这是一篇优化匹配策略的文章, 通过密度估计的辅助, 估计一个边界框内有多少目标, 从而恢复遮挡的轨迹. 发表在IEEE TIP 2022.
论文地址: https://ieeexplore.ieee.org/abstract/document/9725267/
0. Abstract
通常的MOT算法在匹配阶段时, 都是通过线性指派问题求解, 即会计算一个代价矩阵, 例如代价矩阵的行表示轨迹, 列表示检测, 元素代表轨迹与检测之间的相似度. 往往是通过匈牙利算法等求解出代价矩阵的最佳匹配. 但是这都基于一个前提, 即对于代价矩阵 C ∈ R m × n C\in\mathbb{R}^{m\times n} C∈Rm×n的匹配结果 A ∈ { 0 , 1 } m × n A\in\{0, 1\}^{m\times n} A∈{
0,1}m×n, 满足
∑ i = 1 n A [ k , i ] = 1 , ∀ k = 1 , . . . , m ∑ i = 1 m A [ i , k ] = 1 , ∀ k = 1 , . . . , n \sum_{i = 1}^nA[k, i] = 1, \forall k=1, ..., m\\ \sum_{i = 1}^mA[i, k] = 1, \forall k=1, ..., n i=1∑nA[k,i]=1,∀k=1,...,mi=1∑mA[i,k]=1,∀k=1,...,n
换成白话就是检测与轨迹需要一一对应, 但这种情况对遮挡就不太友好, 因为一个检测框里面实际上可能有多个目标, 这样就会忽略被遮挡的目标. 为了解决这个问题, 作者将这种限制进行了松弛, 将MOT问题转换成了MIQP(Maximizing An Identity-Quantity Posterior)问题, 其实就是最大化后验概率.
1. Introduction
为了解决这个问题, 作者将普通MOT方法的ID识别部分与新提出的数量估计部分进行结合, 也就是对每一个检测, 都计算一个身份与数量的响应(identification and quantity response). 这就带来了两个问题:
- 如何计算一个detection box中的目标数量? 作者是通过VGG19密度估计网络实现的.
- 如果ID识别部分和数量估计部分发生冲突怎么办? 例如, ID识别部分说有两个轨迹以较大的概率与当前的检测匹配, 而数量估计部分说只有一个, 应该怎么处理? 作者实际上是通过简单的数学变换将二者结合了.
2. Method
2.0 问题表示
对于一共 T T T帧的检测集合 X = { X 1 , . . . , X T } \mathcal{X}=\{\mathcal{X}_1,...,\mathcal{X}_T\} X={ X1,...,XT}, 目标的ID集合 Y = { Y 1 , . . . , Y T } \mathcal{Y}=\{\mathcal{Y}_1,...,\mathcal{Y}_T\} Y={ Y1,...,YT}, 传统的MOT问题是求解如下最优化问题:
Y t ∗ = arg max Y t P ( Y t ∣ X t , Y 1 : t − 1 ) \mathcal{Y}_t^*=\arg\max_{\mathcal{Y}_t} P(\mathcal{Y}_t|\mathcal{X}_t,\mathcal{Y}_{1:t-1}) Yt∗=argYtmaxP(Yt∣Xt,Y1:t−1)
而现在, 我们不仅要估计检测对应的目标ID, 还要估计检测对应的目标数量, 因此问题就转换成估计后验概率, 共同估计计数和ID:
max Y t , C t P ( Y t , C t ∣ X t , Y 1 : t − 1 ) \max_{\mathcal{Y}_t, \mathcal{C}_t} P(\mathcal{Y}_t, \mathcal{C}_t|\mathcal{X}_t,\mathcal{Y}_{1:t-1}) Yt,CtmaxP(Yt,Ct∣Xt,Y1:t−1)
其中 C \mathcal{C} C表示检测框中目标的计数集合.
