1. 摘要
本文提出了一种新颖的多类多目标跟踪(MCMOT)框架,通过组合检测响应和变点检测(CPD)算法来进行无限类多目标跟踪。该框架的效果优于当前最先进的视频跟踪技术。
检测响应:用CNN-based的object detector和基于KLT(Lucas-Kanede Tracker)的motion detector来计算the likelihoodsof foreground regions,以此作为不同类别目标的检测响应。
CPD:CPD模型用于观察由遮挡或者draft引起的突变状况。
基准数据集:ImageNet VID 和 MOT Benchmark 2016。
2. MCMOT框架
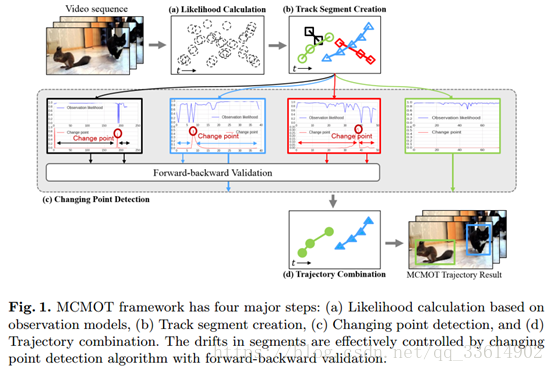
MCMOT算法总结:
首先,在实体状态转换步骤中执行对象的出现和消失分配。其次,使用数据驱动的MCMC采样步骤构建中间轨道段。然后,通过变化点检测算法监测可能发生的漂移。最后组合出轨迹。
上图所示中的step1在observation model中详细介绍。
2.1 观察模型
集合了多种特征的目标检测器来计算目标的observation likelihood,最后估计出目标的类别和精确位置。
本节中定义observation model(observation likelihood)P(Z_t |X_t) 。追踪物的observation likelihood需要估计物体类别和精确的位置。MCMOT集合不同特征的object detectors来精确的计算observationlikelihood。用存在和不存在可能性的比率来衡量。由于无法测量non-existenceset的likelihood采用likelihood模型的soft max函数f(.),如下


使用的detectors有deep featurebased globe object detector(GT)、deep featurebased local object detector(LT)、colordetector(CT)、motion detector(MT):
(1) GT:使用基于分层数据模型(HDM)的基于深度特征的object detector。
(2) LT:通过使用可靠的轨迹段微调基于深度特征的object detector,可以最小化由于falsenegative造成的问题。
(3) CT:通过使用Bhattacharyya距离来计算observedappearance model和target之间的相似度得分。Bhattacharyya距离基于bounding box的RGB颜色直方图。
(4) MT(motion detector):使用基于KLT的motion detector 检测对象的存在。
2.2 创建track segment
下面将讨论数据驱动MCMC采样细节,以及实体状态转换。
数据驱动的MCMC采样
在基于MCMC的抽样中,proposal density function很重要,因为它影响固定分布的马尔可夫链的构建。给定场景粒子t时刻的状态,可以根据提议密度函数来建议粒子t+1时刻的状态。本文中采用数据驱动的提议密度使马尔可夫链有更好的接受率。本文的MCMOT提出了一个新的状态,其中混合了状态移动以确保运动平稳性,如下所示:

其中λ_1+λ_2=1。第一项来自运动模型,第二项来自探测器集合,并使用来自对象id的所有探测的最接近结果。
估计实力状态转换

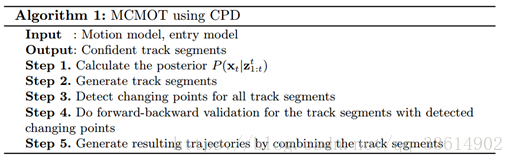
2.3 变点检测

首先变点检测算法会计算出一个CPD分数,若这个分数超过阈值,则要经过前向-后向验证计算FB error,若此值超过阈值,则排除所对应的tracksegment。最后整合留下的confident segments成轨迹。
FB error是根据验证点的初始点和终点之间欧氏距离来度量的,公式如下:

