文章目录
0. 摘要
在本文中,我们提出了一种使用多头自注意力的混合文本规范化系统。该系统结合了基于规则的模型和神经模型在文本预处理任务的优势。 以前的普通话文本标准化的研究通常使用一组手写规则,这些规则在一般情况下很难改进。 我们提出的系统受最近研究的神经系统的启发,并且在我们内部的新闻语料库中具有更好的性能。本文还包括不同的尝试来处理数据集的不平衡模式分布。 总体而言,该系统的性能在句子水平上提高了1.9%以上。 具有基于规则的文本规范化系统的不同语言可能会采用这种想法。
索引 :文本标准化、多头自注意力、不平衡数据集、普通话
1. 介绍
文本标准化是一个将非标准化词(NSW)转化为朗读形式的词(SFW)以消除歧义的过程。在TTS系统中,文本标准化是很重要的一个环节,用以标准化不可读的数字,符号或者字符,例如"$ “转换为“twenty dollars”, 转换"at”。在文本标准化的时候上下文文本将对歧义的句子起到决定性的作用。例如,上下文将会决定"2019"读作年份还是数字,“10:30”读作时间还是比分。在普通话中,也有一些例子特定于场景的,比如"2"读作 “er” 或者 “liang” , “1” 读作“yı” 或者 “yao”。
目前,基于NSW[1]的传统分类方法,普通话TN任务一般由基于规则的系统来解决,该系统使用关键字和正则表达式来确定歧义词的SFW[2,3]。这些系统通常将NSW分为不同的模式组,如缩略语、数字等,然后再分为子组,如电话号码、年份等,这些子组具有相应的NSW- SFW转换。Zhou[4]和Jia[5]提出了利用最大熵进一步消除模式匹配歧义的系统。对于给定上下文约束的NSW,最大概率对应最大熵。Liou[6]提出了一种基于规则和关键字的TN模块相结合的数据驱动模型系统。第二个模块对围绕关键词前后的单词进行分类,然后训练一个CRF模型,根据分类结果预测NSW的模式。还有一些其他的混合系统[7,8]分别使用NLP模型和规则来帮助规范化TN中的困难情况。
在最近的NLP研究中,序列-序列(sequent -to-sequence, seq2seq)模型在英语和俄语的TN任务中取得了令人瞩目的进展[9,10]。Seq2seq模型通常将序列编码为状态向量,然后将状态向量解码为输出向量,再将其转换为序列。使用bi-LSTM, bi-GRU与注意力的不同的seq2seq模型被提出[10,11]。Zhang和Sproat提出了一个基于上下文的seq2seq模型,该模型使用了滑动窗口和带注意力气[9]的RNN。在这个模型中,双向GRU在编码器和解码器中都被使用,上下文单词被打上" "标签,帮助模型区别NSW和上下文。
