Prefix-Tuning: Optimizing Continuous Prompts for Generation

会议:ACL2021
任务:自然语言生成
源码:链接
原文:链接
Abstract
本文提出Prefix-Tuning,一种用于NLG任务的可以替代fine-tune的轻量级方法,它冻结语言模型的参数而代之以优化一系列连续的任务特定(task-specific)向量,称之为prefix。前缀微调从提示学习中获得启发,引导后续的token关注这个prefix,就好像它是虚拟的单词一样。本文应用前缀微调,使用GPT-2进行table-to-text任务、使用BART进去文本摘要任务。实验结果表明,仅需修改0.1%的参数,Prefix-tuning在全数据集下获得了可比的性能,在低数据集条件下优于微调,并且能更好地外推到训练过程中没有发现的主题的例子。
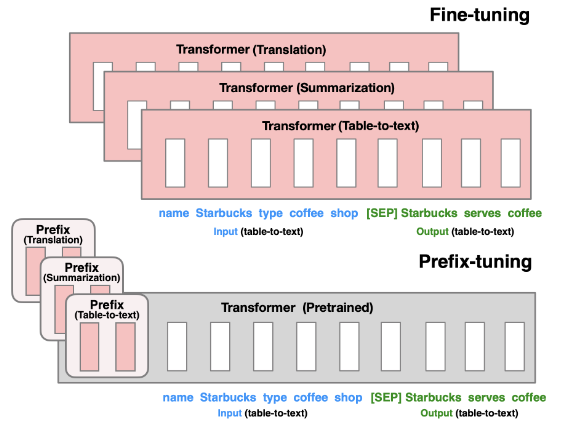
Motivation
-
微调需要更新、存储整个LM的参数,代价昂贵;
-
GPT3提出了in-context learning,无需更新任何参数,是prompt的一种形式,然而,因为Transformers只能基于有界长度的上下文(例如,GPT3最大长度为2048个token),因此,在线学习仅限于非常小的训练集。
-
prefix:在输入前面添加的一系列任务特定的连续向量。不同于prompt,prefix完全由自由参数组成,和真实的单词无关。
扫描二维码关注公众号,回复: 15995162 查看本文章
-
fine-tuning vs. prefix-tuning:微调更新所有LM参数,从而需要为每个任务存储一个fine-tuning的模型参数副本;prefix-tuning只优化前缀。因此,我们只需要存储LM的一个副本和一个学习到的任务特定前缀,这为每个额外的任务带来非常小的开销,Prefix-tuning属于广义上的轻量级微调,即冻结大部分预训练参数,仅一小部分参数。关键的问题是如何扩充LM结构并决定哪些预训练参数子集需要调整。
-
比之fine-tuning,prefix-tuning也可以模块化:我们训练一个下游前缀用来引导语言模型,因此,单个LM可以同时支持多个任务。此外,基于前缀的架构使我们能够在单个批次中处理来自多个用户/任务的示例,这是其他轻量级微调方法(adapter-tuning)所不可能做到的。
Main idea
如图所示, h i j h_i^{j} hij表示第i个时间步模型第j层的隐藏向量。

Intuition
Prompt表明了基于一个合适的上下文可以引导语言模型而不更新任何参数。例如我们想要LM生成一个词(如:Obama),我们可以将其常见的搭配预设为语境(如:Barack),那么LM将会分配更大的概率给我们的期望词。将这种intuition扩展到生成单个单词或句子之外,我们希望找到一个引导LM解决NLG任务的上下文。直觉上,上下文可以通过指导从x中提取什么来影响任务输入x的编码,通过指导下一个单词分布来影响任务输出y的生成。然而,这种语境是否存在并不明显直观。直接使用自然语言任务指令作为上下文来引导,这对中等规模的模型无效(本文实验发现对GPT3有效,而对GPT2和BART无效)。对离散指令进行优化可能有所帮助,但离散优化在计算上具有挑战性。
我们提出通过将上下文指令视为连续的词嵌入来优化,它可以向上传播到transformers的激活层,向右传播到后续单词。这严格来说比受限于实词嵌入的离散提示更具表现力。通过优化所有层的激活,而不仅仅是嵌入层的激活,prefix-tuning在提高表达力方面更进一步。另外,Prefix-tuning可以直接修改网络中更深的表示,从而避免跨越网络深度的长计算路径。
Method
