一.前言
这次的作业主要目的是研究偏差和方差也就是过拟合和欠拟合的关系,数据分别是水位的变化来预测大坝流出的水量,其实和房价预测相差不大,要说区别就是这次将X分为了三部分,分别是训练集,交叉集,测试集(X,Xval,Xtest)
二.代码部分
1.数据导入
还是导入scipy,numpy,matplotlib三个工具库,分别是用于高级算法,加载数据,矩阵计算以及画图
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
import scipy.optimize as opt2.获取数据
这里先加载ex5data1.mat的数据,然后分别将训练集,交叉集,测试集分别取出做备用,同样在三个分类之后的数据集第一列插入1用来和theta进行矩阵运算
# 获取路径
data = loadmat('ex5data1.mat')
# print(data)
# 一共三组数据,分别是训练集,交叉集以及测试集
X, y = data['X'], data['y'] # 训练集
Xval, yval = data['Xval'], data['yval'] # 交叉集
Xtest, ytest = data['Xtest'], data['ytest'] # 测试集
# print(f"Xtest:{Xtest},ytest:{ytest}")
# 下面在头部插入一列1,方便与theta矩阵相乘从而得到常数项
X = np.insert(X, 0, 1, axis=1) # 此处的含义是在X矩阵中的第0列插入1,axis为0时为行,1为列
Xval = np.insert(Xval, 0, 1, axis=1)
Xtest = np.insert(Xtest, 0, 1, axis=1)下面是已经插入1之后的X数据展示

看一下每一部分的数据集的维度
# 查看一下矩阵维度
# print(f"X.shape:{X.shape} Xval.shape:{Xval.shape} Xtest.shape:{Xtest.shape}")
# print(f"y.shape:{y.shape} yval.shape:{yval.shape} ytest.shape:{ytest.shape}")
3.生成一下X,y对应的视图
需要注意的是这里X并不是全部都取,我们刚刚插入了一列一,所以这里只取第二列的数据,也就是X训练集的原生数据
# 原始图片(数据的位置)
def plotX():
plt.figure(figsize=(13, 6))
plt.scatter(X[:, 1], y, label='test')
plt.xlabel('waterHeight')
plt.xlabel('waterover')
plt.legend()
plt.show()plotX()
4.代价函数
下面可以看出三部分数据集所用的代价函数都是相同的,但我们在写的时候还是需要带上正则化的一项,方便以后处理高阶过拟合的状态以及寻找最合适的theta。

别忘了这里加上正则项

# 代价函数(erro)
def costFunc(theta, X, y, lamda):
theta.shape = (X.shape[1], 1)
costFront = np.square(X @ theta - y).sum()
cost_reg = lamda * (np.square(theta)).sum()
return (costFront + cost_reg) / (2 * len(X))看一下第一次的代价函数值
theta = np.zeros(X.shape[1])
print(costFunc(theta,X,y,0))
5.梯度偏导公式
以前我们用的都是梯度下降算法 ,用theta去对自身进行更新,但这次我们要用一下高级算法,只需要提供梯度的偏导公式即可,高级算法会自动帮我们找到最优解

