摘要
上下文学习(ICL)已成为处理各种自然语言处理任务的一种新方法,它利用大型语言模型(LLM)根据上下文进行预测,并辅以一些示例或特定于任务的指令 。 在本文中,我们的目标是将这种方法扩展到利用结构化知识源的问答任务,并通过探索使用LLM的各种提示设计策略来改进文本到 SQL 系统。 我们对不同的演示选择方法和最佳指令格式进行了系统研究,以提升LLM在文本到 SQL 任务中的表现。 我们的方法涉及利用示例的 SQL 查询的语法结构来检索演示,并且我们证明在演示选择中追求多样性和相似性可以提高性能。 此外,我们表明LLM受益于数据库相关的知识扩充。 在 Spider 数据集上,我们最有效的策略比最先进的系统高 2.5 点(执行精度),比最佳微调系统高 5.1 点。 这些结果突出了我们的方法在使LLM适应文本到 SQL 任务方面的有效性,并且我们对促成我们的策略成功的因素进行了分析。
1.简介
我们的研究重点是探索文本到 SQL 领域语义解析任务的各种提示设计策略。 我们对 Text-to-SQL 数据集上的不同演示示例选择标准和指令格式进行了系统调查。 具体来说,我们建议采用示例的 SQL 语法结构作为检索演示的基础,从而有助于更准确地表示问题结构。 我们的方法表明,选择同时强调多样性和相似性目标的演示示例可以最大限度地提高性能。 我们的研究还表明,LLM在某些情况下可以从数据库相关的知识扩充中受益。 通过实验,我们确定了最有效的策略,该策略在 Spider 数据集上的执行准确度得分为 84.4。 该分数比当前最先进的系统高 2.5 分(Ni 等人,2023),比最佳微调系统高 5.1 分(Scholak 等人,2021)。 这些结果证明了我们的情境学习方案在使LLM适应我们的目标任务方面的有效性。 此外,我们还对促成我们战略成功的因素进行了实证研究和分析。
