目录
Abstract
In this paper, we employed a reinforcement learning method based on the policy search algorithm, call Guided Policy Search, to learn policies for the grasping problem.
用这个Guided Policy Search去学习抓取问题。
The goal was to evaluate if policies trained solely using sets of primitive shaped objects, can still achieve the task of grasping objects of more complex shapes.
也就是用简单的、原始的物体进行训练模型
是否能获得更复杂形状下好的抓取表现
也就是这篇文章主要测试模型的泛化性能
Additionally, a robustness test was conducted to show that the visual component of the policy helps to guide the system when there is an error in the estimation of the target object pose.
此外,还进行了鲁棒性测试,表明当目标对象姿态的估计存在误差时,策略的视觉分量有助于指导系统。
INTRODUCTION
对于每个组件,抓取/装配计划器的任务之一是根据每个特定的操作任务提供最合适的抓取姿势。
然而,为了计算抓取姿势,规划器需要一个精确的组件模型。
这一要求使计划人员无法处理产品组件形状的变化或工作空间中的变化。
To cope with this problem, we propose a novel approach where the assembly planner itself is solved by approximating the model’s shape using a set of primitive shapes, and at the time of performing the grasping, the shape difference between each part and its approximated model is solved by using reinforcement learning.
为了解决这个问题,我们提出一种新的方法,装配规划师本身使用一组原始形状解决模型近似。执行的时候,每个部分之间的形状差异及其近似模型解决通过使用强化学习。
We used a policy search algorithm called Guided Policy Search. The algorithm learns a policy to control a robotic arm based on visual feedback and the grasping posture.
视觉反馈、抓取位姿估计
In our method, we propose representing the policy using a convolutional neural network that accepts an image, a grasping posture, and the robot configuration to control the robot arm.
卷积神经网络解决问题
输入是:一张图片、一个抓取位姿(关节和速度参数)和机械臂的控制参数
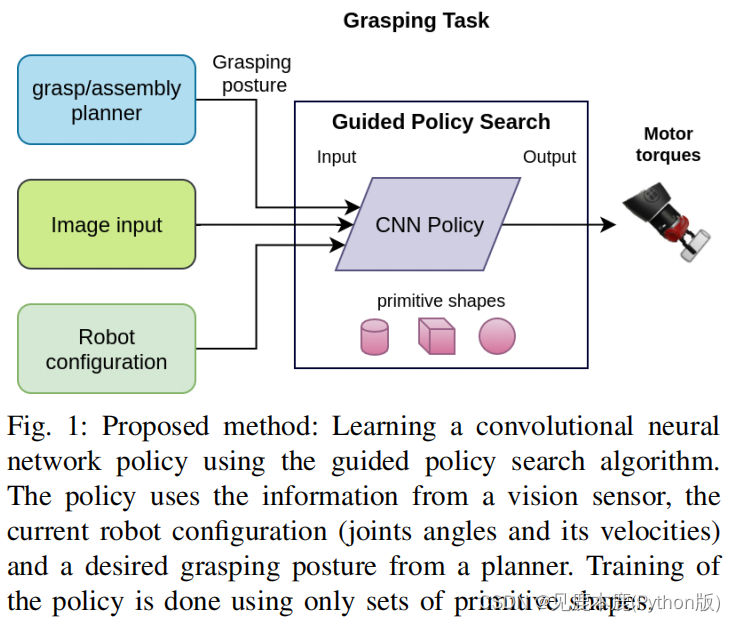
RELATED WORK
Most of these works use manual engineered representations to design specialized policies classes or features. However, the high dimensional complexity of robotic systems and unstructured environments demand additional constraints to the general reinforcement learning formulation to enable its application in the real world.
这些工作大多使用手工设计的表示形式来设计专门的策略类或特性。
然而,机器人系统和非结构化环境的高维复杂性需要对一般强化学习公式的额外约束,以使其在现实世界中的应用。
Moreover, end-to-end learning approaches have been proposed where the system learns a joint model using vision input in a data-driven manner, such that, after collecting thousands of samples of successful and unsuccessful manipulations, the robot learn a model which controls the manipulation directly from input images.
此外,还提出了端到端学习方法,其中系统以数据驱动的方式使用视觉输入学习联合模型,这样,在收集了数千个成功和不成功操作的样本后,机器人从输入图像直接控制操作的模型。
| Author | Work | Paper |
|---|---|---|
| Pinto & Gupta | trained a convolutional neural network (CNN) for the task of predicting grasp locations by collecting a dataset of 50K data points and over 700 hours of robot grasping attempts needed to create the dataset. | L. Pinto and A. Gupta, “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours,” in Robotics and Automation (ICRA), 2016 IEEE International Conference on, pp. 3406–3413, IEEE, 2016. |
| Levine et al. | trained a deep CNN to predict the probability that the gripper will result in successful grasps using a dataset of 900K grasp attempts to learn hand-eye coordination for grasping; over two months and eight robots working simultaneously were used to collect this dataset. | S. Levine, P. Pastor, A. Krizhevsky, and D. Quillen, “Learning hand-eye coordination for robotic grasping with large-scale data collection,” in International Symposium on Experimental Robotics, pp. 173–184, Springer, 2016. |
- reduce the burden of manual feature engineering
- typically required a massive amount of training data
- not practical for application.