对于自回归LM,直接在输入前面拼接prefix,即 z = [ P R E F I X ; x ; y ] z = [PREFIX; x; y] z=[PREFIX;x;y];对于编码器-解码器LM,encoder和decoder均前置一个前缀,即 z = [ P R E F I X ; x ; P R E F I X ′ ; y ] z = [PREFIX; x; PREFIX′; y] z=[PREFIX;x;PREFIX′;y]。 ∣ P i d x ∣ |P_{idx}| ∣Pidx∣表示前缀长度, P i d x P_{idx} Pidx表示前缀索引。 P θ P_θ Pθ即可训练的前缀自由参数,大小为 ∣ P i d x ∣ × d i m ( h i ) |P_{idx}| × dim(h_i) ∣Pidx∣×dim(hi)。
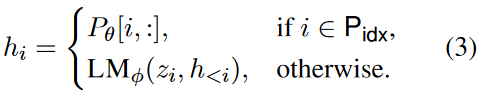
当 i ∈ P i d x i ∈ P_{idx} i∈Pidx时,直接从 P θ P_θ Pθ中复制参数给 h i h_i hi,反之, h i h_i hi也会取决于 P θ P_θ Pθ,因为prefix始终是位于左边的上下文,会影响到右边的隐藏状态。
本质上,其实是在每一层每一个token的K、V向量之前拼接上一个Prefix向量,网上找到了两张图解释得很清楚:


Parametrization
作者在初步实验中发现直接优化前缀对初始化非常敏感。因此,直接更新该参数矩阵会导致优化不稳定,性能略有下降。所以通过一个矩阵 P ′ θ P′_θ P′θ来重新参数化,该矩阵由大规模的前向传播神经网络组成。 P θ [ i , : ] = M L P θ ( P ′ θ [ i , : ] ) P_θ[i, :] = MLP_θ(P ′ _θ[i, :]) Pθ[i,:]=MLPθ(P′θ[i,:])。那么,可训练的参数就包括 P θ ′ P'_θ Pθ′和 M L P θ MLP_θ MLPθ。训练完成以后,重参数化参数可以去除,仅有前缀参数 P θ P_θ Pθ需要保存。注意, P θ P_θ Pθ和 P θ ′ P'_θ Pθ′具有相同数量的row(即前缀长度)。
Experiments
table-to-text
使用GPT-2-medium和GPT2-large,体现出一个降本增效,仅更新0.1%的task-specific参数,其性能就超越轻量级微调,并且和完全微调基本持平。此外,在DART数据集上取得良好的性能表明,前缀调优可以推广到具有不同域和大量关系的表。且规模扩大了性能仍然能保持,说明Prefix-tuning可以推广到大模型。
Summarization
使用BART-large,%2的参数,性能略低于完全微调,这是因为相比table-to-text,数据集规模大,句子长,任务更复杂
Low-data Setting
类似于few-shot learning,低资源场景下,Prefix-tuning性能优于fine-tuning且需要更少的参数,但差距随着数据集规模的增加而缩小。
Extrapolation
类似于zero-shot learning,该实验用来验证Prefix-tuning在未知话题上的有效性。实验结果发现Prefix-tuning在两个任务的所有指标上都优于fine-tuning。并且实验结果发现adapter-tuning达到了较好的性能,和Prefix-tuning相对持平,这表明保留LM的参数确实对Extrapolation有积极影响。
Intrinsic Evaluation
Prefix Length
更长的前缀意味着更多的可训练参数,实验结果表面,模型性能随着前缀长度增大而增大,到了一定阈值开始下降。大于阈值以后,训练损失更低,而在测试集上的性能略微降低,说明过拟合了。

Full vs Embedding-only
embedding-only:词嵌入层是自由参数,其余由transformers计算。
表达力:discrete prompting < embeddingonly < prefix-tuning.