然而,seq2seq模型在直接应用于普通话TN任务时有几个缺点。正如在[9]中提到的,直接从seq2seq模型中输出的序列可能会导致不可恢复的错误。模型有时会更改应该保持不变的上下文单词。我们的实验也产生了类似的错误。例如,将“Podnieks, Andrew 2000”改为“Podncourt, Andrew Two Thousand”,将“Podnieks”改为“Podncourt”。这些错误不能被模型本身检测到。在[12]中,规则应用于两个特定的范畴来解决愚蠢的错误,但是这种方法很难应用到所有情况中。普通话中的额另一个挑战是分词,因为词之间没有空间分隔,分词取决于语境。此外,一些NSW可能有一个以上的中文SFW,使得seq2seq模型难以训练。例如,“两千零八年”和“二零零八年”对于SFW “2008年” 都可以被接受。
本文的目的是将基于规则的模型的灵活性和神经模型的性能优点结合起来,以提高在更一般情况下的性能。为了避免seq2seq模型的问题,我们将TN任务考虑为一个多类分类问题,并精心设计了神经模型的模式。
本文的贡献包括以下几个方面。
- 首先,这是第一个已知的普通话TN系统,它使用了一个具有多头部自注意的神经模型。
- 其次,我们提出一个基于规则的模型与神经模型相结合的混合系统。
- 第三,我们尝试了不同的方法来处理TN任务中的不平衡数据集。
论文组织如下:第二部分介绍了该混合系统的详细结构及其训练和推理。在第3节中,将在不同的数据集上评估不同系统配置的性能。第四部分为结论部分。
2. 方法
2.1 基于规则的文本标准化(TN)模型
基于规则的TN模型可以单独处理TN任务,是我们实验的baseline。它的思想与[9]相同,但是有一个更复杂的带有优先级的规则系统。
该模型包含45个不同的组和大约300个模式子组,每个模式使用一个关键字和正则表达式来匹配前面和后面的文本。每个模式还有一个优先级值。在标准化过程中,每个句子作为输入,NSW将被正则表达式匹配。该模型尝试与更长的上下文匹配模式,并缓慢地减少上下文长度,直到找到匹配为止。如果有多个相同长度的模式匹配,则NSW将选择优先级更高的模式。该模型建立在大量的测试数据和bad case的基础上。基于规则的系统的优点是灵活性,因为在出现特殊情况时,可以简单地添加更多的特殊情况,比如新单元。但是,在更一般的情况下提高这个系统的性能成为一个瓶颈。例如,在足球比赛的报告中,如果没有“score”或“game”之类的关键字,它就不能将“1-3”转换为分数。
2.2 本文提出的混合TN模型
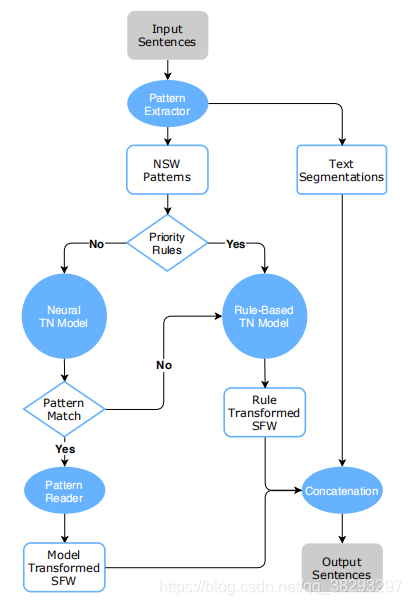
图1 本文提出的混合TN系统的流程图
我们提出了一个混合的TN系统,如图1所示,它结合了基于规则的模型和神经模型。
- 首先使用正则表达式从输入文本中提取NSW。我们只提取与数字和符号相关的NSW,其他NSW比如缩写,将在基于规则的模型中进行处理。
- 然后系统对NSW进行优先级检查,匹配的NSW将被发送到基于规则的模型中。优先级规则包括明确的NSW比如" 911 "和用户定义的字符串。
- 所有剩余的模式都通过神经模型进行分类到其中一个模式组。在模式阅读器中对分类后的NSW进行标准化之前,用正则表达式检查每个分类后的NSW的格式,将“10%”归类为年份等非法的NSW过滤回基于规则的系统。在模式读取器中,每个模式标签都有一个独特的处理函数来执行NSW-SFW转换。
