地图上,作为动作网络的输入。随后,这封信提出了一种场景相似性度量来量化 DRL 导航算法的可转移性。据作者所知,这是首次使用改进的图像模板匹配算法为基于 DQN 的移动机器人导航设计这种可转移性度量。进行了使用轮式机器人系统(TurtleBot)的案例研究。
Problem Description
本文的目的是应用 DRL 方法在没有全局地图先验知识的情况下设计移动机器人的导航算法,并提供所设计的算法在应用于新的未知环境时的可迁移性的度量。我们假设在时刻 t,机器人代理将传感器测量值及其与目的地的相对位置作为观察值 o t o_t ot。应用 DRL 算法在训练场景 S t r a i n S_{train} Strain 中学习权重为 θ 的策略 π。当应用于测试场景 S t e s t S_{test} Stest 时,该策略预计会将观察 o t o_t ot 映射到合适的代理操作 u t u_t ut ,以引导代理朝目的地而不发生碰撞,即,
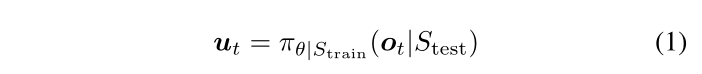
训练和测试场景之间的差距通常是学习策略在新环境中部署失败的主要原因。为了增加DRL策略的可迁移性,希望训练和测试场景之间的相似度尽可能高,即
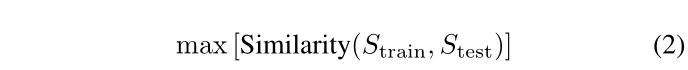
对于第一个问题(方程(1)),本文提出了一种基于本地地图的 DQN 导航算法,该算法使用本地 2D LiDAR 数据以及机器人代理与其目的地之间的相对位置作为观测值。对于第二个问题(方程(2)),使用改进的图像模板匹配方法提出场景相似性度量来量化导航算法的可迁移性。
Local Map-Based DQN Navigation
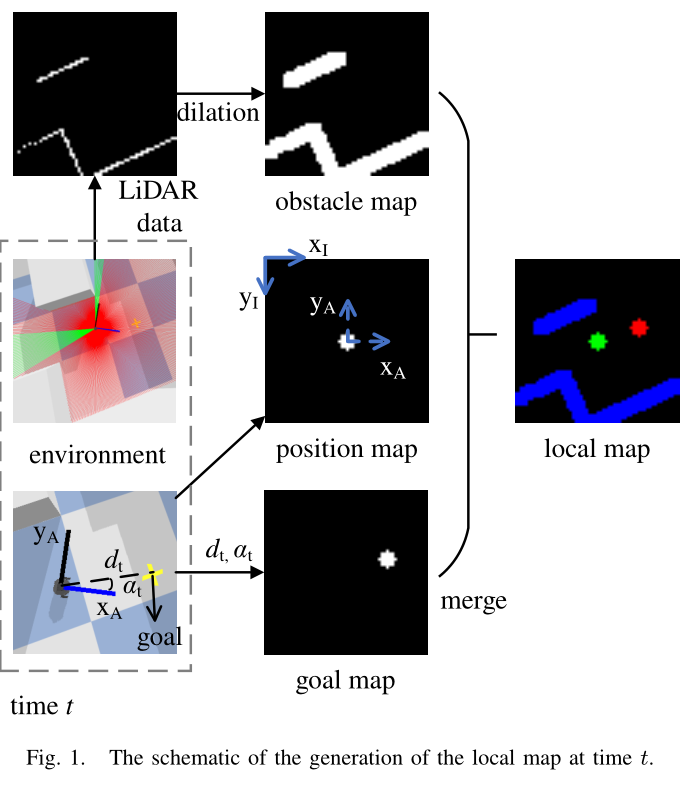
本节设计一种 DQN 导航算法,该算法将移动机器人的本地地图作为其动作网络的输入。本地地图将 2D LiDAR 数据以及移动机器人的位置和目的地编码到图像上。