2.方法
为了在零样本或少样本设置中设计上下文学习的提示,找到一种最佳方法来表示、增强和安排输入输出映射中的所有资源非常重要。 此外,任务说明的制定应与这些资源保持一致。 当采用少样本学习时,从每个测试实例的带注释示例池中选择演示子集是另一个可能影响 ICL 性能的关键设计选择。 我们对每个组件提出了增强功能,并根据现有方法对其进行了评估。
2.1 示例选择
目标是从池中选择带注释示例的子集,为解决测试问题提供最佳上下文。 虽然从池中随机选择是一种选择,但 Liu 等人。 (2022a) 提出了 kNN 增强示例选择 (KATE),它根据比较实例的输入从池中检索 k 个最近邻。 为了实现这一点,首先使用句子编码器将所有池实例转换为连续向量。 在推理过程中,使用相同的编码器将测试实例的输入投影到潜在空间中,然后使用相似性度量(例如负欧几里德距离或余弦相似性)与向量池进行比较。 最后,从池中选择前 k 个最相似的注释示例。
本文提出使用输出SQL查询来选择示例,而不是使用输入问题。这是因为作者认为Text-to-SQL中SQL语句包含比输入问题中更明确的关于问题结构的信息。此外,与只能转换成连续语义向量的自然语言问题不同,SQL查询可以根据其语法转换成离散特征向量。为此,首先将所有池实例的SQL查询转换成离散语法向量。然后,这些元素被映射到二进制特征,表示它们在查询中的存在。推理时,首先使用初步预测器生成SQL查询草稿。然后,应用相同的过程将这个草稿查询转换成离散向量,用于检索演示示例。