- 最后,将所有归一化后的SFW插入到文本分段中形成输出语句。
对于整个系统,神经模型起主要作用。在我们的黄金集测试中,优先级规则过滤了22.8%的所有模式,而神经模型处理了77.8%,其中有2.2%的模式匹配失败并流回基于规则的模型。
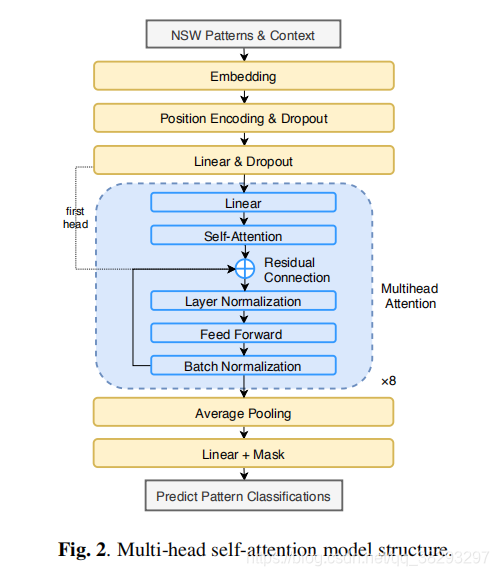
在transformer[13]中提出了多头注意力,它在编码器和解码器中使用自注意力,在编码器和解码器之间使用编解码器注意力。在这种结构的启发下,我们的神经模型采用了多头自注意力,其结构如图2所示。与其他模块如LSTM和GRU相比,self-attention可以有效地并行提取所有上下文的NSW信息,且训练速度快。该神经模型的核心部分类似于transformer的编码器。模型的输入是带有手动标记NSW的句子。
我们在每个NSW周围取一个30个字符的上下文窗口并将其发送到嵌入层。当窗口超过句子范围时使用Padding。经过8头自注意力后,**选择masked softmax 概率最高的 作为分类模式组。**该mask使用正则表达式检查NSW是否包含符号,并过滤非法的符号,如将“12:00”分类为纯数字,这类似于在应用softmax之前的两类分类。
对于损失函数,为了解决不平衡数据集的问题(在3.1节讨论),最后选择的激活函数受以下公式启发:
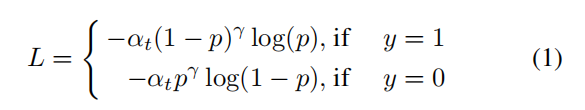
其中,
和
\是超参数,
是经过softmax后的模式概率,
是预测的正确性。在我们的实验室,设置:
2.3 训练和推理
神经网络TN模型由标记句的输入和模式组的输出单独训练。推理是在Fig1中的整个混合TN系统上进行的,其中以带NSW的原始文本为输入,带SFW的文本为输出。
训练数据被分成36个不同的类,每个类都有自己的NSW-SFW转换。数据集的分布与我们内部新闻语料库中的NSW相同,且分布不均衡,这是我们的神经模型面临的挑战之一。下一节将讨论处理不平衡数据集的方法。
3. 实验
3.1 训练数据集
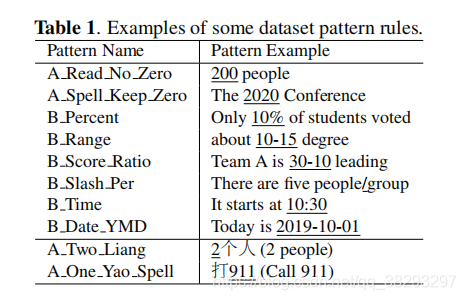
训练数据集包含100,747个模式标签。文本是混有少量英文词的普通话。这些模式是与数字或符号相关的,不包括缩写之类的模式。总共有36个类,表1中列出了一些示例。前8个是带有数字和符号的模式,在单个组中
和
之间可能存在替换。最后两个是语言相关的,汉语中“1”和“2”的读音因语言习惯不同而不同。图3是训练标签分布的饼状图。请注意,前5个模式的标签占大于90%,这使得数据集不平衡。
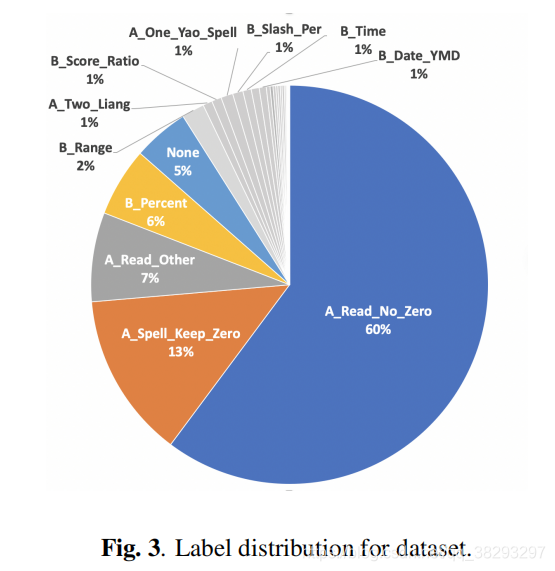
不平衡的数据集对任务来说是一个挑战,因为最上面的模式占用了太多的注意力,所以大多数权重可能是由更简单的模式决定的。我们已经尝试了不同的方法来处理这个问题。第一种方法是使用过采样进行数据扩展。尝试还包括复制低模式比例的文本,将前几个字符替换为窗口中的填充,随机更改数字和移动上下文窗口。另一种方法是在模型中加入损失控制,如2.2中所述。损失函数可以帮助模型关注不同类中较困难的情况,从而减少不平衡数据的影响。实验结果见3.3。