这里我的思路是先把theta设置为一个俩行一列的矩阵,梯度下降公式的前半部分会得到一个俩行一列的矩阵与后半部分的theta正则化相加,具体就是X.T(2 * 12) * (X(12 * 2) * theta(2 * 1) - y(12 * 1)) -->gradientFront(2*1) + gradient_reg(2 * 1)
这里如果不明白我要这样写的,我建议自己在纸上把所有矩阵画一下,再像上面一样矩阵相乘就会懂啦
# 梯度偏导公式
def gradientFunc(theta, X, y, lamda):
theta.shape = (X.shape[1], 1)
gradientFront = X.T @ (X @ theta - y)
gradient_reg = lamda * theta;
gradient_reg[0] = 0
return (gradientFront + gradient_reg) / (1 * len(X))看一下第一次梯度的值
print(gradientFunc(theta,X,y,1))
6.使用高级算法来找出最优theta
注意,这里传入的theta一定要是ndarray的类型,否则会报错
简单说一下这个算法,其实可以理解为你给他提供了一个代价函数(costFunc),同时又提供了一个梯度偏导函数(gradientFunc),那么这个opt.minimize方法就可以自行迭代然后找出最优的解返回给你,你可以把这个过程想象成梯度下降函数,只是他帮你实现了,当然minimize这个方法一定使用了比梯度下降更好的一些算法,只是我们不再需要深入了解了
# 使用优化方法自行找出优化后的theta
def trainFindMin(theta, X, y, lamda):
result = opt.minimize(fun=costFunc, x0=theta, args=(X, y, lamda), method='TNC',
jac=gradientFunc)
return result.x优化之后的theta值为:可以看出优化后的theta返回值也是ndarray的类型
train_theta = trainFindMin(theta,X,y,0)
print(train_theta)
7.看一下第一次优化所得到的theta对应的图像
需要注意的是,这里的横坐标选取是有些说到的,虽然选取的是X的第一列也就是训练集的原数据,但是在选取高阶的特征值时就不能这样写横坐标了,原因是X的里的数据是随机分布的,并不是从左到右递增的(可以看第2条获取数据那里的X展示),这里能图像没出问题的原因是我们设置的函数是一个一元函数,也就是一条直线,所以无论X的数据如何排列,得到的都是一条线的值,如果是高阶就会有很多弯路或者折返会显的特别乱
# d为2时候欠拟合/高偏差的图像
def plot_theta(train_theta, X):
train_theta.shape = (X.shape[1], 1)
predict_num = X @ train_theta # (12*1)
plotX()
plt.plot(X[:, 1:], predict_num)
plt.show()
returnplot_theta(train_theta,X)
8.学习曲线(用于分析是否是欠拟合还是过拟合状态)
学习曲线的X轴训练集的数量,Y轴就是代价函数的值,就是看随着训练集数量的不断增加,看训练集的代价函数值与交叉集的代价函数值之间的关系,这里X_each是用来获取训练集的长度,依次增加数量,cost_train与cost_cv用来存储训练集与交叉集的代价函数值,for循环中分俩个步骤走:1)通过高级算法找出当前所给出的训练集的最优theta 。2)用得到的theta分别带入训练集与交叉集的代价函数中
注意:这里在记录训练集与交叉集的代价函数时不需要惩罚,lamda置为0
# 看一下学习曲线是欠拟合还是过拟合
def learningCurve(theta, X, y, Xval, yval, lamda):
x_each = np.array(range(1, len(X) + 1)) # 这里加一是因为右区间是开区间,所以这里x_each存的是(1-12)
cost_train = []
cost_cv = []
# theta_temp = []
for i in x_each:
theta_temp = trainFindMin(theta, X[:i, :], y[:i, :], lamda) # 同样这里右边也是开区间,行一直取得是0-(i-1)
cost_train.append(costFunc(theta_temp, X[:i, :], y[:i, :], 0))
cost_cv.append(costFunc(theta_temp, Xval, yval, 0))
plt.plot(x_each, cost_train, label='cost_train', c='r')
plt.plot(x_each, cost_cv, label='cost_cv', c='b')
plt.xlabel('nums of trainset')
plt.ylabel('cost_erro')
plt.legend()
plt.show()学习曲线视图如下:
下面图片可以看出随着训练集数量增加,训练集的代价函数与交叉集的代价函数都会偏高,这明显是欠拟合的状态(高偏差),因为无论怎么增加训练集,俩个数据集误差都很大,不拟合任何一方。如果是训练集的代价函数为零,而交叉集偏高就是过拟合的状态(高方差)
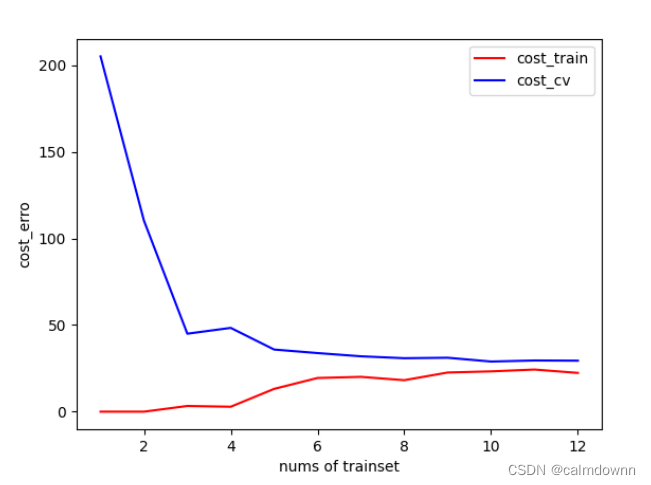
9.修正欠拟合(高偏差)
通过学习曲线可得知是欠拟合的状态,我们就可以提高特征值的维度的方法来修正
# 下面提高d的维度,用以修正欠拟合的状态
def upDegree(X_upDegree, degree):
for i in range(2, degree + 1):
X_upDegree = np.insert(X_upDegree, i, np.power(X_upDegree[:, 1], i), axis=1)
return X_upDegree
10.归一化高维度的数据集
首先获取训练集的平均值与标准差为后面归一化做准备,这里用到了numpy库的俩个经典方法,mean->平均值,std->方差
这里补充一下为什么需要归一化,如果这里不用归一化来让数据控制在更小的范围内,就会出现有的数据集非常大,有的很小,导致计算机运算耗费更多资源,且用lamda在惩罚过拟合状态时也会非常不明显,比如4阶的过拟合的训练集,可能lamda需要跟到10多万才能达到惩罚的效果,如果进行了归一化,就算6阶的过拟合训练集也仅仅需要将lamda赋值10多就会达到修正的效果
# 取得平均值和标准差
def getMeanAndStd(X):
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0, ddof=1)
return X_mean, X_std下面进行归一化操作:
公式为:(数据集 - 平均值)/ 标准差,还是很直观的
# 进行归一化
def normalization(X, mean, std):
X[:, 1:] = (X[:, 1:] - mean[1:]) / std[1:]
return X11.进行高纬度测验
# 高阶测验
X_degree = upDegree(X, 6)
X_mean, X_std = getMeanAndStd(X_degree)
X_normalize = normalization(X_degree, X_mean, X_std)
X_val_degree = upDegree(Xval, 6)
X_val_normalize = normalization(X_val_degree,X_mean,X_std)
theta = np.zeros(X_degree.shape[1])
learningCurve(theta, X_normalize, y, X_val_normalize, yval, 1)
这里让训练集达到6阶并归一化,lamda设为1,学习曲线如下:

