论文地址: 论文
这篇文章的写作和创新点都比较标准, 且在VisDrone数据集上进行的训练, 因此做一篇笔记.
这篇文章主要通过数据增强的方式增加模型被实际背景遮挡的情况, 并且通过硬掩码让网络在训练时更能区分前景和背景. 在致力于解决遮挡问题的MOT的工作中, 也是一篇比较有趣的.
0. Abstract
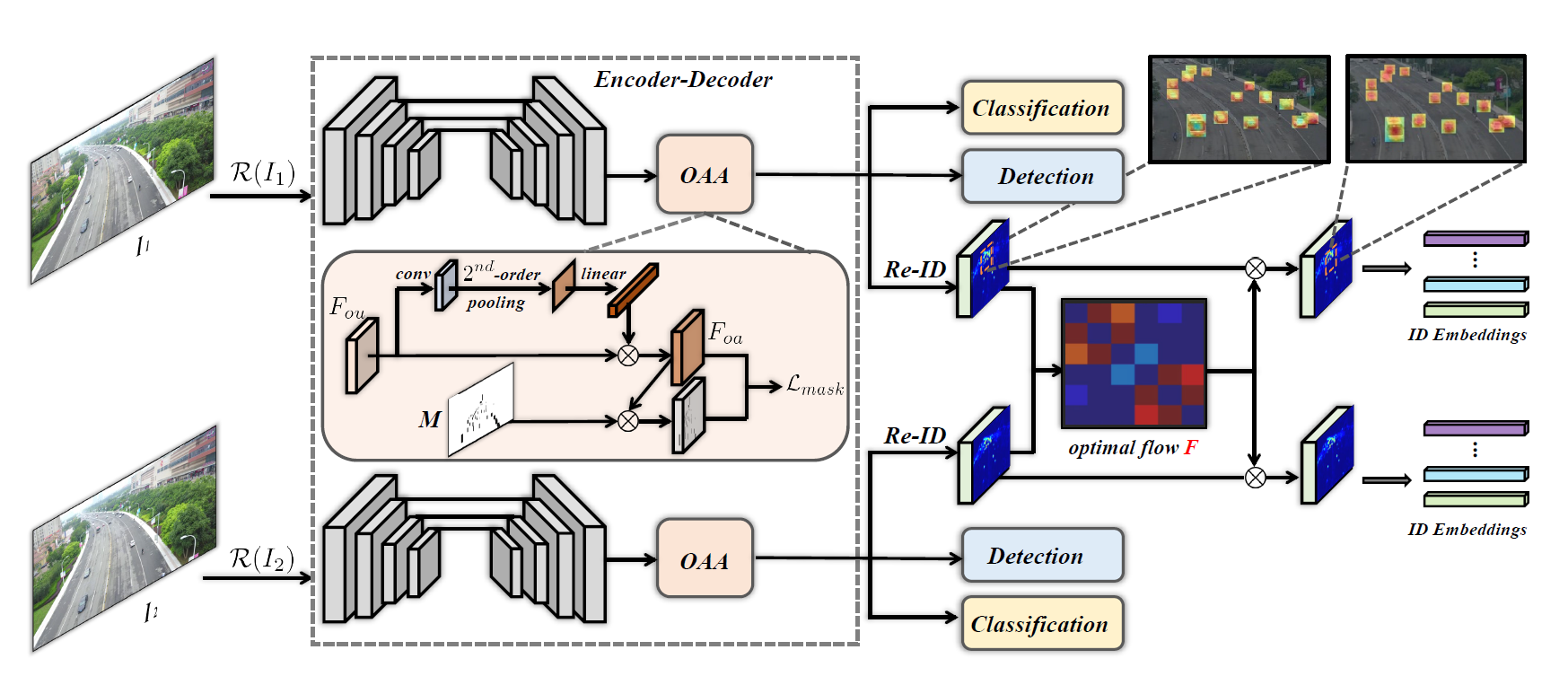
在MOT任务中, 遮挡一直是一个有挑战性的问题. 遮挡不仅会降低检测效果, 导致轨迹碎片化, 还会影响Re-ID的精度. 为此, 我们提出了ORCTrack解决遮挡问题. 具体地, 我们提出了一个关注遮挡的注意力模块(Occlusion-Aware Attention Module), 这个模块的目标是突出目标特征, 抑制背景特征, 进而提升检测器对潜在被遮挡目标的精度. 此外, 我们还设计了基于最优传输的Re-ID特征匹配模块, 目的是利用帧间的互补性对Re-ID特征进行增强和校准.