2.1 整体流程
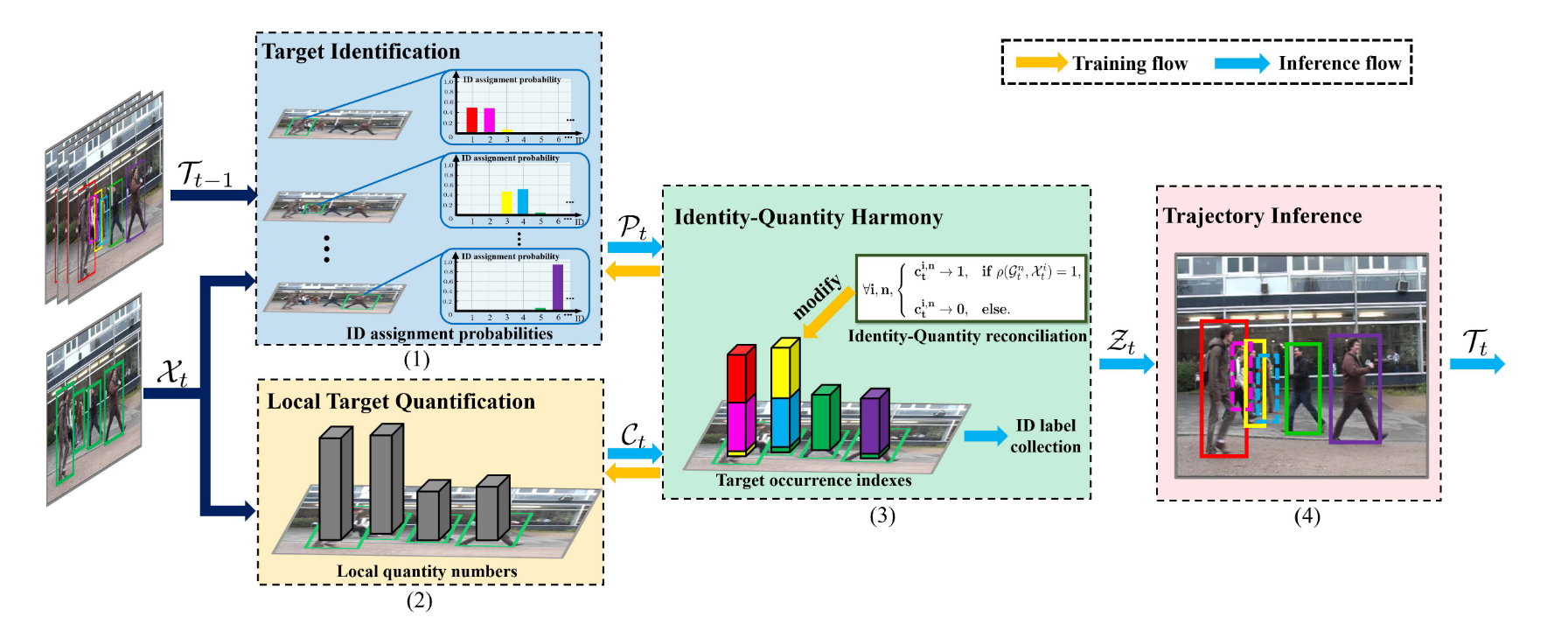
首先通过检测与轨迹的外观和运动特征构建相似度矩阵, 对相似度矩阵求解出每个轨迹属于某个检测的概率, 这一步和大多数MOT算法一样, 只是少了最后计算匹配那步.
随后利用密度估计网络计算bbox中的目标个数, 之后将二者结合计算出bbox中有几个目标, 随后更新轨迹即可.
下面逐一介绍.
2.1.1 ID识别模块
这部分比较常规, 构造相似度矩阵 S S S, 定义第 u u u个轨迹和第 v v v个检测的相似度为:
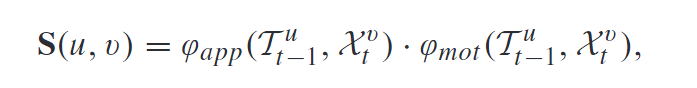
外观特征是通过外观提取网络提取的, 运动特征实际上就是Kalman预测的边界框和检测框的IoU. 得到 S S S后, 第 i i i个检测与第 n n n个轨迹匹配的概率就可以通过下式得出:
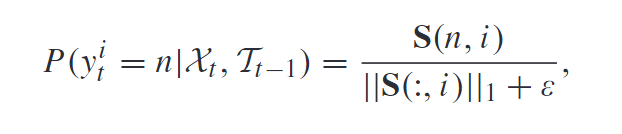
2.2.2 目标数量模块
对于密度估计网络, 输出的结果代表目标的个数, 即一个区域内包含目标的个数就是输出map的像素对应值的和. 为此, 我们可以通过求和估计每个检测框内的目标个数, 但是如果我们简单地分别计算每一个检测框中的数量, 我们会重复计算检测框交叉的那部分, 这样一来整个目标的总数就不对了, 如下图所示:
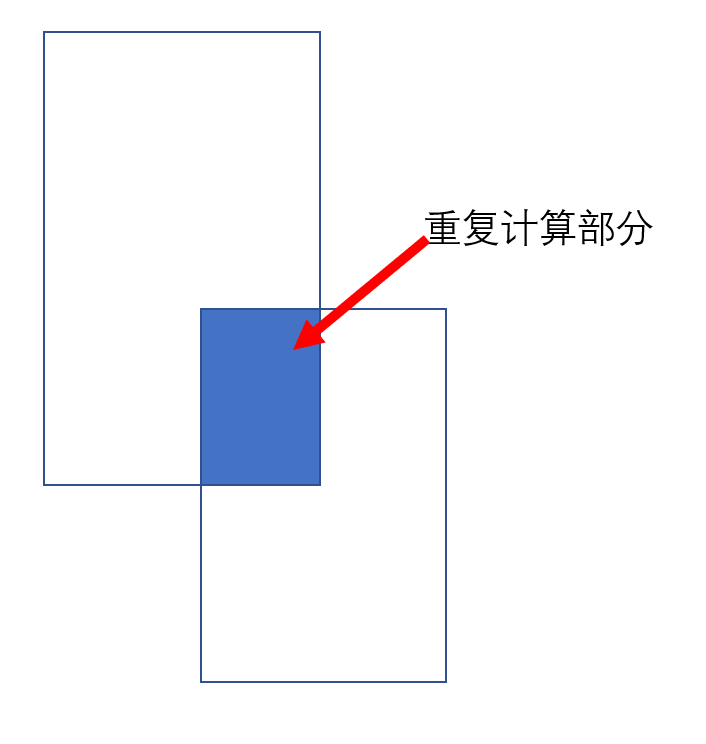
为此, 我们将像素点均摊到它属于的边界框中, 这样就不会重复计算, 如下式:
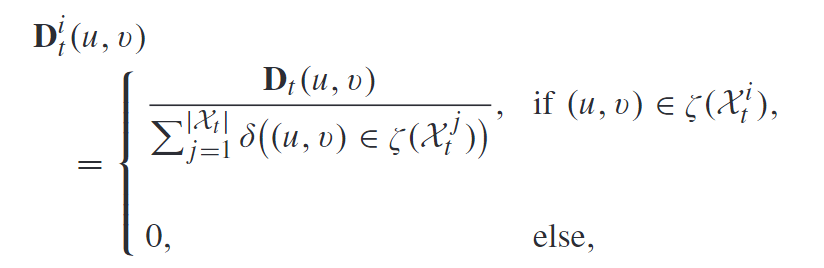
其中:
ξ ( ) \xi() ξ()表示检测框对应的像素区域. δ \delta δ是指示函数. 于是, 对于第 i i i个检测, 我们通过对其中的像素求和计算出个数:
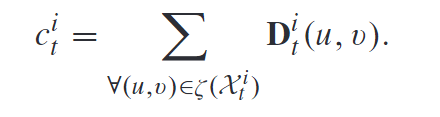
2.2.3 身份-数量平衡
前面说过, 这两个部分得到的结果可能是互相矛盾的. 为此要将二者结合起来. 例如, 对于第 i i i个检测与第 n n n个轨迹的匹配, 如果匹配概率很低, 那不论第i个检测对应的框中包含多少个目标, 第 i i i个检测与第 n n n个轨迹都不太可能匹配; 反之, 如果匹配概率很高, 但第i个检测对应的框中就没有目标, 那也不行. 如果框中包含两个轨迹, 理想的情况是这两个轨迹属于这个框的概率各为0.5, 因此 c t i , n = 0.5 ∗ 2 = 1. c_t^{i,n}=0.5*2=1. cti,n=0.5∗2=1.
