论文地址:https://arxiv.org/abs/2203.07057
代码链接:https://github.com/DongSky/few-shot-vit
这篇论文在2022年发表在ECCV上,论文的题目是用于小样本Transformer的self-promoted supervision(自我推荐监督)
1 Motivation
1、目前很少的论文研究ViTs在小样本学习的应用。第一,ViTs在只有少数标记训练数据可用的小样本学习标准下实验表现并不好,原因是ViTs的自注意力机制不会引入任何 归纳偏置 。因此,在没有任何先前 归纳偏置 的情况下,ViTs 需要大量数据来学习局部特征(即patch tokens)之间的依赖关系,并且只学习到了低质量的标记依赖。
2、第二,因为CNN具有高 归纳偏置,所以一些研究中将类似CNN的归纳偏置引入到ViTs,虽然可以加速ViTs的 patch 标记(tokens)的依赖学习从而提高性能,但是ViTs和CNN的网络架构不同,因此类似CNN的归纳偏置并不能很好的适用于ViTs,而且CNN的归纳偏置不具备ViTs捕获数据中局部特征之间的远程依赖关系的能力。
因此,文章提出了一种新的ViTs的小样本训练框架,即self-promoted supervision(SUN),它的核心是通过密集的特定位置的监督来快速准确地学习patch tokens地依赖关系,解决Transfomrer较差归纳偏置的问题。
2 Idea
1、SUN为全局特征嵌入提供全局监督。并进一步对ViT在基类数据集预训练,然后使用ViT生成单独的特定位置(即与位置相关)的监督来指导每个patch 标记,这种特定于位置的监督可以告诉 ViT 哪些patch 标记相似,哪些不相似,从而加速 标记依赖学习 。另外,SUN对每个patch 标记的局部语义建模,提高模型泛化能力。
2、SUN为了提高patch级的监督质量,提出了两种技术:(1)背景patch过滤和(2)空间一致性增强。
3 Methods
SUN框架由两个阶段组成:元训练和元微调

对于元训练阶段 (a),给定图像 xi,我们使用空间一致的增强来生成两个裁剪 ¯xi 和 ∼xi。
给定∼ xi,具有背景过滤 (BGF) 的教师 (ViT f0 & 和分类器 g0) 生成其特定于位置的监督 {sij}
给定 ¯xi,元学习器 f 提取其标记特征,然后全局分类器 gglobal 和局部分类器 glocal 分别预测 ¯xi 的全局语义标签∼ yi 和所有patches的语义标签 {∼sij}。
最后,SUN 使用真实标签 yi 和特定位置标签 {sij} 来监督 ∼yi 和 {∼sij} 以优化 f 和 gglobal/local。
在元微调阶段 (b),SUN 采用现有的小样本方法(例如元基线 [8])微调 f,然后使用支持集 S 预测每个查询 x 的标签。
3.1 元训练
目的 :学习一个meta-learner(元学习器) f,是其能够通过少量样本快速适应新类别。
1、使用 全局监督 ,即 ground-truth 标签,来指导 f 中所有patch标记的全局平均标记
2、使用 单独的特定位置监督 来监督(指导) f 中的每个patch标记。
-生成 patch级伪标签 作为特定位置的监督
SUN 首先在基类数据集集上预训练,来优化 教师模型 (teacher model) fg,它由与 f 具有相同架构的 ViT f0 和基类数据集 Dbase 上的分类器 g0 组成的。利用f0来生成生成patch级的伪标签作为特定位置的监督.
-之所以称为自我提升的监督,就是因为SUN使用相同的ViT来生成局部监督。
-形式上,对于基类数据集 Dbase 中的每个训练图像 xi,SUN 首先计算每个标记的分类置信度得分 ^si:
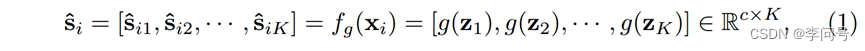
其中 z = f(xi) = [zcls, z1, z2, · · · , zK] 表示图像 xi 的类(zcls)和patch 标记,而 ^sij 是样本 xi 中第 j 个局部patch xij 的伪标签。
因此,对于每个patch xij,在 ^sij 中具有相对高置信度的位置表明这个patch包含相应类别的语义。
3、背景过滤(BGF)
目的: 将背景patches分类为一个新的独特类别来提高patch级监督的质量
做法: 过滤掉置信度分数很低的局部patches作为背景patches,并将它们分类到一个新的独特类别中
-具体来说,文章在基类 Cbase 中添加了一个新的类,即背景类,相应地,伪标签 ^si增加一维。将置信度分数较低的patches分类到背景类,即这些patches的伪标签设置为最后位置为1,其余位置为0;对于非背景patch,就是置信度分数较高的patches,设置它们的伪标签最后位置为0,其余位置不变。
-整体的训练损失公式:
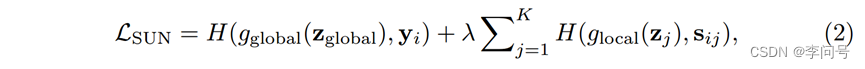
其中 z = f(xi) = [zcls, z1, z2, · · · , zK] 表示图像 xi 的类(zcls)和patch 标记,zglobal 是所有patch 标记 的全局平均池化。这里H表示交叉熵损失,gglobal和glocal分别是全局语义分类和局部patch分类的两个可训练分类器。
-对背景过滤掉之后,就得到了 密集监督 ,有两点好处:
(1)减少了背景杂波的影响,可以保证相似的局部标记具有相似的伪标签,从而可以加速 标记依赖学习。
(2)相对于对整幅图像的全局监督,特定位置的监督处于细粒度级别,即patch级别,从而帮助 ViTs 轻松发现目标对象并提高识别精度。
4、空间一致性增强(SCA)
目的: 提高教师 f0 局部监督的鲁棒性,同时保持足够的数据多样性。
SCA由纯空间增强和非空间增强组成。(spatial-only augmentation and a non-spatial augmentation.)