作者提出了一种与之前不同的演示选择策略,即寻求平衡演示的相似性和多样性,这是通过将给定示例的表示从表示问题语义的连续值向量更改为捕获SQL语法的离散值向量来实现的。为此,首先将标注示例池划分为表示不同类别的不相交分区(基于难度等级)。给定一个测试实例,使用初步预测器生成一个草稿SQL查询,并根据其类别,检索属于相关分区的候选示例。接下来对示例的离散向量实施k-means聚类,选择靠近每个聚类中心的k个多样化示例用于构建提示。演示选择策略过程概述在算法1中。
结构化预测作为检索的基础
我们建议使用输出 SQL 查询来选择演示示例,而不是使用输入问题。 这是因为,与许多输出是分类标签或提取实体且几乎没有问题结构信息的任务不同,文本到 SQL 需要结构化预测,其中包含有关问题结构的更明确的信息。 在输入问题中提供。 此外,与只能转换为连续语义向量的自然语言问题不同,SQL查询可以根据其语法轻松转换为离散特征向量,从而使它们的比较更加高效和透明。 为了实现我们的建议,我们首先将所有池实例的 SQL 查询转换为离散语法向量。 这是通过解析查询并识别其语法元素(包括关键字、运算符和标识符)来完成的。 然后,这些元素被映射到指示它们在查询中存在的二进制特征。 在推理过程中,我们首先使用初步预测器生成 SQL 查询的草稿。 然后,我们应用相同的过程将此草稿查询转换为离散向量,该向量用于表示用于检索演示示例的测试实例。
平衡多样性和相似性
是通过将给定示例的表示从表示问题语义的连续值向量更改为捕获SQL语法的离散值向量来实现的。为此,首先将标注示例池划分为表示不同类别的不相交分区(基于难度等级)。给定一个测试实例,使用初步预测器生成一个草稿SQL查询,并根据其类别,检索属于相关分区的候选示例。接下来对示例的离散向量实施k-means聚类,选择靠近每个聚类中心的k个多样化示例用于构建提示。演示选择策略过程概述在算法1中。