DQN Algorithm
运动规划被视为马尔可夫决策过程(MDP)。 MDP由元组 ( S , A , T , r , γ ) (S, A, T ,r, γ) (S,A,T,r,γ)表示,其中 S = { s } S = \{s\} S={
s}是状态空间, A = { a } A = \{a\} A={
a}是动作空间, τ \tau τ是表示概率分布的状态转移函数在当前状态 s 下执行动作 a 时的下一个状态的值,r 是奖励函数,γ ∈ [0, 1] 是折扣因子。在每个离散时间步,智能体选择一个动作并根据当前状态执行它。然后代理会收到奖励并转换到下一个状态。代理的目标是学习最优策略 π ∗ ( a ∣ s ) π^*(a|s) π∗(a∣s),最大化动作值函数或 Q 值函数描述的预期回报,即
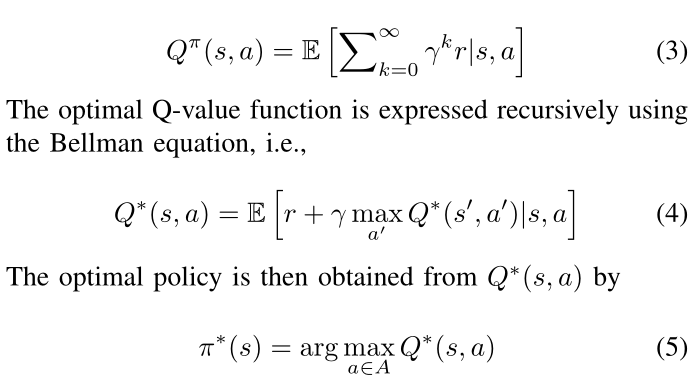
DQN 算法结合了深度学习和 Q 学习,利用神经网络来逼近复杂系统的 Q* 函数。它包含两个深度神经网络,包括权重为 θ 的 Q 网络和权重为 θ − θ^− θ− 的目标网络。 Q 网络的权重在每次迭代 i 时使用梯度下降进行更新,以最小化以下损失函数
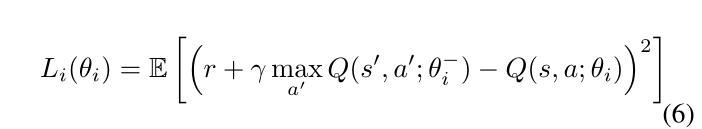
连续采集的样本之间的相关性不满足深度学习中独立同分布的假设,导致深度神经网络收敛困难。为了解决这个问题,DQN 引入了经验重放,它将每个时间步的智能体与环境交互获得的数据存储到重放缓冲区中。在每次训练迭代中,都会从重放缓冲区中随机采样一小批数据。这样提高了数据的利用率,减少了训练数据之间的相关性。
Local Map-Based DQN Navigation
该文选择移动机器人的局部地图作为观测值,在不使用全局地图的情况下实现自主运动规划。基于本地地图的DQN导航的实现具体如下。