Prefix-tuning vs Infix-tuning
Infix-tuning指把向量放x和y中间。即 [ x ; I N F I X ; y ] ) [x; INFIX; y]) [x;INFIX;y])。实验结果表明infix-tuning性能比prefix-tuning略低,这是因为prefix能影响x和y的激活,而infix只能影响y的。
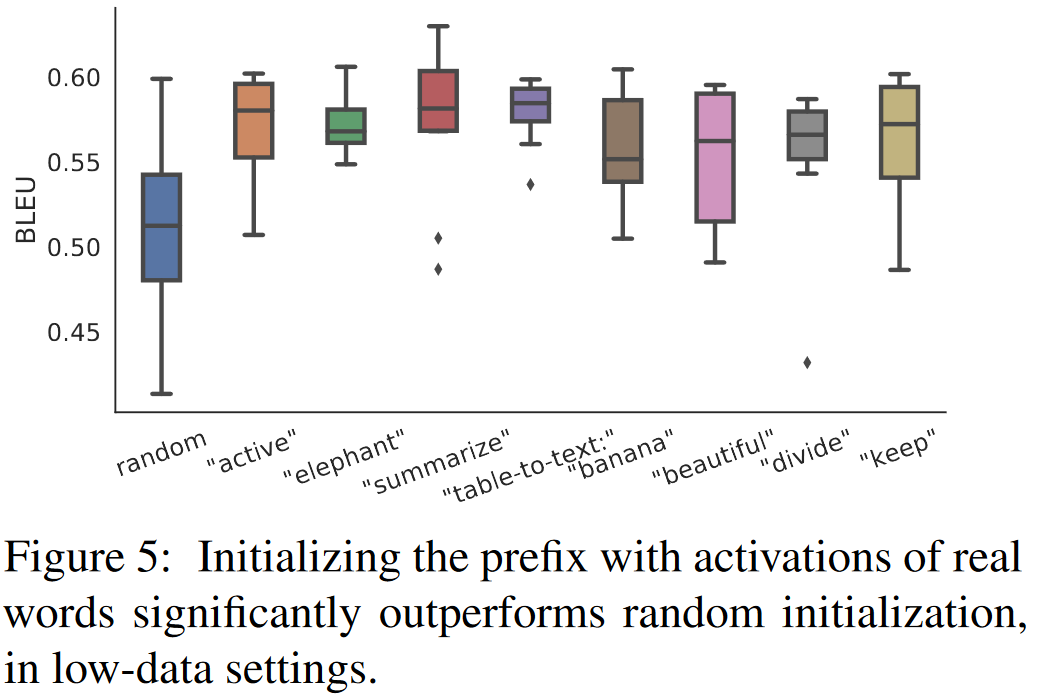
Initialization
本文发现如何初始化prefix在低资源场景下对模型性能影响很大,随机初始化导致高方差的低性能。将prefix初始化为真实词显著提升了生成,并且,将其初始化为任务相关的真实词比不相关的词具有更高的性能,但是使用真实词仍然强于随机初始化。
此外,在全数据场景下,初始化trick没影响了,且随机初始化达到一个平均性能。
由于我们使用LM计算的实词激活来初始化前缀,所以这种初始化策略符合前缀调整的思想:它尽可能地保留了预训练的LM。
Data Efficiency
数据量大于20%时,prefix-tuning性能比fine-tuning更好,数据规模在10%时,则需要初始化的trick在提升低资源场景下的性能。
Discussion
Prefix-tuning适用于大量独立任务场景,例如隐私保护。前缀调优允许批处理不同用户的查询,即使他们有不同的前缀支持。批处理时在每个用户输入预置前缀就行,这种批处理的好处还可以帮助创建在同一任务上训练的多个前缀的有效集成。
大型LM训练于通用语料库,保存它们的参数有助于泛化到未知域,因为prefix-tuning和adapter-tuning在未知域探索情况下都表现很好。
此外,在保持性能相当的情况下,prefix-tuning比adapter-tuning调整需要的参数要少得多。这可能得益于“参数效率”,Prefix-tuning尽可能地保持LM的参数固定,因此能更高效地发掘LM。个人理解这里意思就是说Prefix相比Adapter-tuning更能学习到有用的参数吧。