3 实验
3.1 实验设置
数据集
Spider:复杂文本到SQL问题的跨领域数据集。
Spider-Syn:使用同义词替换Spider问题中的模式相关词汇,评估系统的鲁棒性。
Spider-DK:在Spider示例中添加领域知识,评估跨领域泛化能力。
Spider-Realistic:去除列名的明确提及,模拟更现实的文本-表格对齐设置。
模型
使用Codex(基于GPT-3的变体)和ChatGPT (gpt-3.5-turbo)来评估不同ICL策略。
Codex在1到10-shot范围内提供结果,而ChatGPT因最大上下文长度限制仅提供1到5-shot的结果。
评估指标
使用执行准确度作为所有实验的评估指标。
Baseline
主要分为Few-shot和Zero-shot上的实验,包括:
Few-shot
- Random sampling ®: 从样本池中随机选择示例。
- Similarity sampling (S)
- Diversity sampling (D): 从样本池的k-Means聚类中选择多样化示例。
- Similarity-Diversity sampling (SD): 根据算法1选择示例。
- SD + schema augmentation (SA): 通过架构知识增强指令(语义增强或结构增强)。
- SD + SA + Voting: 根据算法2描述的综合策略。
Zero-shot
- Baseline - DB as text-seq: 文本到SQL任务的标准提示,其中结构化知识被线性化为文本序列。
- Baseline - DB as code-seq: 通过将结构化知识源线性化为多个SQL CREATE查询来改进指令。
- Baseline - DB as code-seq + SA: 通过架构知识增强指令。
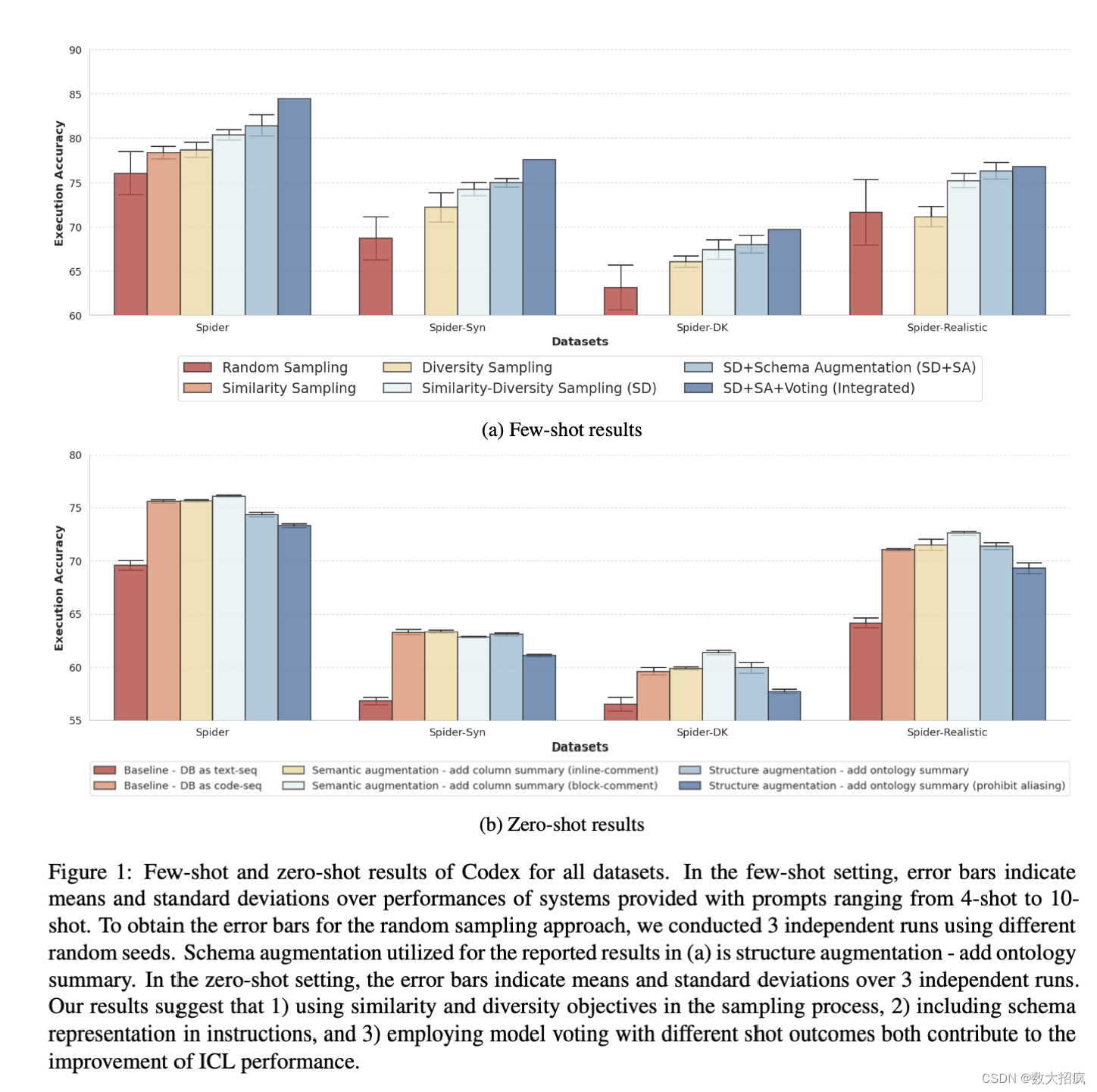
3.2 主要结果
在code-davinci-002和gpt-3.5-turbo模型上测试了不同示例选择策略的效果。主要发现如下:
- 相似性和多样性目标的采样过程:结合相似性和多样性目标在采样过程中可以获得更好的性能。
- 架构表示的增强:在指令中加入架构表示(就是Listing 5中的最下面的那几行注释)可以提高性能。
- 投票集成策略:结合不同示例数量模型的结果进行投票,可显著提高整体性能。
- 架构增强在零次学习中的效果:将数据库转换为文本序列和CREATE查询的两种提示线性化方法进行了比较。后者显示出明显的性能提升。
- 两种架构增强技术的对比:一种在表中的每列中添加语义信息,另一种加入实体关系知识。结果表明,结构增强(添加本体概要)在Few-shot设置中为Codex带来更大的改进,而语义增强(作为块注释添加列概要)在Zero-shot设置中对Codex以及Few-shot设置中对ChatGPT更有益。
研究显示,通过探索和实施不同的提示设计策略,可以显著提高LLMs在文本到SQL任务中的性能。这些策略不仅包括示例选择的优化,还包括架构表示的增强和投票集成方法的应用。通过这些策略,为利用LLMs在文本到SQL领域中的应用提供了有力的实证支持。