Guided policy search (GPS) methods seek to address this challenge by decomposing the policy search into trajectory optimization and supervised learning of a general high-dimensional policy.
将策略搜索分解为轨迹优化和一般高维策略的监督学习
这些算法将策略搜索问题转化为一个有监督的学习问题,并由简单的轨迹中心强化学习方法提供监督。
这些以轨迹为中心的方法不是直接训练策略,而是提供了从多个不同的实例中训练非线性深度神经网络策略的监督。
Thus, from an initial policy -that can be a random Gaussian controller- the GPS method iterates from drawing samples from the current policy, using this samples to fit the dynamics that are used to improve the trajectory distribution, and training the policy using the trajectories as training data.
因此,从一个初始策略——可以是一个随机高斯控制器——GPS方法迭代,从当前策略中抽取样本,使用这个样本来拟合用于改善轨迹分布的动力学,并使用轨迹作为训练数据来训练策略。
On the other hand, our method calculates a grasping posture of the primitive shaped model, and the difference between the actual object and its primitive shaped model is solved by using the reinforcement learning.
另一方面,该方法计算了原始形状模型的抓取姿势,并通过强化学习的方法求解了实际对象与原始形状模型之间的差异。
PROBLEM FORMULATION
We consider the robot manipulation task of grasping a target object using a robot arm equipped with a simple parallel gripper.
实现的方式是:机械臂+并行的夹具
- a grasp/assembly planner: be used to compute the desired grasping posture of the target object. 抓取规划者:可以计算抓取目标的机械臂/夹具的位姿
- the pose of the object is known in order to compute the grasping posture. 为了计算抓取物的位姿,物体的位置是已知的
- error in this pose estimation can be mitigated thanks to the visual component of the policy 对于规划者估计出来的实际物体的位姿存在误差问题,可以通过这个策略的视觉组件减小误差
- The grasping posture is computed by approximating the object shape using a set of shape primitives. 采用一组原始形状和动作实现物体形状的近似。
A. Guided Policy Search
In policy search algorithms, the goal is to learn a policy π ( u t , o t ) \pi(u_{t}, o_{t}) π(ut,ot), for taking actions u t u_{t} ut conditioned on the observations o t o_{t} ot to control a dynamical system. Given an stochastic dynamics p ( x t + 1 ∣ x t , u t ) p(x_{t+1}|x_{t}, u_{t}) p(xt+1∣xt,ut) and a cost function l ( x , u ) l(x, u) l(x,u), the goal is to minimize the expected cost under the policy’s trajectory distribution, ∑ t = 1 T l ( x t , u t ) \sum_{t=1}^{T} l(x_{t}, u_{t}) ∑t=1Tl(xt,ut).
In guided policy search, this optimization problem is addressed by dividing the problem into two components: a trajectory optimization part and a supervised learning one.
一个是轨迹优化部分,一个是监督学习部分
These samples are store as trajectories of the form { x t , u t , x t + 1 } \{x_{t}, u_{t}, x_{t+1}\} {
xt,ut,xt+1}.
也就是说,学习的轨迹也就是深度强化学习里面通俗的“一条经验”
Then, in the trajectory optimization part, learn a linear controller using iterative linear quadratic Gaussian (iLQG) algorithm, the optimization is constrained to be closed to the trajectory described by the policy.
