对seq2seq模型,attention机制以及NLP评价标准不了解的同学可以看的另外三篇笔记(暂未完成),文中将不仔细介绍这些内容,有疏漏或者补充欢迎评论~
论文
Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus
Yoshua Bengio
University of Montreal, Canada 2016
原文地址
作者目标是基于知识库(KB)生成大量问题,方法是将一个事实转化为一个满足以下两个条件的问题。一个是问题要与这个事实的relationship和subject相关,第二点是问题的答案应该就是这个事实的object。
知识库的结构类似于有向图,一个fact可以视为含有三个参数subject,object和relationship,前两者是node,后者是edge。{subject->object}
查了一下,居然是memory net的提出者FB大佬Antoine Bordes的文章
模型:
F代表fact,Q代表question ( )
结构:
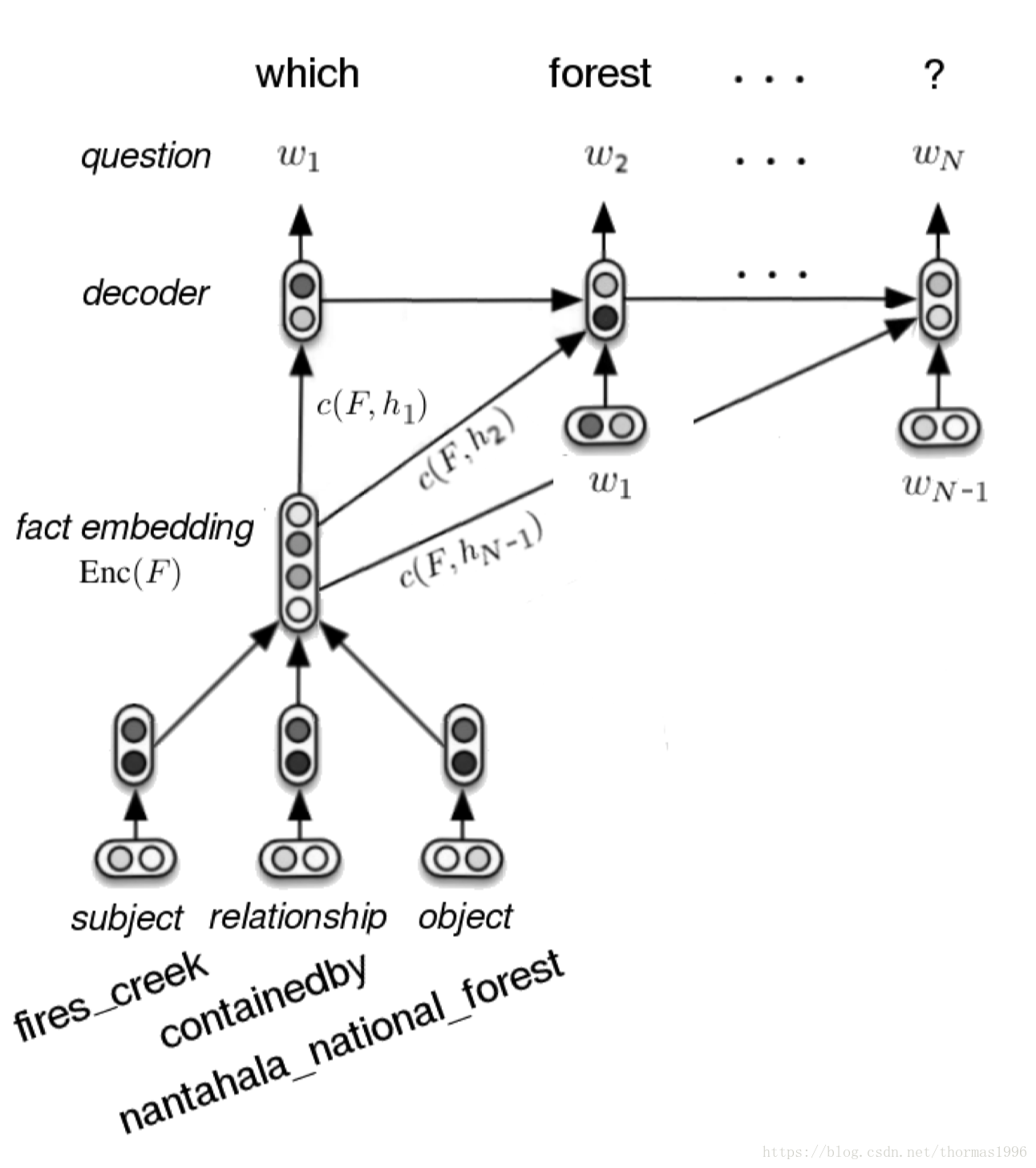