摘要的写作一般遵循这种模式: 1. 方向的应用价值/意义–2. 目前的工作存在的问题, 或者该方向中的难点, 也可以说为什么现在的方法没有解决好目前的难点–3. 针对这些难点, 我们提出了什么模块, 从思路道理上, 是如何解决的–4. 实验表明, 我们在XX数据集上达到了什么效果.
1. Introduction
MOT的算法由两个主要部分组成: 检测和Re-ID. 作者认为, 在遮挡情况下, 两个部分都会受到影响. 1. 对于检测来说, 遮挡造成的漏检会让轨迹碎片化. 2. 即使检测器足够强大, 检测出了遮挡目标, 那么Re-ID在遮挡的情况下也是不准的. 这就对应了本论文的两个创新点.
针对第一个问题, 即提升遮挡情况下的检测器性能, 作者提出了OAA模块, 利用了高阶统计量(是已有的一篇工作, 全局二阶池化层)来突出空域的特征, 也就是突出前景, 抑制背景. 针对第二个问题, 利用最优传输算法, 寻找相邻两帧之间Re-ID特征的共性部分, 进而在遮挡情况下能够更好匹配(所谓的校准).
引言的写作, 一般是将摘要的每一句话对应展开. 这篇文章的引言写作很标准. 第一段: 稍微详细说明方向的应用价值和背景; 第二段: 该方向的主要流派(例如MOT, 就是TBD和JDT), 这些流派的基本思路, 以及代表工作; 第三段: 围绕文章解决的问题, 深度分析一下, 目前的方法为什么没做到, 或者分析一下问题的本质; 第四段: 详细说明所提算法的几个子模块, 每个子模块针对的问题是什么, 是如何解决的. 最后: 列出contributions.
3. Methodology
下面对每个模块分别进行介绍.
3.1. Random Erasing
在介绍提出的OAA模块和最优传输Re-ID之前, 作者说明了一种数据增强方法.
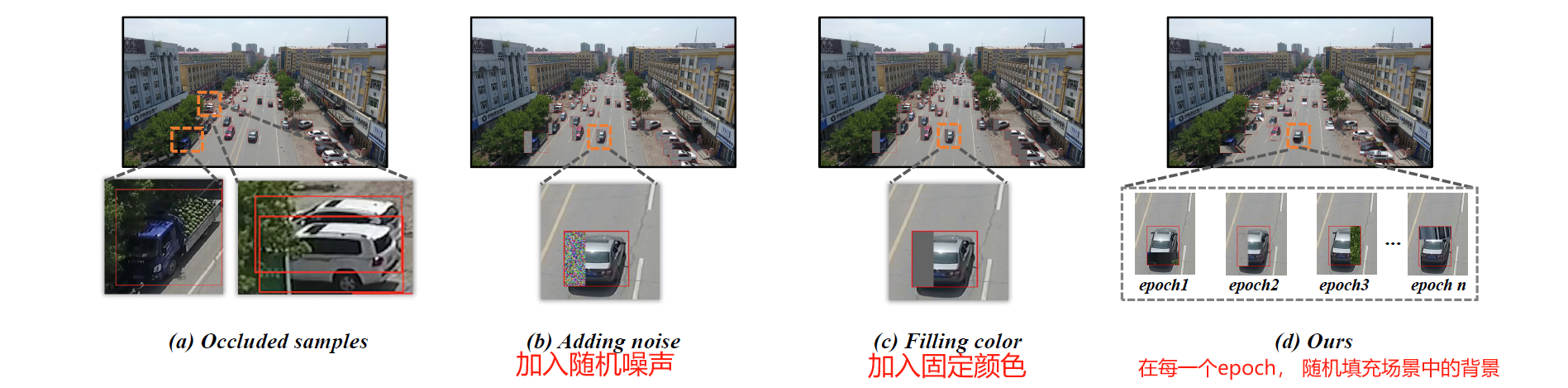
如图所示, 作者将这种填充方式称为Random Erasing. 多数MOT方法致力于解决目标间的遮挡问题, 而对于目标被背景遮挡, 一般是寄希望于检测器的提升的. 作者为了应对背景遮挡, 随机地在目标框内增加背景元素, 这样带来的仿真更加真实. 从道理上, 遮挡样本的增多有助于模型学习遮挡的情形.