于是定义: 第 i i i个检测与第 n n n个轨迹匹配的可能性最终为:
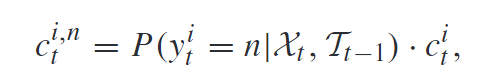
所以 c t i , n c_t^{i,n} cti,n接近1的时候, 代表二者很可能匹配; 为0的时候代表二者不可能匹配.
在训练阶段, 就和真值进行比较就可以了, 采用回归形式的loss function:
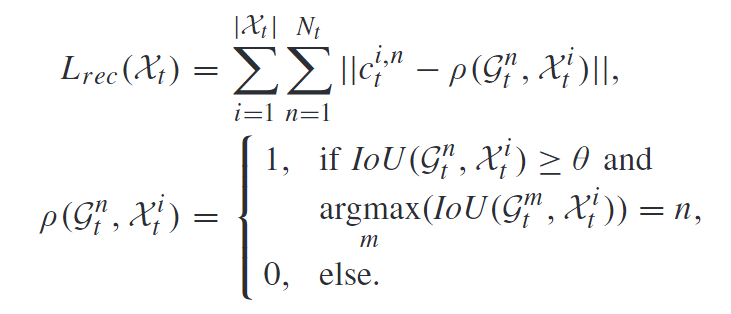
在推理阶段, 如果 c t i , n c_t^{i,n} cti,n大于一定的阈值 α \alpha α, 我们就认为匹配, 因此一个detection bbox匹配轨迹ID的集合定义为:
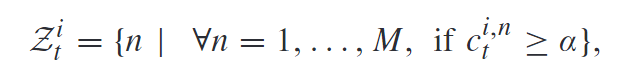
那么无非分为以下几种情况:
- Z t i \mathcal{Z}_t^i Zti为空集, 这说明要么出现了新目标, 要么该检测为FP. 我们通过置信度筛选就可以了.
- Z t i \mathcal{Z}_t^i Zti中只有一个元素, 那么直接更新对应的轨迹
- Z t i \mathcal{Z}_t^i Zti中有多个元素, 分别更新对应的轨迹就可以了.
整个算法流程如下:

3. 评价
该工作的Implementation Details部分没什么可说的, 比较常规.
该工作最大的亮点在于解决一个detection bbox包含多个目标的问题, 采取了一种比较直接的方式, 即直接采用密度估计网络估计bbox中的目标数量, 和概率进行结合. 除此之外, 论文Multiplex Labeling Graph for Near-Online Tracking in Crowded Scenes(IEEE IoTJ 2022, 解读见[论文阅读笔记15]GNN在多目标跟踪中的应用)也是解决这个问题, 但它是通过图结构, 让一个node可以表示多个object实现的, 且那个工作是near-Online, 而本工作是Online的.