下面看一下6维训练集得到的theta在XY轴的图像(此时lamda设的为0,没做惩罚,可以看出拟合度很高)
theta1 = trainFindMin(theta,X_normalize,y,0)
def plot_fit_curve():
x = np.linspace(-80,60,100)
print("x:{}".format(x.shape))
x1 = x.reshape(100,1)
x1 = np.insert(x1,0,values=1,axis=1)
x1 = upDegree(x1,6)
x1 = normalization(x1,X_mean,X_std)
y1 = x1 @ theta1
plt.figure(figsize=(13,8),dpi=50)
plt.scatter(X[:,1],y,marker='x',color = 'red')
# 坐标轴范围
plt.xlim(-100,80)
plt.ylim(-80,60)
# 坐标轴刻度
xtick = np.arange(-100,80,20)
ytick = np.arange(-80,60,20)
plt.xticks(xtick)
plt.yticks(ytick)
plt.xlabel("water height")
plt.ylabel("Water overflow")
plt.plot(x,y1,'b')
plt.show()
plot_fit_curve()
接下来看一下当lamda为100时,学习曲线的图像,可以看出训练集与交叉集的代价都非常大,出现了惩罚过大,欠拟合的状态(高偏差)

下面是lamda为100时的拟合曲线,更直观了

11.试验不同的lamda来确定最合适的theta
我简单说一下这里代码的步骤,首先我们设置不同的lamda,我是按照吴恩达老师给的建议从0.01开始,每次乘2递增,将这些lamda依次带入算法中优化出最好的theta,用这些得到的theta带入训练集和交叉集的代价函数中去并存储起来,然后我们在这一列交叉集的代价函数中找出最小值所对应的lamda值,调用高级算法带入lamda得到对应theta(trainFindMin(theta,X_normalize,y,2.56)),注意这里是归一化的训练集,这个最后得到的theta再带入测试集的代价函数中就得到最终结果了
一句话总结就是:在一群lamda当中,找出能让交叉集代价函数值最小的那个lamda,此时这个lamda所对应的theta可能是最好的状态,带入测试集即可
注意:1.这里记录不同lamda的训练集和交叉集的代价函数值时,同样不需要惩罚
2.我选择的是7阶的训练集,因为我发现7阶所得到的测试集代价函数值和原题给的结果最接近
# 下面试验10个lamda,看看哪一个最贴合
def diffLamda(theta, X_normalize, y, X_val_normalize, yval):
lamda_list = []
cost_train_lamda = []
cost_val_lamda = []
sum1 = 0.01;
for i in range(1, 11):
lamda_list.append(sum1)
sum1 *= 2
for i in lamda_list:
theta_lamda_i = trainFindMin(theta, X_normalize, y, i)
cost_train_lamda.append(costFunc(theta_lamda_i, X_normalize, y, 0))
cost_val_lamda.append(costFunc(theta_lamda_i, X_val_normalize, yval, 0))
plt.plot(lamda_list, cost_train_lamda, c='r')
plt.plot(lamda_list, cost_val_lamda, c='b')
plt.xlabel('lamda')
plt.ylabel('cost_value')
plt.show()
print(cost_val_lamda)diffLamda(theta, X_normalize, y, X_val_normalize, yval)从下面代价集合中也可以看出当lamda等于2.56时,交叉集的代价函数值最小,所以我们选取lamda = 2.56来作为测试集的参数


