Towards Real-Time Multi-Object Tracking
Abstract
The components of traditional MOT strategies which follows the tracking-by-detection paradigm1:
- detection model
- appearance embedding model
- data association
The shortcomings of traditional MOT strategies:
- poor efficiency
While in this paper, the author proposed a new method to solve the problem which allows detection and appearance embedding to be learned in a shared model (single-shot detector). Further more, the author propose a simple and fast association method.
1 Introduction
MOT—— Predicting trajectories of multiple targets in video sequences.
tracking-by-detection—— SDE2 :
- Detection—— Localize targets. (detector)
- Association. (re-ID model)
- Problem—— Inefficient.
Solution: Integrate the two tasks into a single network (Faster R-CNN).
JDE3
- Training Data: collect six public available datasets on pedestrian validation and person search to form a unified multi-label dataset.
- Architecture: FPN
- Loss: anchor classification, box regression and embedding learning (using task-dependent uncertainty).
- A simple and fast association algorithm.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MErnkqnG-1659351495197)(http://balabo-typora.oss-cn-chengdu.aliyuncs.com/balabo_img/image-20220726143401322.png “comparison”)]
2 Related Work
3 Joint Learning of Detection and Embedding
3.1 Problem Settings
Training dataset:
{ I , B , y } i = 1 N \{I, B, y\}_{i=1}^{N} {
I,B,y}i=1N
Where
I ∈ R c × h × w I\in R^{c\times h\times w} I∈Rc×h×w : image frame,

B ∈ R k × 4 B\in R^{k\times 4} B∈Rk×4: bounding box, where k k k denotes targets,
y ∈ Z k y\in Z^{k} y∈Zk: identity labels.
JDE predict B ^ \hat{B} B^ and F ^ ∈ R k ^ × D \hat{F}\in R^{\hat{k}\times D} F^∈Rk^×D, where D D D is the dimension.
3.2 Architecture Overview
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jPT7wOYD-1659351495198)(http://balabo-typora.oss-cn-chengdu.aliyuncs.com/balabo_img/image-20220726144315571.png “JDE Architecture”)]
Each dense prediction head is the size of ( 6 A + D ) × H × W (6A+D)\times H\times W (6A+D)×H×W.
- bounding box classification: 2 A × H × W 2A\times H\times W 2A×H×W;
- bounding box regression coefficients: 4 A × H × W 4A\times H\times W 4A×H×W;
- embedding: D × H × W D\times H\times W D×H×W.
3.3 Learning to Detect
The detection branch of JDE is similar to the standard RPN except:
- All anchors are set to an aspect of 1: 3;
- IOU>.5 w.r.t. the ground truth ensures a foreground;
- IOU<.4 w.r.t. the ground truth ensures a background.
Loss:
- foreground/background classification loss ℓ α \ell _\alpha ℓα (cross-entropy);
- bounding box regression loss ℓ β \ell_\beta ℓβ (smooth-L1).
3.4 Learning Appearance Embeddings
Triplet loss is abandoned because:
- huge sampling space;
- making training unstable.
Finally use ℓ C E \ell_{CE} ℓCE (cross-entropy loss).
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SLsfTnRP-1659351495198)(http://balabo-typora.oss-cn-chengdu.aliyuncs.com/balabo_img/image-20220726161206339.png “cross-entropy loss”)]
3.5 Automatic Loss Balancing
The total loss can be written as follow:
L total = ∑ i M ∑ j = α , β , γ w j i L j i \mathcal{L}_{\text {total }} = \sum_{i}^{M} \sum_{j = \alpha, \beta, \gamma} w_{j}^{i} \mathcal{L}_{j}^{i} Ltotal =i∑Mj=α,β,γ∑wjiLji
where M M M is the number of prediction heads and w j i w_{j}^{i} wji, i = 1 , . . . , M i=1,...,M i=1,...,M, j = α , β , γ j=\alpha,\beta,\gamma j=α,β,γ are loss weights.
Simple ways to determine the loss weights:
- Let w α i = w β i w_\alpha^i=w_\beta^i wαi=wβi.
-
Let w α / γ / β 1 = . . . = w α / γ / β M w_{\alpha/\gamma/\beta}^1=...=w_{\alpha/\gamma/\beta}^M wα/γ/β1=...=wα/γ/βM.
-
Search for the remaining two independent loss weights for the best performance.