3.2 系统配置
对于句子嵌入,使用预训练的嵌入模型来促进训练。我们使用 word-to-vector(w2v)的模型,在Wikipedia语料库上进行训练,并对训练好的BERT[15]模型进行微调。实验结果见3.3。
实验表明,使用固定的上下文窗口比填充所有句子的最大长度能获得更好的性能。填充1比填充0的性能稍好一些。在推理过程中,一个句子中所有的NSW模式都需要同时处理,才能转换成SFW,保持原有的上下文。
3.3 模型性能
表2对测试集的模式准确率进行了比较7种不同的神经模型设置。模型2-7的配置是与与模型1作比较的:①本文提出的配置; ②用BERT进行微调; ③用0代替1的填充;④将上下文窗口长度30替换为最大句子长度; ⑤用交叉熵(CE)损失代替损失; ⑥去掉mask; ⑦应用数据扩展。
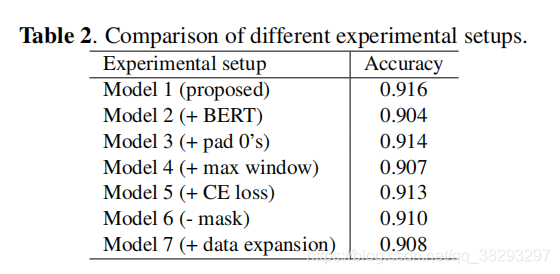
总体而言,w2v模型的性能要优于使用BERT的finetuning。使用了各种BERT模型,但没有一个能达到最高的精度。一个可能的原因是,该模型很容易与训练数据过拟合。结果还表明,尽管模型在低比例模式下具有更好的鲁棒性和性能,但数据扩展并没有带来更好的精度。这是因为模式分布发生了变化,其在最上面的比例模式上的性能略有下降,导致了大量的错误分类。这是一个健壮和高准确率模型之间的折衷。我们选择模型1进行下面的测试,因为黄金集是通过准确性来评估的。
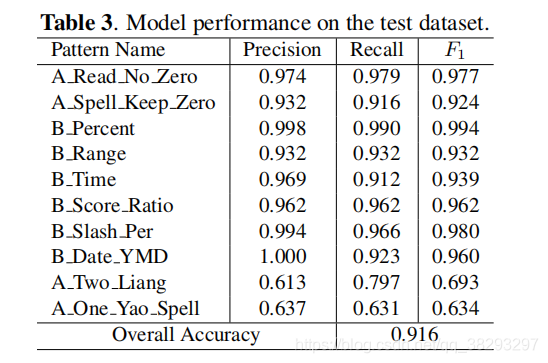
在每个模式组的测试集上,使用准确率、召回率和F1分数(准确率和召回率的调和平均值)对所提出配置的神经模型进行评估。前几的比例模式的结果如表3所示。这个结果可以帮助确定从神经模型中使用哪些预测良好的模式。
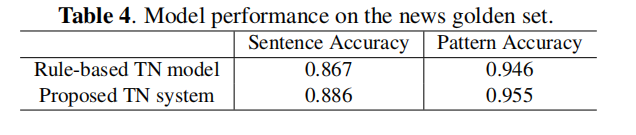
提出的混合TN系统在一组内部含有NSW-SFW对的黄金集上进行了测试。如果转换句和实际句中的任何一个字符不同,就会被认为是错误的。黄金集有67853个句子,每个句子包含1-10个NSW字符串。表4列出了句子和平均模式正确率。在句子层面,准确率提高了1.9%,这表明1000多个句子的正确率提高了。改进主要针对关键词较少的歧义的NSW。混合系统的平均准确率也高于表2中纯数据驱动的神经模型。
4. 结论和展望
在这篇论文中,我们提出了一个使用多头自注意力的混合TN系统用于普通话。该系统旨在利用神经模型的优点,解决高度发展的基于规则的模型的性能瓶颈。该系统主要依赖于神经模型而不是规则。从测试结果来看,该系统将NSW-SFW转换的准确率提高了1.9%以上,仍有进一步提高的潜力。该混合系统结构对其他具有TN规则的语言有一定的借鉴意义,有助于提高其泛化能力。
未来的工作包括模型探索的其他方面。普通话的词语化将取代文字层面的嵌入。将应用Seq2seq模型来帮助用端到端系统替换规则。并补充其他语料库中更多的标记数据进行训练和评估。