-纯空间增强
引入空间变换:随机裁剪和调整大小、翻转和旋转,来增强输入图像- xi 并获得~ xi。
在元训练阶段,我们将 ∼xi 输入教师 f0 以生成 sij:教师 f0 使用弱增强 ~xi 来生成特定位置监督,这也有助于提高 ViT 的泛化能力
将 ¯xi 输入目标元学习器 f:训练元学习器 f 的样本具有高度多样性,同时仍然享有非常准确的特定位置监督 sij。
3.2 元微调
目的: 更好地适应包含只有少数标记样本的未知类的新任务。
做法: 微调元学习器f通过训练它在从基类数据集 Dbase 采样的多个“N-way K-shot”任务 {τ}
-具体来说,给定一个支持集 S 的任务 τ,SUN计算类 k 的分类原型 wk:
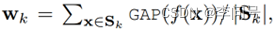
其中 Sk 表示来自类 c 的支持样本, GAP表示全局平均池化操作
然后对于每个查询图像 x,元学习器 f 计算第 k 个类的分类置信度分数:
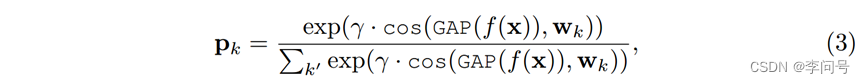
其中 cos 表示余弦相似度,γ 是温度参数。最后,它最小化交叉熵损失 Lfew-shot = H(px, yx) 以在各种采样任务 {τ} 上微调 meta-leaner f,其中 px = [p1, · · · , pc] 是预测, yx 是 x 的真实标签。在这个元微调之后,给定一个新的测试任务 τ ′ 和支持集 S ′ ,我们按照上面的步骤计算它的分类原型,然后使用等式 (3) 预测测试样本的标签。
4 Results
为了公平比较,文章缩放了ViT 的深度和宽度,使得它们的模型大小类似于 ResNet12 [17](~12.5M 参数)
1、最初的ViT
-所有ViT无论是经过元训练还是元训练+元微调,表现都比 ResNet-12 差得多。
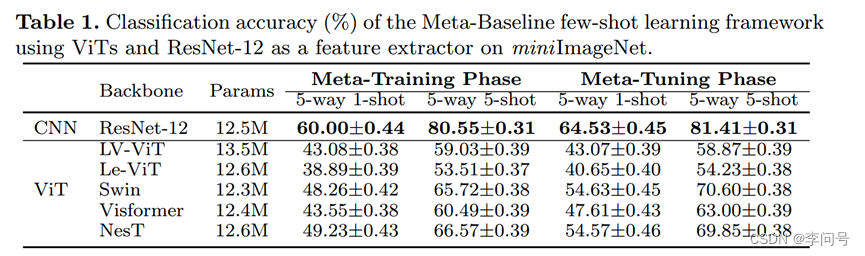
-a和b看出所有 ViT 在基础数据集 Dbase 中的训练和验证集上都很好地收敛;
-c看出 ViT 在整个元训练阶段也很好地收敛于新类别的训练数据;
-d看出ViT 对新类别的测试数据的泛化能力较差。
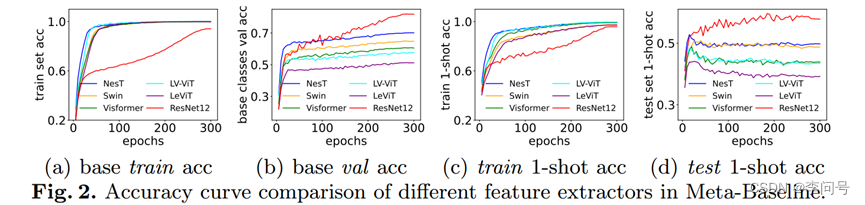
