Few-Shot Table-to-Text Generation with Prefix-Controlled Generator

文章目录
会议:COLING2022
任务:文本生成(table-to-text)
原文:链接
Abstract
本文针对少样本场景下的Table-to-Text任务,提出了Prefix-Controlled Generator:基于少样本的提示学习方法。
-
该方法为PLM预置一个任务特定的Prefix,使表结构更好地拟合预训练的输入。
-
另外,该方法生成一个输入特定的Prefix(Input-Specific Prefix)来控制生成文本的事实内容和语序。
本文的方法在Wikibio数据集的不同域上的自动评估和人工评估都显示出比baseline方法有实质性的提升。
Motivation
-
table-to-text标注数据稀少;
-
由于PLMs的不可控性,容易生成幻觉内容;
-
表与序列之间的拓扑差异也很少被研究;
-
使用少量样本进行微调可能导致过拟合和灾难性遗忘。
-
已有工作都利用表格输入进行自由文本生成,忽略了内容规划对生成文本忠实度的重要性;
Table-to-Text存在两个主要挑战:
-
表和序列输入之间的拓扑结构差异;
-
模型从表中选择和重新排列事实内容的能力。
Methodology
预训练-提示的方法,使得PLM适应下游任务而不需要进行微调,该范式更适合于小样本和零样本的场景。Prefix-Tuning通过优化Prefix,冻结语言模型的参数,以充分利用其在预训练阶段学习到的先验知识。
为了应对两大挑战,本文遵从“Pre-train and prompt”的范式,提出了Prefix-Controlled Generator,即PCG,一个有两类Prefix Tokens的端到端生成框架。
两类Prefix Token包括:
-
task-specific prefix:弥合表和单词序列之间的拓扑结构鸿沟;我的理解是是为了让prefix学习到如何适配语言模型的下游任务输入形式,因为本文的intuition提到,在模板生成的句子前面添加提示可以使其成为整个输入的附件,而使模型更加关心提示部分如:“summarize the following table:”,以此来隐式弥合预训练的序列输入形式和表格结构之间的差异。
基本遵循了Prefix-Tuning的想法来设计Task-specific Prefix,但是做了两个修改:
- 使用任务相关的单词来初始化Prefix,以更好地线性化表格输入;
- 在注意力层和前馈神经网络层并行添加了一个可扩展的并行适配器Scaled Parallel Adapters来改善Prefix-Tuning的瓶颈。
-
input-specific prefix:规划表格的事实内容和槽位顺序。
设计这个Prefix的目的是期望它能给模型提示哪些键值对应该被选择(事实内容),以及他们应该按照什么顺序排列。因此,我们提出了一个槽位对齐(slot-aligned)的内容规划器(Content Planner)来选择标准摘要中出现的键(Key),并根据摘要中出现的顺序将他们进行排序。该设计聚焦于通过内容规划在提高生成文本的保真度和词序的正确性。