2.2 指令中的Schema表示
指令对于设计提示至关重要,因为它们通过阐明提供的资源如何帮助推理过程来定义任务。本文主要关注于确定指令中表示结构化知识源的最佳方式,并确定可以增强推理过程的补充资源。
结构化知识的线性化
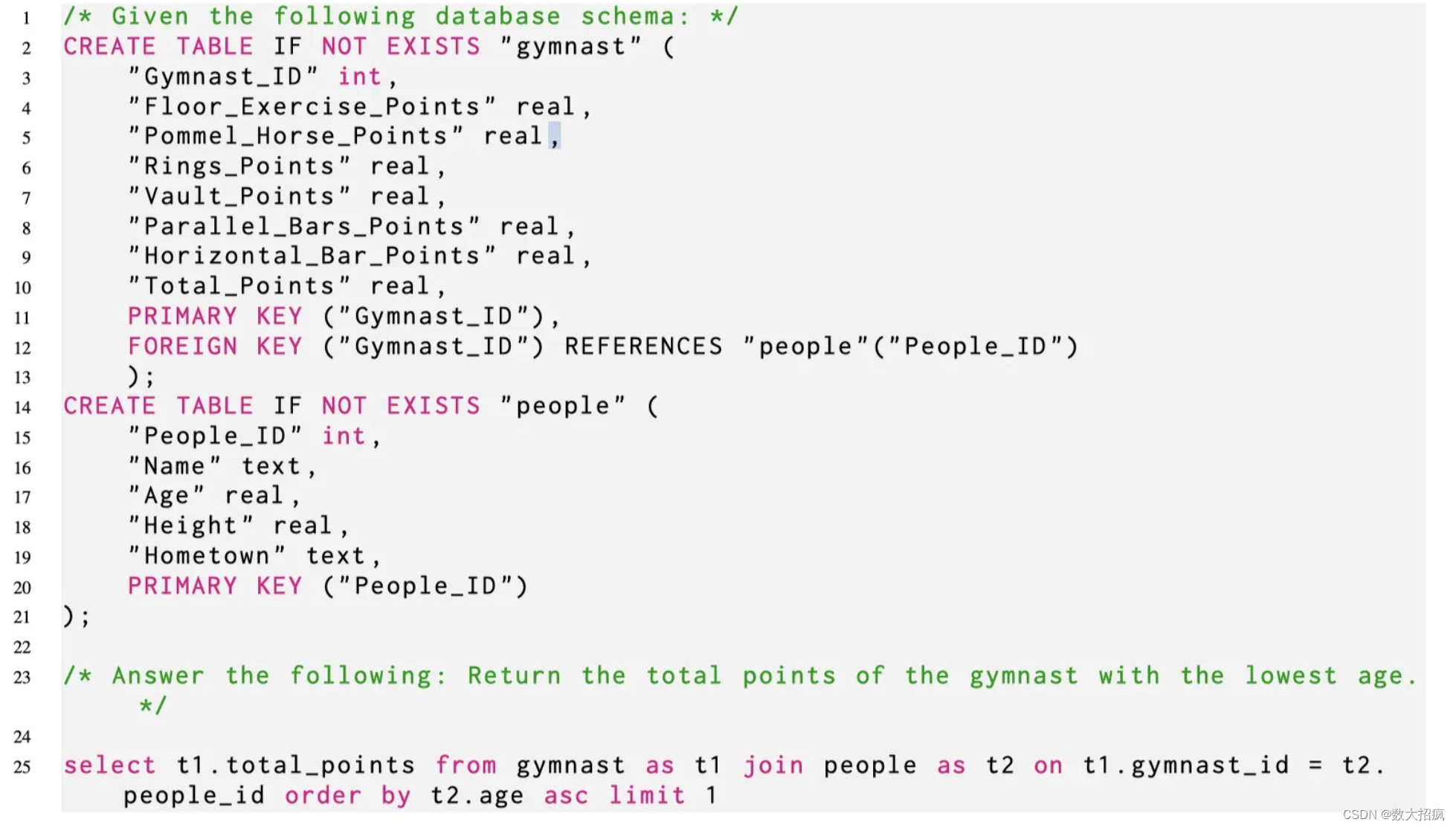
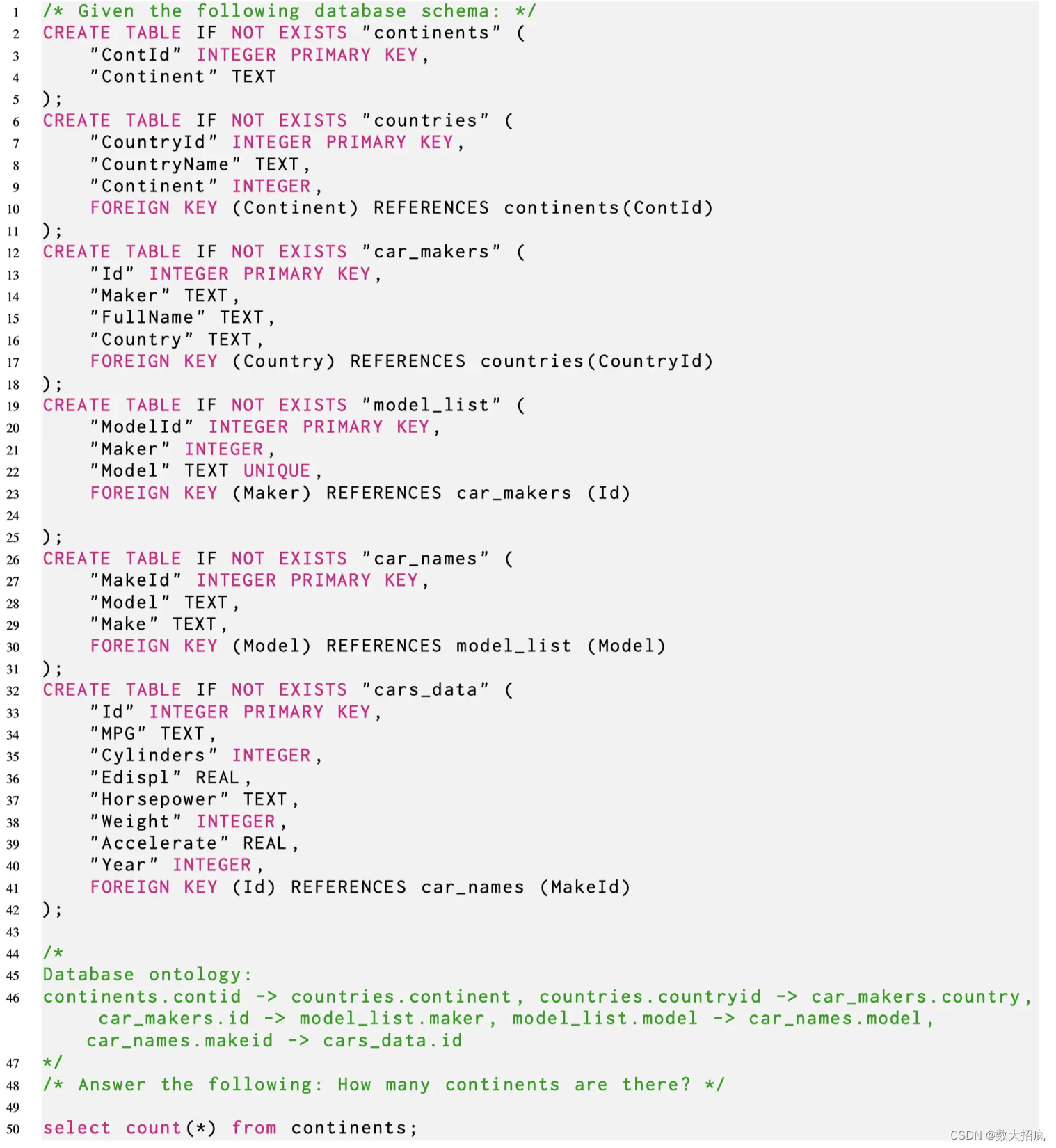
首先改变结构化知识的线性化方式。在以前的研究中,诸如数据库或表之类的结构化知识源已被线性化为“文本”序列。相反,本文提议使用“代码”序列来表示数据库,特别是用于最初构建表的CREATE查询,如附录中的清单1和2所示。这种线性化方法为每列提供了数据类型信息,并包含了数据库中所有外键约束的细节。此外,本文修改了指令中的其他资源,比如数据库中的问题和示例条目,使它们符合代码序列样式,通过将它们作为注释附加。

与模式相关的知识增强
数据库的本体通过提供一组类(表)、它们的属性(列)以及它们之间的关系的定义来描述数据库的结构和语义。 我们首先通过在整个数据库的上下文中详细阐述每个类和属性的含义来增强它们的语义。 具体来说,我们使用 OpenAI 的 gpt-3.5-turbo 引擎2 为每个表中的每一列生成自然语言定义,考虑其所有值和其他列。 然后,我们将这些定义合并到输入中,方法是将它们作为块注释附加或将它们作为内联注释插入到 CREATE 查询中。
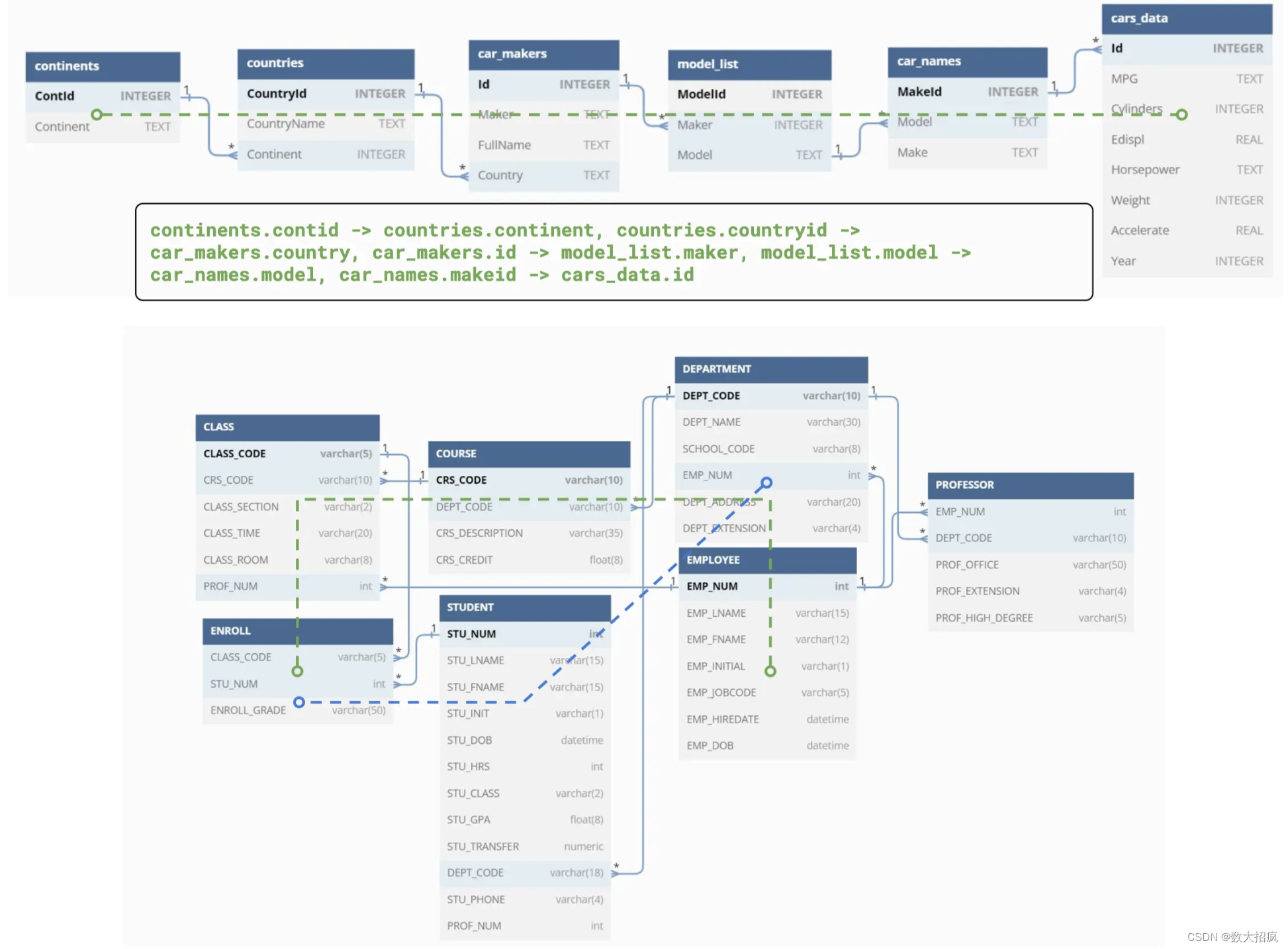