模型就是一个带attention的seq2seq模型,encoder+decoder
encoder是将fact的三个参数分别embedding后直接拼接得到语义向量c
decoder是一个GRU RNN,attention是bahdanau attention
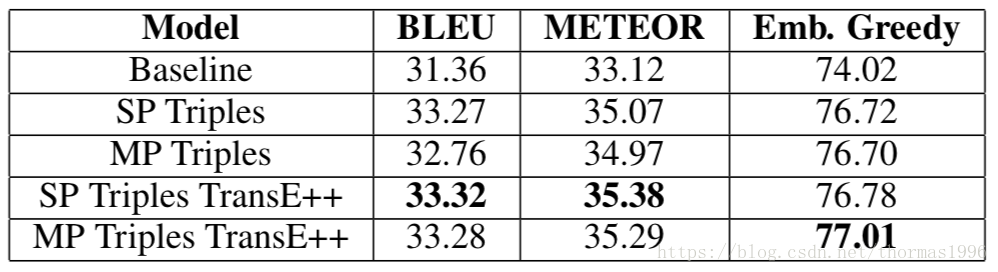
评价标准:BLEU,METEOR,Emb. Greedy
实验结果:
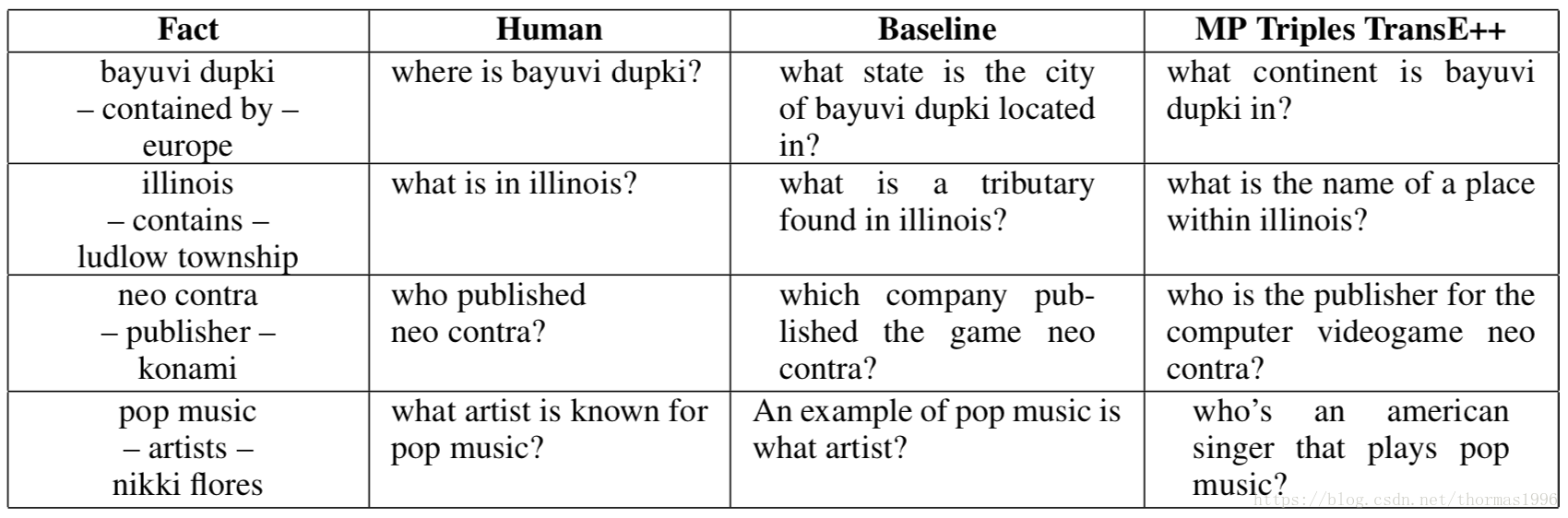
例子:
Learning to Ask: Neural Question Generation for Reading Comprehension
Machine Comprehension by Text-to-Text Neural Question Generation
ASPECT-BASED QUESTION GENERATION
Wenpeng Hu, Rui Yan
Peking University
ICLR 2018
原文链接
作者提出了一种简单的得到aspect分类的方法,利用seq2seq生成满足给定的问题种类和领域的问题。这篇文章的优点在于训练集还是无标签的QA对,但在预测时通过给定question type和aspect type来生成多样化的问题。