如图所示,我们希望ContentPlanner生成一个词序列:“fullname name birth_date birth_place position currentclub”,该词序列表明所有表示标准摘要中出现的所有键及其值的出现顺序。这个词序列将作为Hard prompts输入到PLM中。
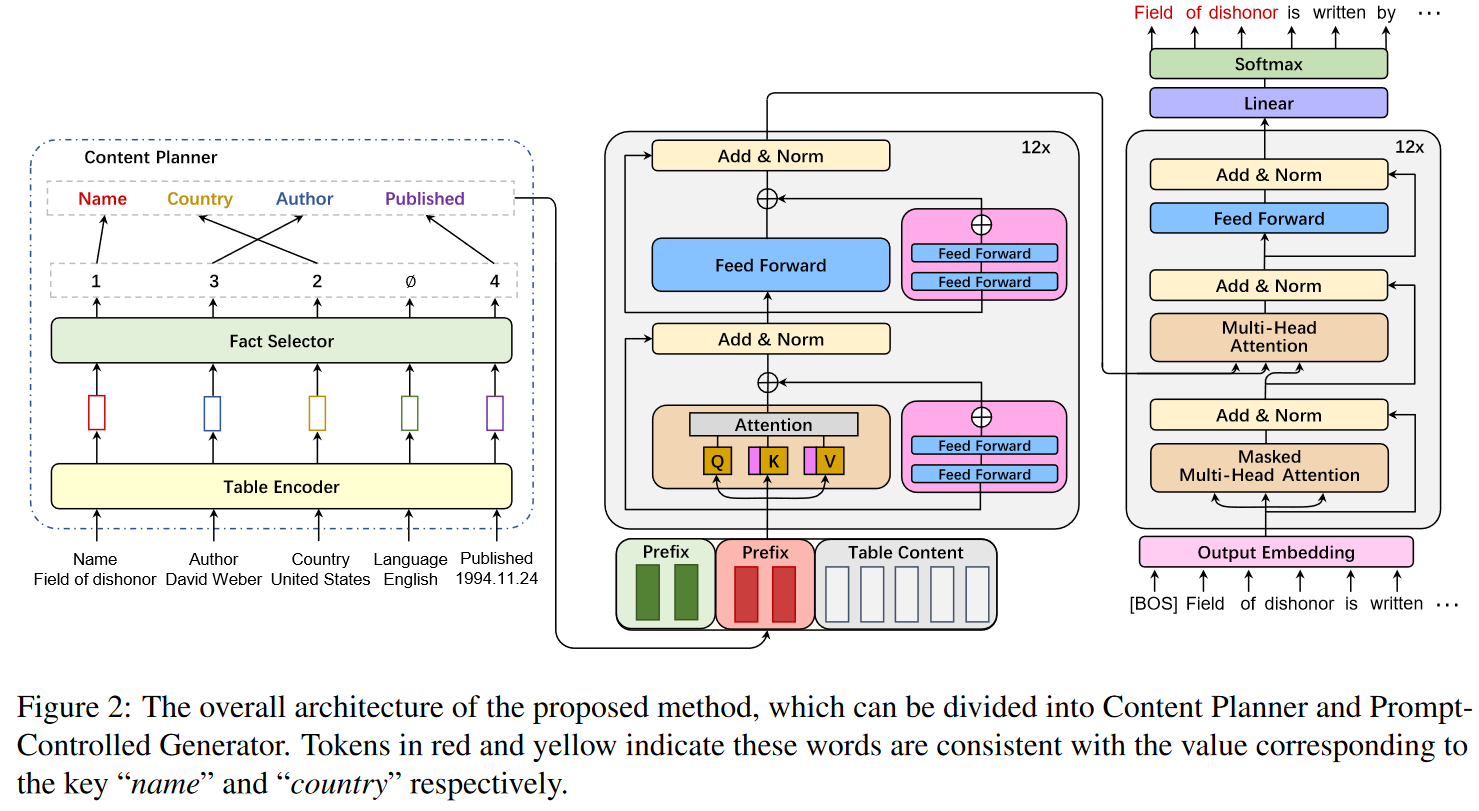
模型结构图:
Intuition
·在少样本的table-to-text生成任务中引入prompt的intuition是prompt-tuning有效解决了灾难性遗忘问题。因为该任务需要具备对表格内容的理解能力,所有我们希望在保持PLMs的先验知识的同时微调下游任务。这正是提示学习所具备的能力。
过去的研究工作发现,表格形式转换起到了关键作用。但是,拼接键值对作为模板这一方式,违背了提示学习的方法,不适配于语言模型预训练的输入。引入Prefix,隐式地来弥合表格结构和序列输入之间的拓扑差异。
Content Planner
Content Planner旨在生成输入特定的提示语(input-specific prompts),从事实内容和语序两方面指导生成过程。因为本文研究的是少样本场景下的table-to-text生成,因此模型力求简单,所以设计了两个结构简单的模块。
Table Encoder
结构:BiLSTM
对表格的每个键值对进行编码,为每个表格的槽生成一个表征。对于每个包含键值对的表槽。对于K和V的嵌入,计算方式为:

m表示K和V各自的单词长度,该式子表明每个槽(即每个键值对)的嵌入表示K和V对各自每个单词的词嵌入进行求和然后去平均,最后使用一个超参数对K和V的嵌入加权求和。并且使用预训练的Roberta词嵌入来初始化词嵌入矩阵。最后将得到的槽嵌入输入BiLSTM获得双向表征,将二者拼接作为最终表征。
Fact Selector
结构:线性链CRF+feed-forward
这个模块选择在标准描述(ground-truth)中出现过的Key-Value Pairs,然后根据它们在摘要中的出现顺序重新排序。
这里是将位置预测视为序列标注任务,输入为Key-Value对,输出的标注序列为每个Key-Value槽在生成的文本中应该出现的相对位置。 W C R F l i W^{l_i}_{CRF} WCRFli即节点特征函数, M l i − 1 , l i M_{l_{i−1},l_i} Mli−1,li即转移函数