Observation space:局部图被定义为观测值或DQN网络的输入,表示为 M = ( M o , M p , M g ) ∈ R H × W × 3 M = (M_o, M_p, M_g) ∈ \mathbb{R}^{H×W ×3} M=(Mo,Mp,Mg)∈RH×W×3。这里,H和W分别表示地图的高度和宽度。 M o M_o Mo是由2D LiDAR数据转换成的障碍物图。 M p M_p Mp是位置图,表示智能体当前的位置。 M g M_g Mg 是目标图,表示目标点距智能体的距离和方向角。局部图保证了输入维度的均匀性,从而可以方便地利用卷积神经网络(CNN)强大的特征提取能力。此外,基于局部地图的观测对噪声具有鲁棒性,并且可适应其他传感器模块进行传感器融合。
生成局部地图的过程如图 1 所示。在时间 t 接收到的 LiDAR 数据 { ( ρ t , θ t ) } \{(ρ_t, θ_t)\} {(ρt,θt)} 通常由距离 ρt 和障碍物相对于智能体的方位角 θ t θ_t θt 组成,表达式为极坐标。 LiDAR 极坐标 ( ρ A , θ A ) (ρ_A, θ_A) (ρA,θA) 可通过以下方式转换为图像坐标 ( x I , y I ) (x_I, y_I) (xI,yI)

Action space:差动驱动机器人的动作空间包括平移速度 v t v_t vt和旋转速度 ω t ω_t ωt,即 { a t : = [ v t , ω t ] } \{a_t := [v_t, ω_t]\} {
at:=[vt,ωt]}。不失一般性,这封信中考虑了三个离散动作,即 v = 0.15 m/s, ω ∈ {−1.0, 0.0, 1.0} rad/s
Reward design:智能体的目标是利用即将到来的本地地图观测,在不与障碍物碰撞的情况下尽快到达目的地点。时间 t 的奖励(用 r t r_t rt 表示)被设计为两项 r t g r^g_t rtg 和 r t c r^c_t rtc 之和,如等式 1 所示。 (8)–(10)。 r t g r^g_t rtg 用于确保智能体达到目标。当它进入目标附近时,它会收到正奖励;当它远离目标时,它会收到负奖励。 r t c r^c_t rtc 用于避免智能体与障碍物发生碰撞。当发生碰撞时它会产生负奖励。