此外,我们建议通过提供实体关系摘要来增强数据库结构的表示,该实体关系摘要概述了表之间的连接并指定了它们如何连接。 如附录图 9 所示,数据库的实体关系图用于枚举不同表之间的所有可能路径。 这些路径随后根据其各自的长度按降序排列。 结果摘要在我们的实验中对于需要组合多个表的测试实例非常有用。 清单 5 进一步演示了我们的增强以及我们如何安排它们来构建提示。

2.3 文本到SQL的综合策略
实验发现,通过上下文学习(ICL)训练的模型对示例数量非常敏感,不同数量的示例导致模型性能表现出显著差异。为了在比较不同提示方法时得出有意义的结论,作者展示了具有相同配置但示例数量不同的模型的平均值和标准差。此外,采用多数投票法对表现多样的模型进行决策。具体来说,获取不同模型的贪婪解码预测结果,通过确定性数据库管理系统(DBMS)排除执行错误的预测,然后选择获得多数票的预测。其他整合方法,如自我一致性采样,也是可行的,但本文将其探索留待未来研究。详细结果可在附录的图10、11、12中查看。
构建文本到SQL任务提示的程序。首先,给定一组注释示例A,建立一个将池子划分为不相交分区Aα,AβA_α , A_βAα,Aβ 等的分类,每个分区包含SQL查询语法结构相对相似的示例。接下来,应用第2.1节中详述的k-means策略,为每个分区AjA_jAj 获取多样化的示例DjD_jDj。对于每个示例,通过将数据库转换成多个CREATE查询并增加与模式相关的知识来构建示例。在推理过程中,使用初步模型生成SQL查询草案,用于确定问题类别,进而确定构建提示的相应DjD_jDj。使用DjD_jDj中不同数量的样本获得多个预测,并通过多数投票得出最终预测。该方法的详细信息展示在算法2中。