-
task-independent uncertainty:
L total = ∑ i M ∑ j = α , β , γ w j i L j i L total = ∑ i M ∑ j = α , β , γ 1 2 ( 1 e s j i L j i + s j i ) \mathcal{L}_{\text {total }} = \sum_{i}^{M} \sum_{j = \alpha, \beta, \gamma} w_{j}^{i} \mathcal{L}_{j}^{i}\mathcal{L}_{\text {total }}=\sum_{i}^{M} \sum_{j=\alpha, \beta, \gamma} \frac{1}{2}\left(\frac{1}{e^{s_{j}^{i}}} \mathcal{L}_{j}^{i}+s_{j}^{i}\right) Ltotal =i∑Mj=α,β,γ∑wjiLjiLtotal =i∑Mj=α,β,γ∑21(esji1Lji+sji)Task-independent Uncertainty:
Article: “Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”
multi-task loss: L t o t a l = ∑ i w i L i \mathcal L_{total}=\sum_{i}w_i\mathcal L_i Ltotal=∑iwiLi
Model performance is extremely sensitive to weight selection.
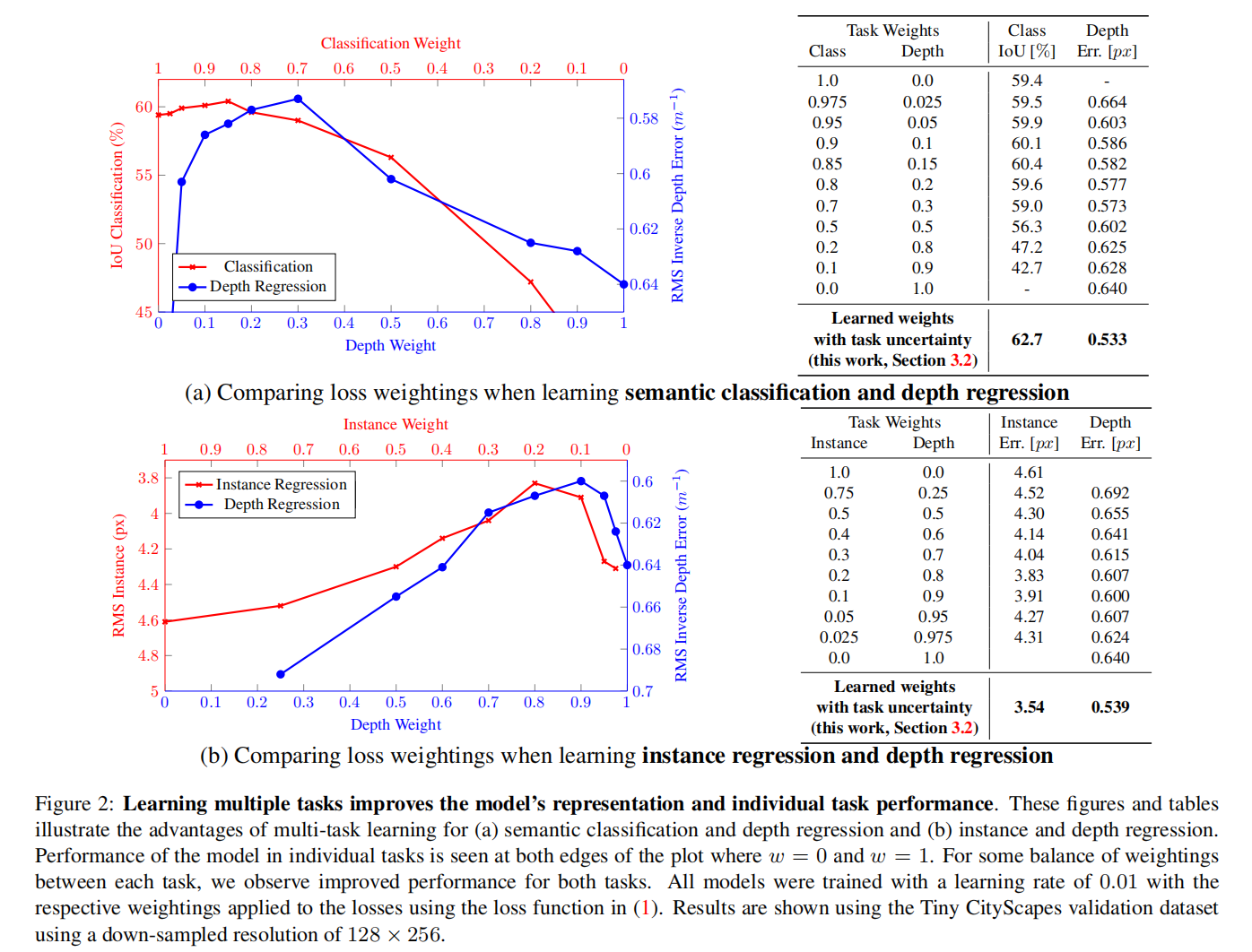
In Bayesian modelling, there are two main types of uncertainty:
- Epistemic4 uncertainty: Due to lack of training data.