下面是lamda与俩个训练集的代价函数关系图象,可以看出当lamda处在2-3之间时,cost_val(交叉集)有最小值

12.获取测试集的代价函数
这里选取上面最适合的lamda = 2.56最为参数,并求出测试集的代价函数,原题的答案为3.8599
# 求测试集的代价函数
theta2 = trainFindMin(theta,X_normalize,y,2.56)
cost_test = costFunc(theta2,X_test_normalize,ytest,0)
print(cost_test)![]()
三.全部代码
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
import scipy.optimize as opt
# 获取路径
data = loadmat('ex5data1.mat')
# print(data)
# 一共三组数据,分别是训练集,交叉集以及测试集
X, y = data['X'], data['y'] # 训练集
Xval, yval = data['Xval'], data['yval'] # 交叉集
Xtest, ytest = data['Xtest'], data['ytest'] # 测试集
# print(f"Xtest:{Xtest},ytest:{ytest}")
# 下面在头部插入一列1,方便与theta矩阵相乘从而得到常数项
X = np.insert(X, 0, 1, axis=1) # 此处的含义是在X矩阵中的第0列插入1,axis为0时为行,1为列
Xval = np.insert(Xval, 0, 1, axis=1)
Xtest = np.insert(Xtest, 0, 1, axis=1)
# print(X)
# 查看一下矩阵维度
# print(f"X.shape:{X.shape} Xval.shape:{Xval.shape} Xtest.shape:{Xtest.shape}")
# print(f"y.shape:{y.shape} yval.shape:{yval.shape} ytest.shape:{ytest.shape}")
# 原始图片(数据的位置)
def plotX():
plt.figure(figsize=(13, 6))
plt.scatter(X[:, 1], y, label='test')
plt.xlabel('waterHeight')
plt.xlabel('waterover')
plt.legend()
# plt.show()
# plotX()
# 代价函数(erro)
def costFunc(theta, X, y, lamda):
theta.shape = (X.shape[1], 1)
costFront = np.square(X @ theta - y).sum()
cost_reg = lamda * (np.square(theta)).sum()
return (costFront + cost_reg) / (2 * len(X))
theta = np.zeros(X.shape[1])
# print(costFunc(theta,X,y,0))
# 梯度偏导公式
def gradientFunc(theta, X, y, lamda):
theta.shape = (X.shape[1], 1)
gradientFront = X.T @ (X @ theta - y)
gradient_reg = lamda * theta;
gradient_reg[0] = 0
return (gradientFront + gradient_reg) / (1 * len(X))
# print(gradientFunc(theta,X,y,1))
# 使用优化方法自行找出优化后的theta
def trainFindMin(theta, X, y, lamda):
result = opt.minimize(fun=costFunc, x0=theta, args=(X, y, lamda), method='TNC',
jac=gradientFunc)
return result.x
# train_theta = trainFindMin(theta,X,y,0)
# print(train_theta)
# d为2时候欠拟合/高偏差的图像
def plot_theta(train_theta, X):
train_theta.shape = (X.shape[1], 1)
predict_num = X @ train_theta # (12*1)
plotX()
plt.plot(X[:, 1:], predict_num)
plt.show()
return
# plot_theta(train_theta,X)
# 看一下学习曲线是欠拟合还是过拟合
def learningCurve(theta, X, y, Xval, yval, lamda):
x_each = np.array(range(1, len(X) + 1)) # 这里加一是因为右区间是开区间,所以这里x_each存的是(1-12)
cost_train = []
cost_cv = []
# theta_temp = []
for i in x_each:
theta_temp = trainFindMin(theta, X[:i, :], y[:i, :], lamda) # 同样这里右边也是开区间,行一直取得是0-(i-1)
cost_train.append(costFunc(theta_temp, X[:i, :], y[:i, :], 0))
cost_cv.append(costFunc(theta_temp, Xval, yval, 0))
plt.plot(x_each, cost_train, label='cost_train', c='r')
plt.plot(x_each, cost_cv, label='cost_cv', c='b')