学习目标定义为:
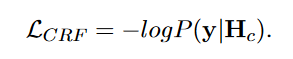
标注的Key-Value顺序从ground-truth中通过键值匹配然后根据他们的位置排序获得。推理时,使用一阶Viterbi算法解码获得最佳序列。如图2,输出为 1 , 3 , 2 , ∅ , 4 1,3,2,∅,4 1,3,2,∅,4,标签1表示“Name”这个内容应该出现在第一个位置,标签“∅”表示“Language”这个内容在标准摘要中没出现。根据输出的标注序列,我们对所有的Keys进行重排序,形成一个内容规划c如图二所示即为 “ N a m e C o u n t r y A u t h o r P u b l i s h e d ” “Name Country Author Published” “NameCountryAuthorPublished”。
Prompt-Controlled Generator
提示控制生成器旨在给定表格输入和内容规划,生成流畅且忠实的描述。我们的方法是模型无关的,可以是任何预训练生成模型,本文使用BART-large。
本文提出了两种Prefix,用来拼接在BART的Encoder的输入之前,即task-specific prompt p s p_s ps和input-specific prompt c c c(content plan),后者即是PCG的引导信号。
对于task-specific prompt,设计为Prefix-Tuning,针对长度和作用于注意力层带来的Prefix性能瓶颈。本文额外地将两个Scaled Parallel Adapter分别并行到注意力层和前馈神经网络层,然后对这些Adapter进行Scaled add。
-
输入
模板句子: s = s 1 , s 2 , . . . , s L s = {s_1, s_2, ..., s_L} s=s1,s2,...,sL ,长度记作 L L L;内容规划: c = c 1 , c 2 , . . . , c L c c = {c_1, c_2, ..., c_{Lc}} c=c1,c2,...,cLc, 长度记作 L c L_c Lc;Prefix长度记作 L p L_p Lp。
拼接内容规划和生成的模板句子为 [ c : s ] [c:s] [c:s], s s s是生成的模板句子,即形如“name is edinho júnior; fullname is edon júnior viegas amaral; birth_date is 7 march, 1994; …”,即“Key is Value…”。然后送入BART Encoder。
-
多头注意力机制层
先根据输入x计算Q、K、V,因为输入是拼接,所以三者的维度为:
queries Q ∈ R ( L + L c ) × d Q ∈ R^{(L+Lc)×d} Q∈R(L+Lc)×d, keys K ∈ R ( L + L c ) × d K ∈ R^{(L+Lc)×d} K∈R(L+Lc)×d and values V ∈ R ( L + L c ) × d V ∈ R^{(L+Lc)×d} V∈R(L+Lc)×d
随后计算注意力得分, P k ∈ R L p × d , P v ∈ R L p × d P_k ∈ R^{L_p×d}, P_v ∈ R^{L_p×d} Pk∈RLp×d,Pv∈RLp×d分别表示两组Prefix向量:
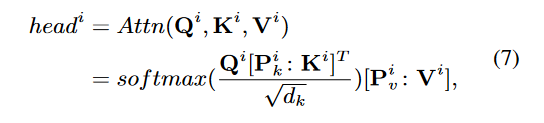
-
添加Scaled Parallel Adapter
其实就是两个并行的前馈神经网络,s ≥ 1是一个超参数, W d o w n ∈ R d × r W_{down} ∈ R^{d×r} Wdown∈Rd×r and W u p ∈ R r × d W_{up} ∈ R^{r×d} Wup∈Rr×d, r r r表示瓶颈维度。其并行计算结果和注意力模块输出线性相加:

同样的,在原来的FeedForward层插入一个Scaled Parallel Adapter来增强它的表征能力:
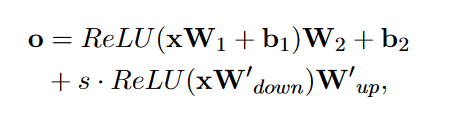
Experiments
对比了几种模型,本文提出的方法基本表现出了最佳性能,特别是在文本真实度方面,即PARENT-F指标,表现出的性能远超baseline,这应该是证明了Content-Planner的作用。另外Bi-LSTM+CRF在本文的Content Plan这一序列标注任务上表现出的准确率远高于RobertaforSequenceClassification。
Ablation Study
消融实验表明,task-specific prefix和input-specific prefix都提高了生成句子的忠实度,而input-specific对文本流畅度贡献很小。这个结果证实了本文的intuition,input-specific prefix的目的在于通过规划内容提高生成文本的忠实度。
消融实验结果如下图,可以看到在BLEU上Content Planner的影响很小,甚至去掉它有反向提升。

Conclusion
- 结合了Hard+Soft两种Prompt方法。
- 设计一种适配任务的Prefix,使得Prefix更能挖掘到PLM中任务相关的先验知识。
- 利用到了监督信息,对生成内容进行细粒度的规划。具体而言,设计一个模块生成Hard Prompt作为引导信号,以控制生成,引导模型选择事实内容和正确的词序。
- 一个疑惑。对于标准回复中没出现的Key,我们就一定不要生成吗?一定是冗余的吗?这样的训练目标完全依赖groundtruth。