然后,在轨迹优化部分,利用迭代线性二次高斯(iLQG)算法学习线性控制器,将优化约束为接近该策略所描述的轨迹。
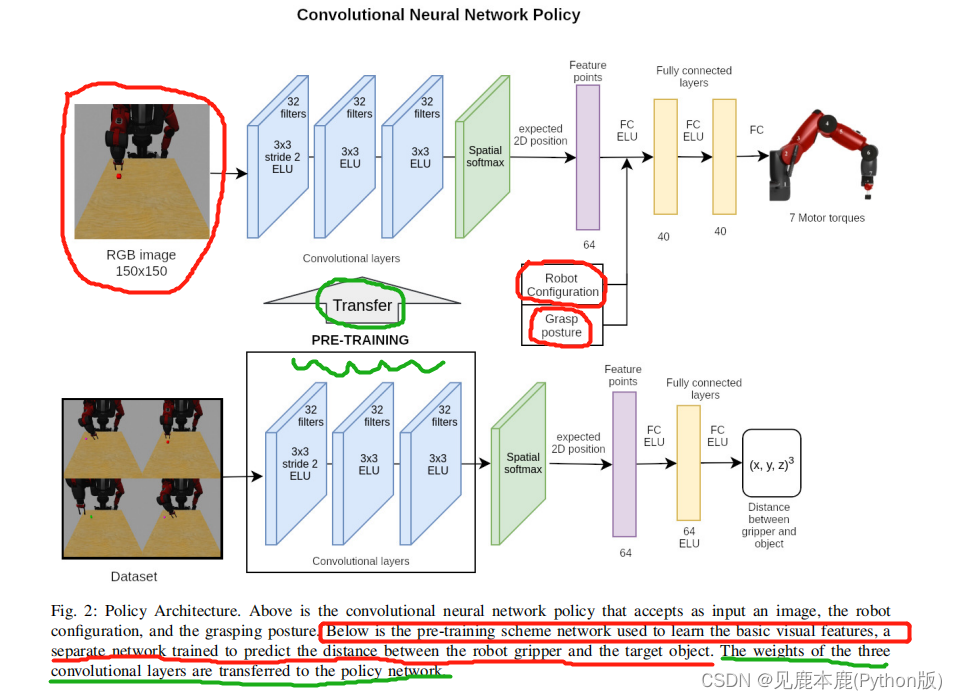
然而,在我们的工作中,我们切换到算法镜像下降引导策略搜索(MDGPS)。该方法比BADMM的性能更好,且对超参数的人工调整需要大大减少。我们的实现是基于开源的项目GPS。
B. Convolutional Neural Network Policy
该网络包含三个卷积层,每个卷积层由32个滤波器组成,然后是一个空间Softmax,描述从输入图像中提取的视觉特征。然后将视觉特征连接起来,通过机器人的配置和抓握姿势,然后通过2个完全连接的层,每一层为40个单元,以产生关节力矩。
在视觉组件的情况下,我们训练了一个单独的卷积神经网络来预测从输入图像中夹持器位置和目标位置之间的距离。
- 我们收集了大约2000张图像的数据集,其中包含原始形状的物体和不同任意位置的机械臂。
- 我们构造一个CNN,与前面提到的结构相同。空间softmax层,和完全连接层,其次是一个指数线性单元(ELU)激活函数产生的预测位置(一个数组6值),我们发现这个激活函数执行比整流器线性单元(RELU)性能更好。
- 第一层的滤波器用在ImageNet分类数据集上训练的初始空间Inception-v3模型的权重进行初始化。
- 夹具和对象的位置都被编码为3个点。
- 这个CNN的训练是使用Adam优化器进行批优化的

C. Cost function
In this work, the cost function for the grasping task was defined in terms of the distance from the gripper to the target object and then a reward is given to the robot if the grasp is successful.
l ( x t , u t ) = ω l 2 d t 2 + ω l o g l o g ( d t 2 + α ) + ω u ∣ ∣ u t ∣ ∣ 2 + ω g C g r p l(x_{t},u_{t})=\omega_{l_{2}}d_{t}^{2}+\omega_{log}log(d_{t}^{2}+\alpha)+\omega_{u}||u_{t}||^{2}+\omega_{g}C_{grp} l(xt,ut)=ωl2dt2+ωloglog(dt2+α)+ωu∣∣ut∣∣2+ωgCgrp
d t → d_{t} \rightarrow dt→ 端部执行器空间中的三个点之间的距离
the weights are set to ω l 1 = 1.0 , ω l 2 = 10.0 , ω u = 1.0 , a n d ω g = 1.0 \omega_{l_{1}} = 1.0, \omega_{l_{2}} = 10.0, \omega_{u} = 1.0, and \omega_{g} = 1.0 ωl1=1.0,ωl2=10.0,ωu=1.0,andωg=1.0.