2、ViT引入归纳偏置
三种方式:
-使用一个 ViT 分支和一个 CNN 分支来独立提取图像特征,并将它们的特征进行融合;
-在 Dbase 上训练一个 CNN 模型,并通过知识蒸馏使用它来教授 ViT ;
-局部注意力引入了(类似 CNN 的) 归纳偏置。
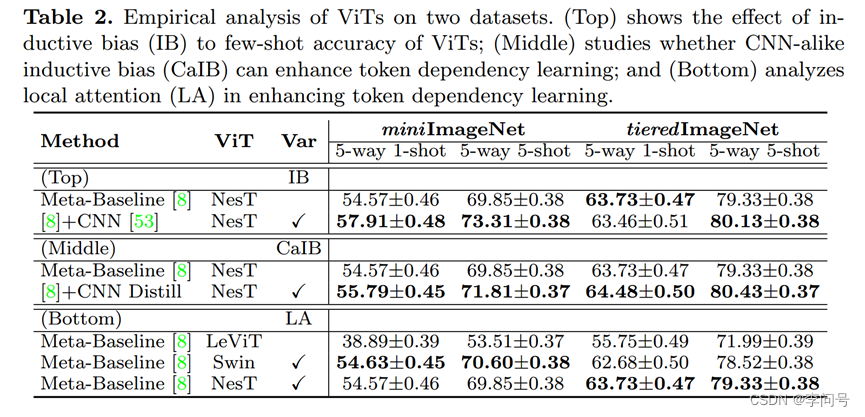
3、收敛速度≠标记依赖学习的质量
-与 vanilla ViT 相比,CNN distilled ViT 可以学习更高质量的 token 依赖性,如图 4(a) 所示。然而,CNN distilled ViT 收敛速度较慢且训练精度较低,如图 4(b) 所示。
-对于 vanilla ViT,其训练精度在前 30 个时期迅速增加,但在图 4(b)中的后续时期变得饱和,而其在最后一个块的注意力图仍在图 3 中演变。
-图 4(c)(和 4(d))表明注意力得分距离在所有训练阶段都稳定下降。
注意,注意力距离越大表明该点在图像中越重要,这里注意力稳定下降,应该指的是一些背景patch。
4、引入SUN后的ViTs
-表 3 显示,在 miniImageNet 上,SUN 在四个 ViT 上显着超过元基线
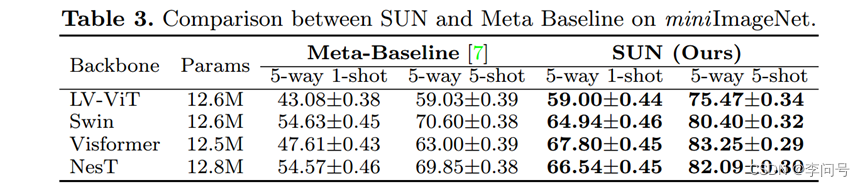
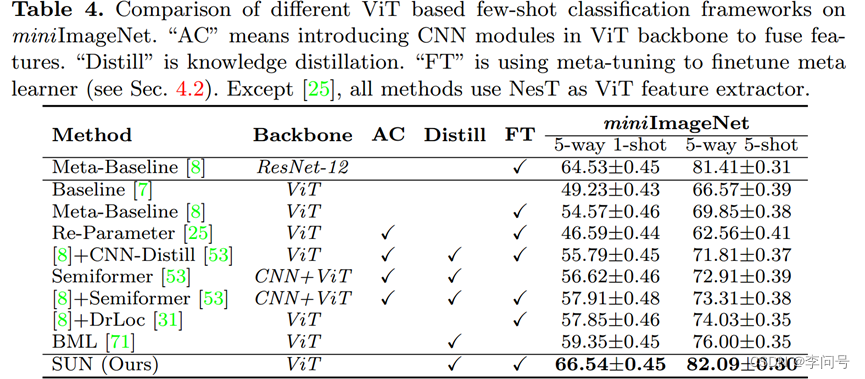
-表4显示,SUN在1-shot实验已经达到了66.54%,非常高了
一些方法细节:
AC:引入CNN模块
Distill:知识蒸馏
FT:元微调
所有的方法都是使用NesT作为ViT的特征提取器(纯Transformer)
-表5显示,SUN和目前SOTA的比较,使用Visformer(引入了CNN模块)的SUN准确率已经达到了67.80%,更高!

5、消融实验
-各个模块的作用

-元微调的方法
当选择DeppEMD作为SUN的元微调方法时,结果已经超过SOTA,达到69.56%(特征提取器为Visformer)

此外,具有 ViT 主干的 SUN 是第一个将 ViT 主干应用于少样本分类的工作,与以前的工作 [11,19,58,67,30] 利用Transformer层作为少样本分类器不同。