- Aleatoric5 uncertainty: Aleatoric uncertainty can be explained away with theability to observe all explanatory variables6 with increasing precision. It can be divided into:
Multi-task loss function based on maximising the Gaussian likelihood with homoscedastic uncertainty:
- f W ( x ) → f^W(x)\to fW(x)→ output of a neural network with weights W W W on input x x x
- For regression task: p ( y ∣ f W ( x ) ) = N ( f W ( x ) , σ 2 ) p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=\mathcal{N}\left(\mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma^{2}\right) p(y∣fW(x))=N(fW(x),σ2). The mean is given by the model out put.
- For classification task: p ( y ∣ f W ( x ) = s o f t m a x ( f W ( x ) ) p(\mathbf y\mid \mathbf f^W(\mathbf x)=\mathbf{softmax}(\mathbf f^W(\mathbf x)) p(y∣fW(x)=softmax(fW(x))
- In the case of multiple model outputs, we can factorise over the outputs: p ( y 1 , … , y K ∣ f W ( x ) ) = p ( y 1 ∣ f W ( x ) ) … p ( y K ∣ f W ( x ) ) p\left(\mathbf{y}_{1}, \ldots, \mathbf{y}_{K} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=p\left(\mathbf{y}_{1} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \ldots p\left(\mathbf{y}_{K} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) p(y1,…,yK∣fW(x))=p(y1∣fW(x))…p(yK∣fW(x)). y n y_n yn means outputs of different tasks.
- Scaled version of Softmax: p ( y ∣ f W ( x ) , σ ) = Softmax ( 1 σ 2 f W ( x ) ) p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right)=\operatorname{Softmax}\left(\frac{1}{\sigma^{2}} \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) p(y∣fW(x),σ)=Softmax(σ21fW(x))
- The log likelihood: log p ( y = c ∣ f W ( x ) , σ ) = 1 σ 2 f c W ( x ) − log ∑ c ′ exp ( 1 σ 2 f c ′ W ( x ) ) \log p\left(\mathbf{y}=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right)=\frac{1}{\sigma^{2}} f_{c}^{\mathbf{W}}(\mathbf{x}) -\log \sum_{c^{\prime}} \exp \left(\frac{1}{\sigma^{2}} f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right) logp(y=c∣fW(x),σ)=σ21fcW(x)−log∑c′exp(σ21fc′W(x))
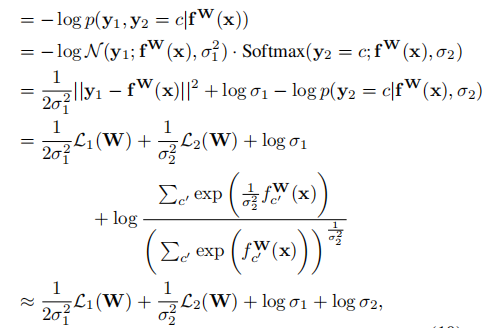
3.6 Online Association
A tracklet is described with an appearance state e i e_i ei and a motion state m i = ( x , y , γ , h , x ˙ , y ˙ , γ ˙ , h ˙ ) m_i=(x,y,\gamma,h,\dot x,\dot y,\dot \gamma,\dot h) mi=(x,y,γ,h,x˙,y˙,γ˙,h˙):
- x , y x,y x,y: bounding box center position
- h h h: bounding box height
- γ \gamma γ: bounding box ratio
- x ˙ \dot x x˙: velocity of x x x
For an incoming frame, compute motion affinity matrix A m A_m Am and appearance affinity matrix A e A_e Ae using cosine similarity and Mahalanobis similarity respectively.
linear assignment:
- Hungarian algorithm:
- cost matrix: C = λ A e + ( 1 − λ ) A m C=\lambda A_e+(1-\lambda)A_m C=λAe+(1−λ)Am
Matched m i m_i mi is updated by Kalman filter, and e i e_i ei is updated by e i t = α e i t − 1 + ( 1 − α ) f i t e_{i}^{t}=\alpha e_{i}^{t-1}+(1-\alpha) f_{i}^{t} eit=αeit−1+(1−α)fit
Finally observations that are not assigned to any tracklets are initialized as new tracklets if they consecutively appear in 2 frames. A tracklet is terminated if it is not updated in the most current 30 frames.