- 二次项鼓励在目标较远时向目标移动;
- 对数项鼓励将其精确地放置在目标位置;
- 涉及动作 u t u_{t} ut的项被用来鼓励智能体去寻找一个高效的轨迹;
- C g r a s h C_{grash} Cgrash项被定义为成功抓取的奖励,该奖励只在每一episode的最后一step给予。
C g r a s p = { − 10 , i f g r a s p i s s u c c e s s f u l . 1 , o t h e r s C_{grasp} = \begin{cases} -10,&if \ grasp \ is \ successful. \\ 1,&others \end{cases} Cgrasp={
−10,1,if grasp is successful.others
如果在机器人尝试抓握并将手臂恢复到初始位置后,物体仍然被机器人抓握住,则认为抓取成功。
EXPERIMENT AND RESULTS
A. Parameters
所有的实验都是在Gazebo模拟器上的一个模拟的Baxter机器人上进行的。
该机器人通过扭矩控制被控制在40hz。
该机器人的状态被定义为如下。
x = [ q q ˙ e e f e e ˙ f v f ] x= \begin{bmatrix} q \\ \dot q \\ eef \\ e \dot e f \\ vf \end{bmatrix} x=⎣⎢⎢⎢⎢⎡qq˙eefee˙fvf⎦⎥⎥⎥⎥⎤
q → q \rightarrow q→ 机器人的关节角,Baxter右臂的七个关节角
e e f → eef \rightarrow eef→ 当前末端执行器姿态和抓取姿态之间的差异表示,其中 g p gp gp是任何给定时间的当前终端姿势。
该状态还包括 v f vf vf,即通过CNN层输入大小为 150 × 150 × 3 150 \times 150 \times 3 150×150×3 的RBG图像中提取的视觉特征。
照相机在每次实验中都保持固定状态。每集的时长为100步。
B. Generalization
考虑训练的对象是圆柱体、立方体和球体。
对于训练,每项策略都是15次迭代的运动技能预训练和3次迭代的全面训练的结果
当涉及到两种物体同时存在的时候,一半的抽样用于一个物体,另一半的抽样用于另一个物体进行训练。
在测试中,这些策略在每个目标原始形状的物体上执行,此外,它们还对在任何训练中都没有看到的新物体进行了测试:一只鸭子、一个坚果和一个机械部件。
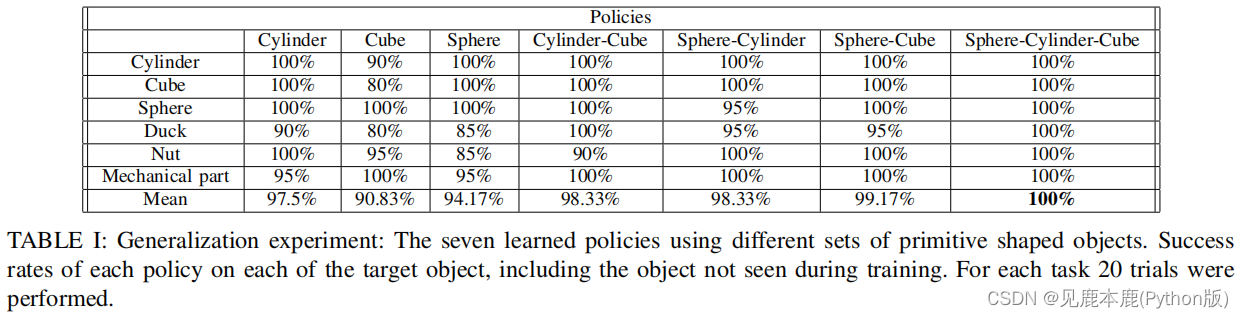
似乎这些物体的径向对称形状使策略更容易实现把握。
在使用立方体训练策略的情况下,夹持器需要以特定的方向正确地接近立方体才能成功,这使任务更难完成。
另一方面,对于使用不同形状集进行训练的策略,该算法能够更好地捕获所有训练对象的共同特征。
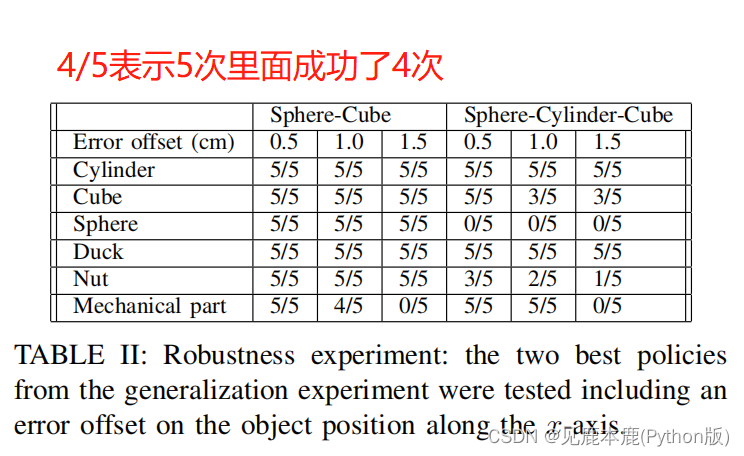
C. Robustness
目的是评估基于视觉成分的策略如何适应的目标姿态估计的误差。
该测试包括输入具有抓取姿势的策略,其中包括目标物体实际位置的误差偏移。
原因:学习到的策略不仅依赖于给定的抓取姿势,还依赖于视觉输入,因此尽管物体姿态估计存在误差,但仍然可以实现对物体的抓取。
CONCLUSION
然而,在未来,我们计划扩展这种方法,以实现抓取任务的策略,对各种抓取姿势更灵活,其中成功的抓取是根据所要求的抓取姿势进行评估的。