数据集:Amazon question/answer corpus
分类:
aspect type 先将所有A中单词都认为是可能的候选,然后用Q中单词与A中单词两两计算余弦值,对A中单词进行投票得到
,如果
大于某一阈值K,则认为这个单词是aspect type
question type 分为’yes/no’,’what’,’who’,’how’,’where’,’what’, ’others’七类
对于中文样本可以借鉴aspect type分类的方法,但是疑问词这个关键词该如何提取还没有很好的想法
模型:
q 是生成的question,s是输入的answer,a是aspect type,qt是question type
结构:
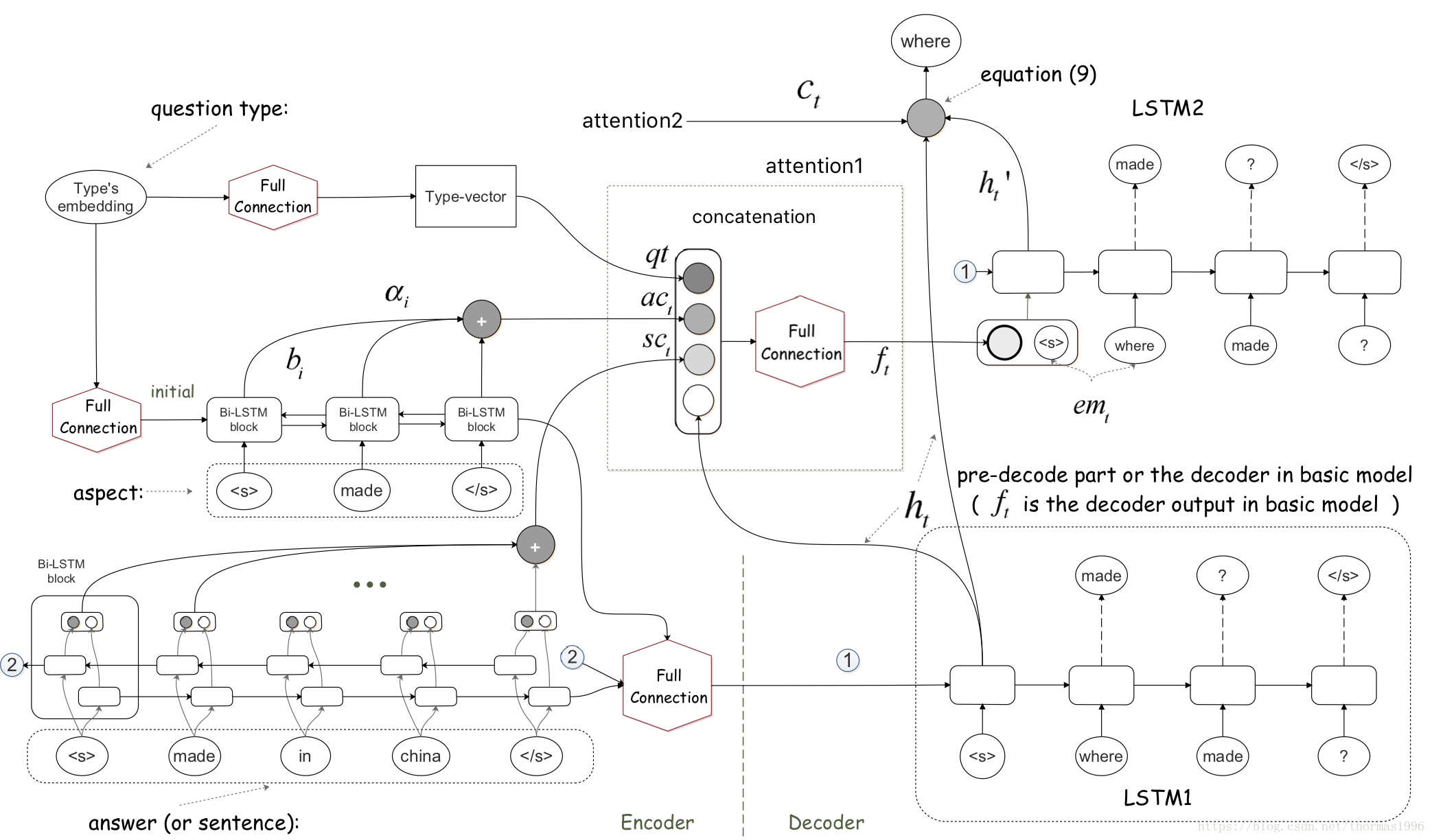
encoder 有两个answer encoder和aspect encoder,都是双向LSTM RNN,隐藏层向量由双向隐藏层向量的拼接构成。两个encoder都用了bahdanau attention。