plt.xlabel('nums of trainset')
plt.ylabel('cost_erro')
plt.legend()
plt.show()
# plot_theta(theta_temp,X)
# theta = np.zeros(X.shape[1])
# learningCurve(theta,X,y,Xval,yval,0) # 可以看出训练集和交叉集的误差都挺大,所以是高偏差也就是欠拟合的状态
# 下面提高d的维度,用以修正欠拟合的状态
def upDegree(X_upDegree, degree):
for i in range(2, degree + 1):
X_upDegree = np.insert(X_upDegree, i, np.power(X_upDegree[:, 1], i), axis=1)
return X_upDegree
# 取得平均值和标准差
def getMeanAndStd(X):
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0, ddof=1)
return X_mean, X_std
# print(getMeanAndStd(X))
# 进行归一化
def normalization(X, mean, std):
X[:, 1:] = (X[:, 1:] - mean[1:]) / std[1:]
return X
# 高阶测验
X_degree = upDegree(X, 7)
X_mean, X_std = getMeanAndStd(X_degree)
X_normalize = normalization(X_degree, X_mean, X_std)
X_val_degree = upDegree(Xval, 7)
X_val_normalize = normalization(X_val_degree,X_mean,X_std)
X_test_degree = upDegree(Xtest, 7)
X_test_normalize = normalization(X_test_degree,X_mean,X_std)
theta = np.zeros(X_degree.shape[1])
# learningCurve(theta, X_normalize, y, X_val_normalize, yval, 100) # 在这里可以调节lamda的值来看学习曲线图像的状态
# print(X_normalize)
# plotUpdate(theta,X_normalize,y,1)
# 下面试验10个lamda,看看哪一个最贴合
def diffLamda(theta, X_normalize, y, X_val_normalize, yval):
lamda_list = []
cost_train_lamda = []
cost_val_lamda = []
sum1 = 0.01;
for i in range(1, 11):
lamda_list.append(sum1)
sum1 *= 2
for i in lamda_list:
theta_lamda_i = trainFindMin(theta, X_normalize, y, i)
cost_train_lamda.append(costFunc(theta_lamda_i, X_normalize, y, 0))
cost_val_lamda.append(costFunc(theta_lamda_i, X_val_normalize, yval, 0))
print(f"{i},",end="")
plt.plot(lamda_list, cost_train_lamda, c='r',label = "cost_train")
plt.plot(lamda_list, cost_val_lamda, c='b',label = "cost_val")
plt.xlabel('lamda')
plt.ylabel('cost_value')
plt.legend()
plt.show()
print()
print(cost_val_lamda)
# diffLamda(theta, X_normalize, y, X_val_normalize, yval)
# theta1 = trainFindMin(theta,X_normalize,y,0) # 在这里可以调节lamda的值来看拟合图像的状态
def plot_fit_curve():
x = np.linspace(-80,60,100)
print("x:{}".format(x.shape))
x1 = x.reshape(100,1)
x1 = np.insert(x1,0,values=1,axis=1)
x1 = upDegree(x1,6)
x1 = normalization(x1,X_mean,X_std)
y1 = x1 @ theta1
plt.figure(figsize=(13,8),dpi=50)
plt.scatter(X[:,1],y,marker='x',color = 'red')
# 坐标轴范围
plt.xlim(-100,80)
plt.ylim(-80,60)
# 坐标轴刻度
xtick = np.arange(-100,80,20)
ytick = np.arange(-80,60,20)
plt.xticks(xtick)
plt.yticks(ytick)
plt.xlabel("water height")
plt.ylabel("Water overflow")
plt.plot(x,y1,'b')
plt.show()
# plot_fit_curve()
# 求测试集的代价函数
theta2 = trainFindMin(theta,X_normalize,y,2.56)
cost_test = costFunc(theta2,X_test_normalize,ytest,0)
print(f"测试集的代价函数为:{cost_test}")