以下是Random Erasing的伪代码:

3.2. OAA Module
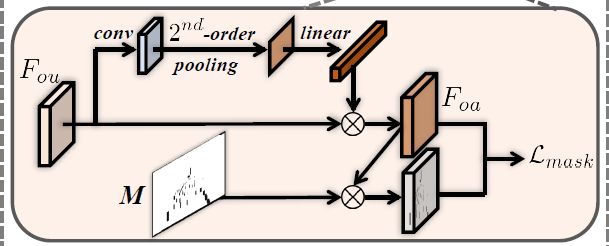
在检测器输出特征后, 这时的特征没有经过遮挡模块的优化, 称为Occlusion-unaware feature, 记为 F o u F_{ou} Fou. 随后, 利用 1 × 1 1 \times 1 1×1卷积层对 F o u F_{ou} Fou的特征维 c c c降为 c ′ c' c′. 随后, 我们计算通道维的相关性, 产生一个 c ′ × c ′ c' \times c' c′×c′的相关矩阵. 对整个特征图的通道维进行相关计算, 更有助于把握全局的信息.
随后将相关矩阵经过一个线性层, 输出 1 × 1 × c 1 \times 1 \times c 1×1×c的向量. 随后, 将该向量沿通道维逐元素与 F o u F_{ou} Fou相乘, 得到Occlusion-Aware的feature F o a F_{oa} Foa, 即可突出重要的通道, 抑制不重要的通道.
随后, 我们对前景和背景有一个Mask, 其元素值只有0, 1. 1表示该位置在目标边界框内, 0反之. 我们期望在特征热度图能够表现地尽量接近于真实的Mask, 因此作者直接以Mask作为监督准则来计算损失函数:
L m a s k = ∣ ∣ F o a − F m a s k ∣ ∣ 2 \mathcal{L}_{mask}=||F_{oa} - F_{mask}||_2 Lmask=∣∣Foa−Fmask∣∣2
整个流程如下图所示:
3.3. Re-ID特征匹配
该部分的核心创新点在于, 以前MOT算法中的Re-ID部分很少关注帧间的配准, 也就是目标仅在于将目标识别正确, 而没注意帧间(时序上的)共性特征. 作者实际上就是根据相邻两帧目标的Re-ID特征相似度, 用Sinkhorn算法对匹配进行强约束.
假设第 t − 1 t-1 t−1帧有 m m m个目标, 第 t t t帧有 n n n个目标, 那么最优传输问题就是求解如下最优化问题:

其中
A m n = 1 − s m T t n ∣ ∣ s m ∣ ∣ ∣ ∣ t n ∣ ∣ \mathcal{A}_{mn}=1 - \frac{s_m^T t_n}{||s_m||||t_n||} Amn=1−∣∣sm∣∣∣∣tn∣∣smTtn
这里作者的条件约束应该写错了. 显然方框里的式子是恒成立的, 因为左右两边都是矩阵所有元素的和.
对于在MOT中应用Sinkhorn算法, 在论文GCNNMatch: Graph Convolutional Neural Networks for Multi-Object Tracking via Sinkhorn Normalization中已经有详细说明. 下面把我的理解写一下:
相邻两帧的目标并不一定能够一一对应, 往往是由于不精确的检测, 以及新目标的加入 和老目标的退出等. 为此, 一般要在匹配矩阵再添加一行和一列, 把匹配不了的行/列扔到最后一行/列去. 如下图所示:
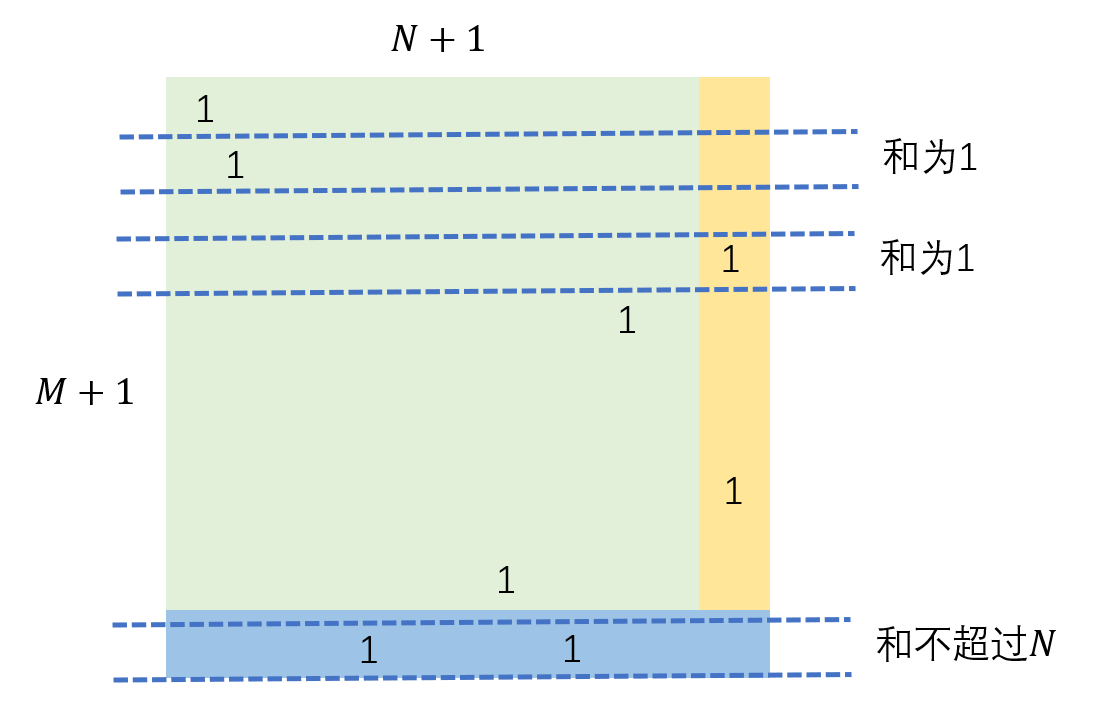
因此, 最优传输的约束应该如下所示:
对于淡绿色部分的行/列和:
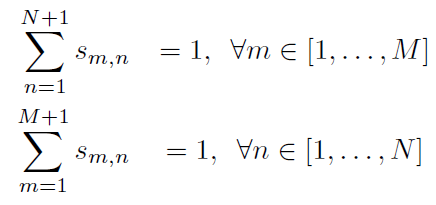
对于最后一行或者最后一列, 可以规定:
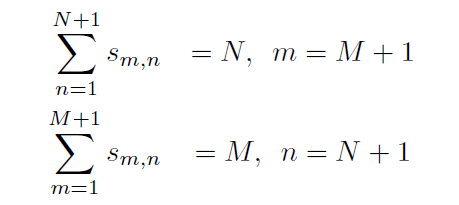
Sinkhorn更新方式:
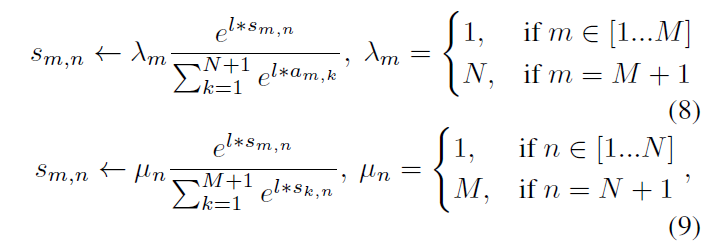
作者最后将由Sinkhorn更新完毕的传输矩阵直接与feature map相乘, 得到了增强的feature map.
整个框图如下:
3.4. 训练与推理
训练很常规. 因为Sinkhorn算法是可微的, 所以以上提出的部分可以一起训练. 唯一不同的是IoU损失作者采用了CIoU, Re-ID仍然是与FairMOT相同, 视为分类问题. 整个损失函数:
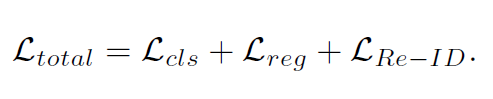
没有超参调节系数吗?
推理阶段采用了ByteTrack类似的流程.
4. 实验
实验采用了VisDrone-MOT和KITTI. 对于VisDrone的处理, 作者分成了三大类, 行人, 非车(三轮车什么的) 以及车(car, van, truck, bus). 一般来讲, 对VisDrone数据集大部分文章是只考虑五类的, 即pedestrian, car, van, truck, bus.
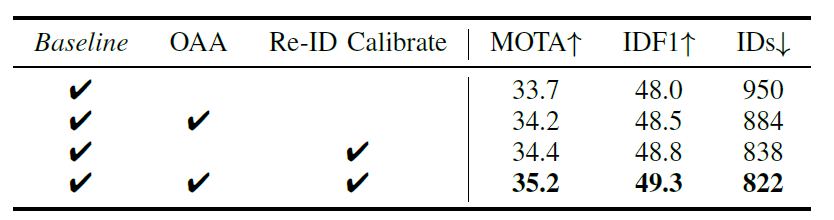
作者采用YOLO-v5作为Encoder-Decoder. 由于没有开源代码, 我猜测, 实际实现中应该跟JDE差不多. 也就是首先在head中加入Re-ID分支, 然后在分支之前的feature map之后加入OAA模块. 以下是消融实验结果:
5. 评价
这篇文章五脏俱全, 从写作上, 创新点的布局, 实验组织上是一篇标准的trans. 最大的亮点是关注到了目标-背景遮挡问题. 对于目标间遮挡, 这篇论文的novelty比不上Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation和One More Check: Making “Fake Background” Be Tracked Again. 此外还有一些数学错误, 在Re-ID的部分.