Network architeture:根据DQN导航任务和可用的本地地图观测来选择网络架构,如图2所示。三个卷积层有效地提取输入本地地图的特征。然后特征图由全局最大池化层处理以提取全局特征。全局特征被展平并输入到完全连接的层中。输出是三个动作的Q值。全局最大池化层的使用允许输入局部映射具有任意大小。
Termination conditions:在DQN训练中,如果满足以下条件之一,则episode将被终止。
1)智能体达到目标。 2)智能体与障碍物发生碰撞。 3)时间步数超过10,000。
Scene Similarity Metric Based on Improved Image Template Matching
据作者所知,目前还没有任何指标可以衡量移动机器人基于本地地图的 DRL 导航算法的可转移性。本节提出了一种基于改进的图像模板匹配的场景相似性度量来量化算法的可迁移性,该度量利用训练场景的全局障碍物图和测试场景中收集的局部地图。所提出的指标预计将为测试场景中的训练场景和/或迁移学习算法的设计提供指导。
Image Template Matching Algorithm
图像模板匹配是一种搜索并找到模板图像与另一幅较大图像之间最大匹配的图像处理方法。将模板图像滑动到感兴趣的图像上,算法计算子图像与模板图像之间的相似度,并输出相似度最大的位置作为匹配结果。相似度计算为归一化相关系数 R I , T ( x , y ) R_{I,T} (x, y) RI,T(x,y):

上述模板匹配适用于模板与图像中的目标物体方向相同的情况。当目标和模板之间存在方向差异时,匹配通常会失败。
因此,需要对模板图像进行旋转,生成一系列具有不同旋转角度 ϕ \phi ϕ 的模板。最佳比赛得分随后更新为
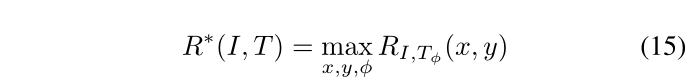
Scene Similarity Metric