3 实验结果
3.1 实验细节
如何构建全局和局部目标检测器:使用ImageNet分类数据集上预训练的公共可用16层VGG-Net和ResNet,然后用ImageNet挑战检测数据集进行微调,其中迭代次数为280k、学习率为0.001。
使用RPN生成region proposal。
变化点阈值设置为0.3
3.2 CPD分析
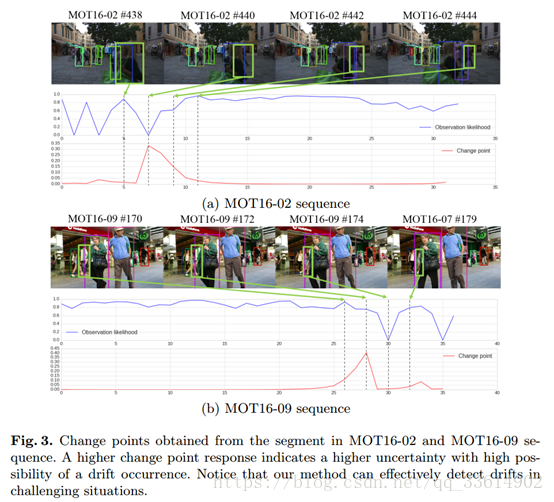
如图,红线对应的纵坐标的值表示变换点检测的分数,分数越高,发生漂移的可能性就越大,若大于0.3则认为发生了漂移。
3.3 ImageNet VID 评估
对于ImageNet VID训练/验证实验,所有训练和测试图像按600像素缩放为图像最短边的长度。这个值被选中,以便VGG16或ResNet在微调期间适合GPU内存。
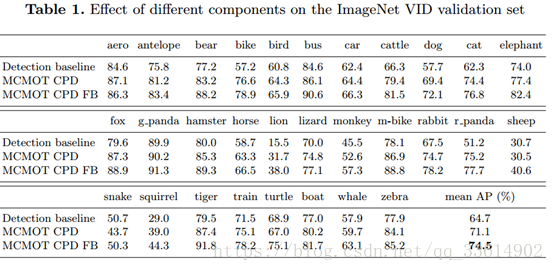
表一的结果显示,在mean average precision指标上本文提出的MCMOT CPDFB比检测基线高出了9.8%,达到了74.5%。
本文此结果主要是由于MCMOT通过使用CPD来构建高精度片段的方法。简言之,CPD是本文的最大亮点。

表二是MCMOT和其他先进方法在mAP指标上的比较结果。
3.4 MOT Benchmark 2016评估
对于MOT 2016的实验,所有训练和测试图像按800像素缩放为图像最短边的长度。选择较大的值是因为行人边界框大小小于ImageNet VID。
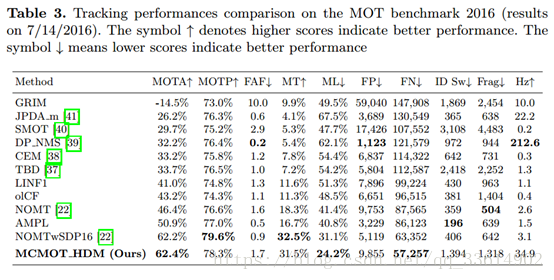
表3. 2016年MOT基准测试的跟踪性能比较。符号表示较高的分数表示较好的表现,符号表示较低的分数表示较好的表现。表3总结了测试视频序列中MCMOT和其他技术水平的评估指标。

图5显示了测试序列中MCMOT跟踪结果的例子。
4 总结
本文提出了一种新颖的多类多目标跟踪框架。该框架超越了ImageNet VID和MOT基准2016年的最新成果.MCMOT根据检测响应延伸了无限的对象类关联。CPD模型用于观察由漂移引起的突然或异常变化。采用基于KLT的运动检测器和基于CNN的目标检测器的集合来计算可能性。未来的研究方向是处理MCMOT结构和轨道段之间的身份映射问题的优化问题。