为了减少噪声,作者先以上述encoder的输出为输入训练一个LSTM,称之为pre-decode LSTM,得到一个隐藏层状态h(t),然后这个h(t)与前面answer encoder,aspect encoder以及question type embedding的结果合起来训练最终的LSTM decoder。
这里可能有点绕,看图更容易理解,先不管右上角的final decoder,左边三个输入使用attention1得到pre-decode结果,这四者合起来使用attention2得到final decode的结果。
评价标准:BLEU,METEOR,ROUGE,RPF
实验结果:


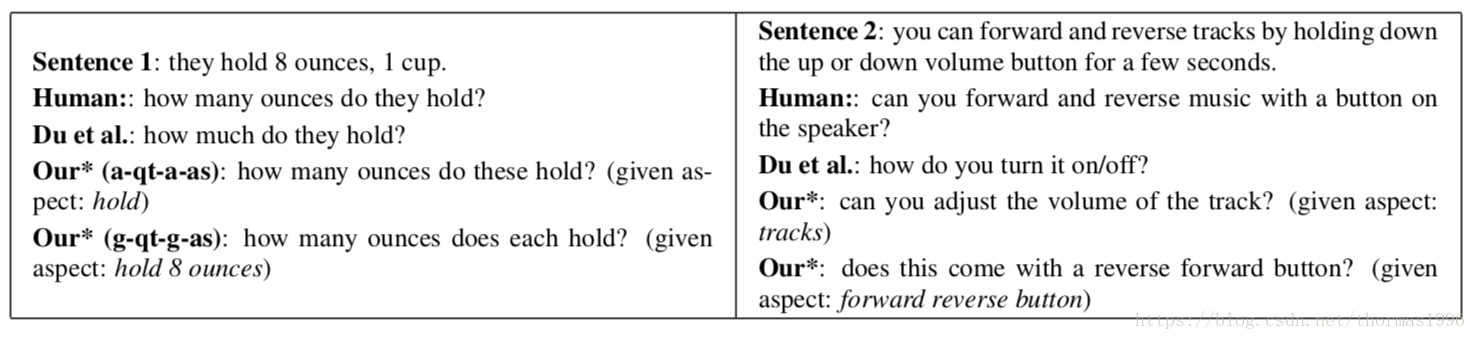
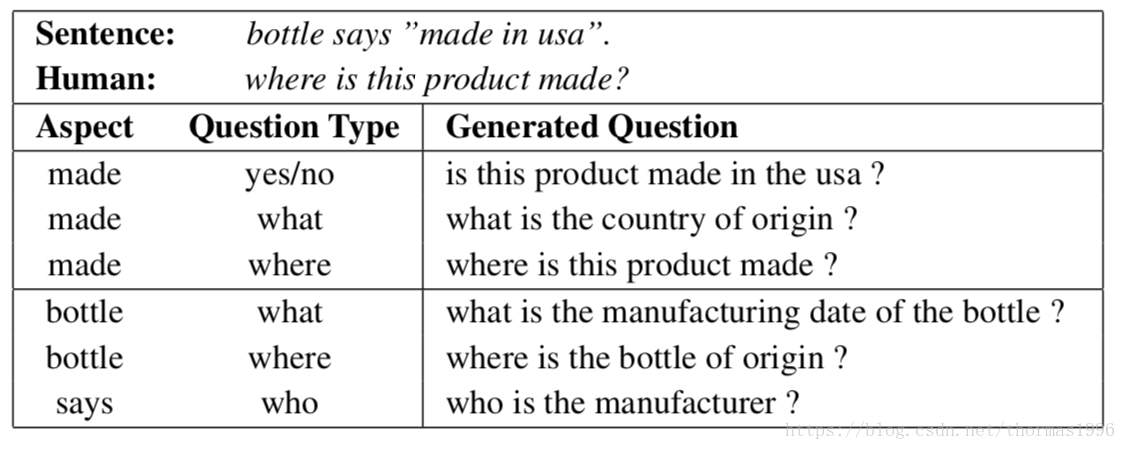
例子:
Mark 两个不错的资源:
这个github上有一些paper和数据集的汇总(QA)
https://github.com/dapurv5/awesome-question-answering
徐阿衡的博客,博主整理了七篇阅读理解方向QG的文章
http://www.shuang0420.com/