提出场景相似度度量来量化 DQN 导航算法的可迁移性。该度量计算测试场景中的实际观察结果与训练场景中的观察结果之间的相似度。
由于训练场景的全局地图是可用且容易获得的,因此为了计算方便,所提出的度量使用全局障碍物地图而不是局部地图。
场景相似度度量的计算基于第 IV-A 节中描述的图像模板匹配方法。待匹配的图像是训练场景的全局障碍物图,用 M o g l o b a l M^{global}_o Moglobal 表示。模板是由测试场景中 LiDAR 测量结果转换而来的局部障碍物地图,旋转角度为 ϕ \phi ϕ。图像模板匹配方法找到测试场景中收集的局部障碍物图与训练场景的全局障碍物图之间的平均最佳匹配分数。
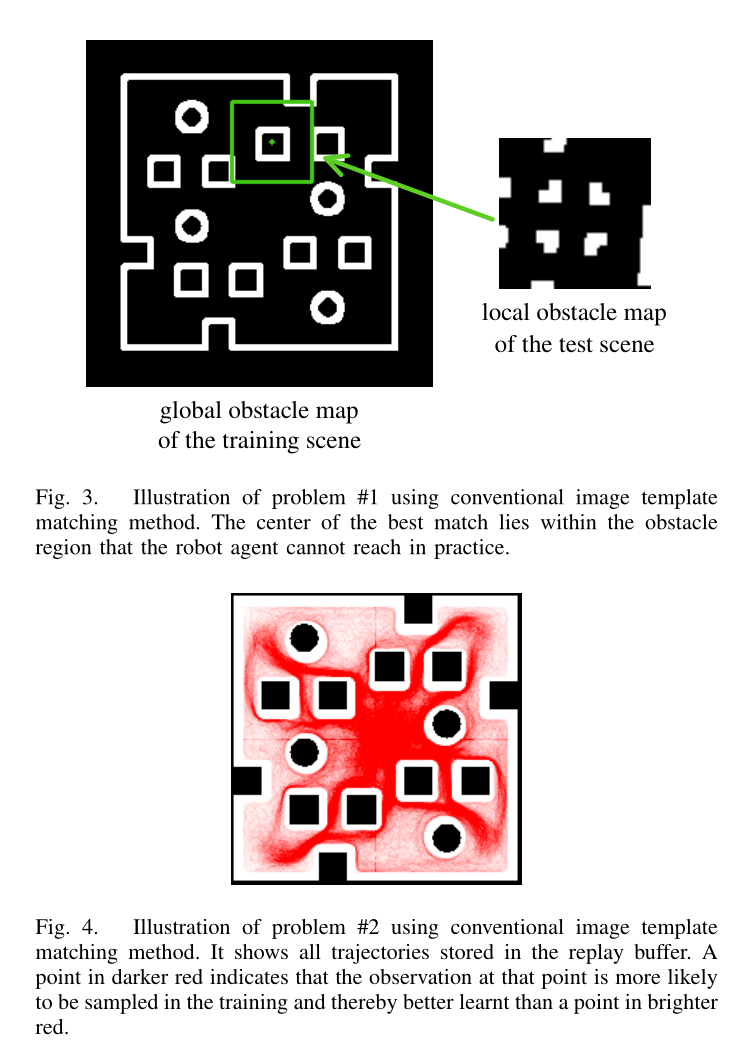
然而,直接使用模板匹配会导致以下两个问题。
1)如图3所示,最佳匹配子图像的中心有时位于训练场景中的障碍物区域内,但智能体在训练过程中无法到达这样的位置。
2)图4显示了训练期间存储在重播缓冲区中的智能体的所有轨迹,其中红色的黑色表示到达的总数。我们观察到不同位置之间关于训练中使用观察次数的显着差异,全局障碍物地图中的不同位置具有相同重要性级别是没有意义的。
为了解决这些问题,通过在匹配分数的计算中引入权重矩阵来更新模板匹配方法。权重是根据智能体在训练过程中到达全局地图上特定位置的次数来计算的,这表明了相应位置的匹配分数的重要性。 M o g l o b a l M^{global}_o Moglobal 中位置 (x, y) 的权重计算如下
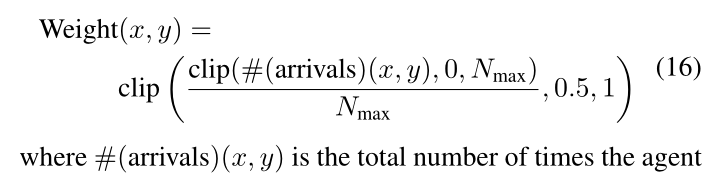
在训练期间到达 M o g l o b a l M^{global}_o Moglobal 中的位置 (x, y)。为了规范权重并防止其太小,使用了两层剪辑功能。在第一层中, N m a x N_{max} Nmax 是到达我们认为给出最高重要性的阈值的位置的代理总数。在第二层中,[0.5,1]用于定义权重值的范围。
场景相似度得分 S S SS SS 的公式如下。首先,代理从测试场景收集 N 个局部障碍物地图 M o i , i ∈ [ 0 , N ) {M_{oi}, i ∈ [0, N)} Moi,i∈[0,N)。然后,{M_{oi}, i ∈ [0, N)} 与训练场景的全局障碍图 M o g l o b a l M^{global}_o Moglobal 之间的平均最佳匹配分数计算如下:

最后,场景相似度度量被定义为相对场景相似度得分 S S r e l SS_{rel} SSrel 或测试场景 S S t e s t SS_{test} SStest 中计算的相似度得分与训练场景 S S t r a i n SS_{train} SStrain 中计算的相似度得分之间的差值,即
S S r e l = S S t e s t − S S t r a i n SS_{rel}=SS_{test}-SS_{train} SSrel=SStest−SStrain
Case Study
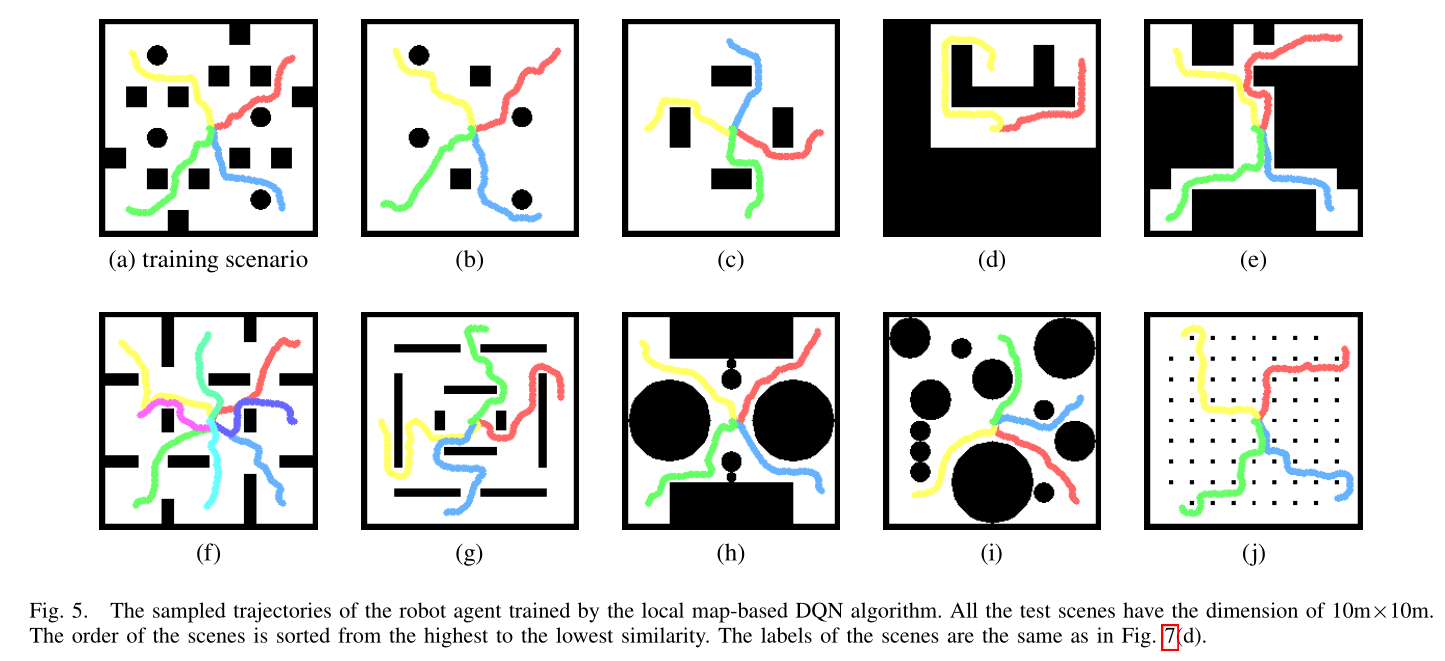
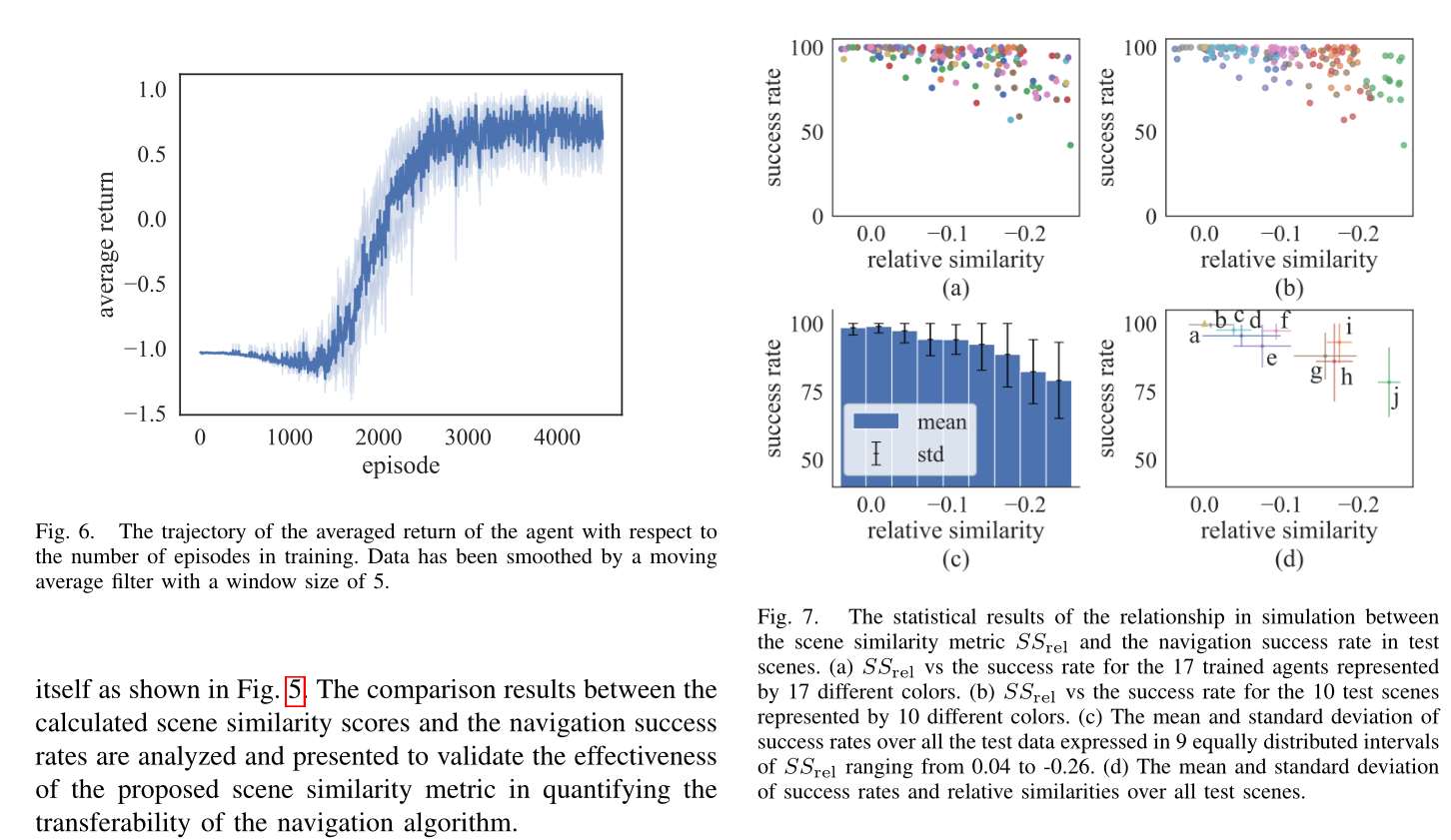

Conclusion
在本文中,设计了一种使用本地地图和 DQN 的 DRL 算法,用于未知环境中移动机器人的导航。
本文提出了一种新颖的场景相似性度量,使用改进的图像模板匹配算法来量化导航算法的可转移性。在总共 20 个真实世界和模拟测试场景中进行了轮式机器人案例研究。仿真和实验结果验证了所提出的导航算法和相应的可转移性指标,该指标可预测算法应用于新环境时的成功率。所提出的指标预计将指导训练场景的设计以及测试场景中的迁移学习执行。
在未来的工作中,我们计划完善可转移性指标。
根据案例研究的结果,综合考虑场景相似性和场景复杂性。
此外,我们计划将所提出的度量应用于其他基于DRL的导航算法,例如DDPG、SAC等,并建立系统的可转移性量化方法以实现更广泛的应用范围。