
发表于NIPS2017!!!
论文链接:https://proceedings.neurips.cc/paper/2017/file/cb8da6767461f2812ae4290eac7cbc42-Paper.pdf
代码链接:https://github.com/jakesnell/prototypical-networks
1. 问题
小样本分类问题——训练集中没有看到的新类,且每个新类只有少量的例子
2. 贡献
本文主要贡献就是为小样本分类提出一个新的网络——Prototypical Networks,该网络学习一个度量空间,在这个空间中,分类可以通过计算每个类的原型表示的距离来执行
3. 方法
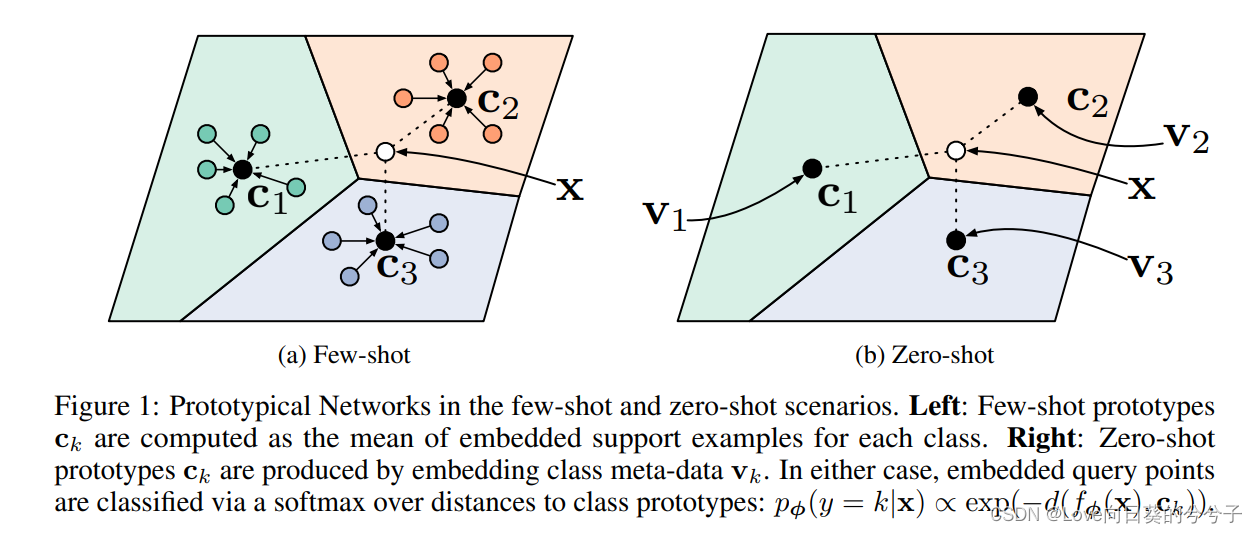
Prototypical Networks通过嵌入函数 f ϕ : R D → R M f_\phi : R^D \rightarrow R^M fϕ:RD→RM和可学参数 ϕ \phi ϕ计算每个类的M维表示 c k ∈ R M c_k \in R^M ck∈RM或原型。每个原型是属于其类被嵌入的support点的平均向量:
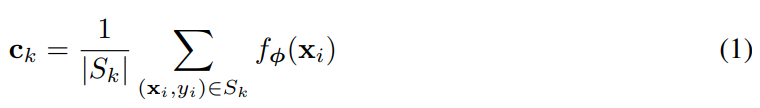
给定距离函数 d : R M × R M → [ 0 , + ∞ ] d:R^M \times R^M\rightarrow [0, +\infty] d:RM×RM→[0,+∞],Prototypical Networks基于嵌入空间中到原型的距离上的softmax为query点 x x x生成一个类分布:
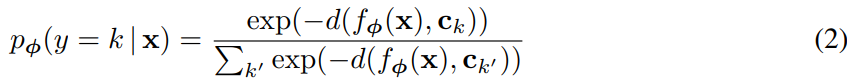
通过SGD求true类 k k k的负对数概率的最小值来继续学习,负对数概率为
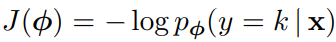
训练集是这样组成的:从训练集中随机选择类的子集,然后在每个类中选择例子的子集作为support集,其余的子集作为query点。

- 与Matching Network对比
原型网络不同于匹配网络,在one-shot机会的情况下,匹配网络具有等价性。在给定支持集的情况下,匹配网络生成加权最近邻分类器,而原型网络使用平方欧氏距离生成线性分类器。在one-shot学习的情况下, c k = x k c_k = x_k ck=xk,因为每个类只有一个support点,匹配网络和原型网络是等价的。
一个很自然的问题是,为每个类使用多个原型而不是一个是否有意义。如果每个类的原型数量是固定的并且大于1,那么这将需要一个分区方案来进一步聚集类中的support点,这已经有工作提出了这一观点;然而,这些工作都需要一个独立的分区阶段,从权重更新解耦,而本文方法是简单的学习与普通梯度下降方法。
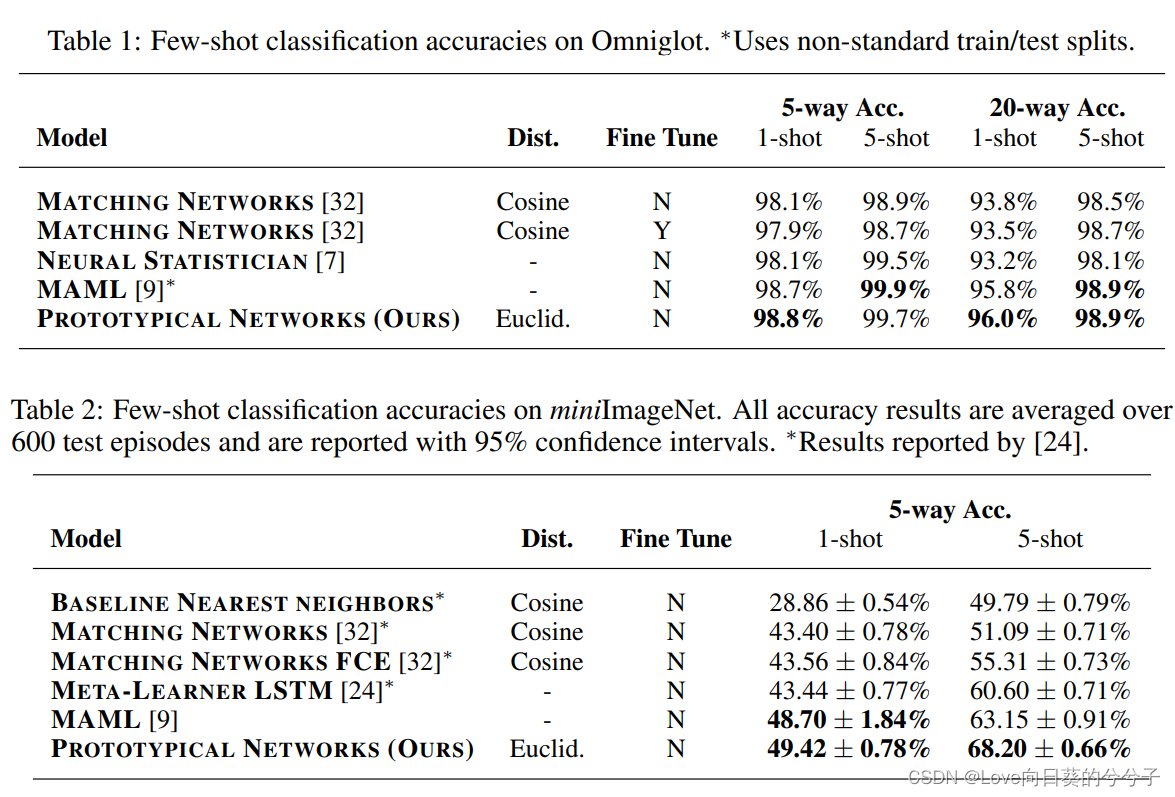
4. 部分实验结果
-
few-shot
-
zero-shot

-
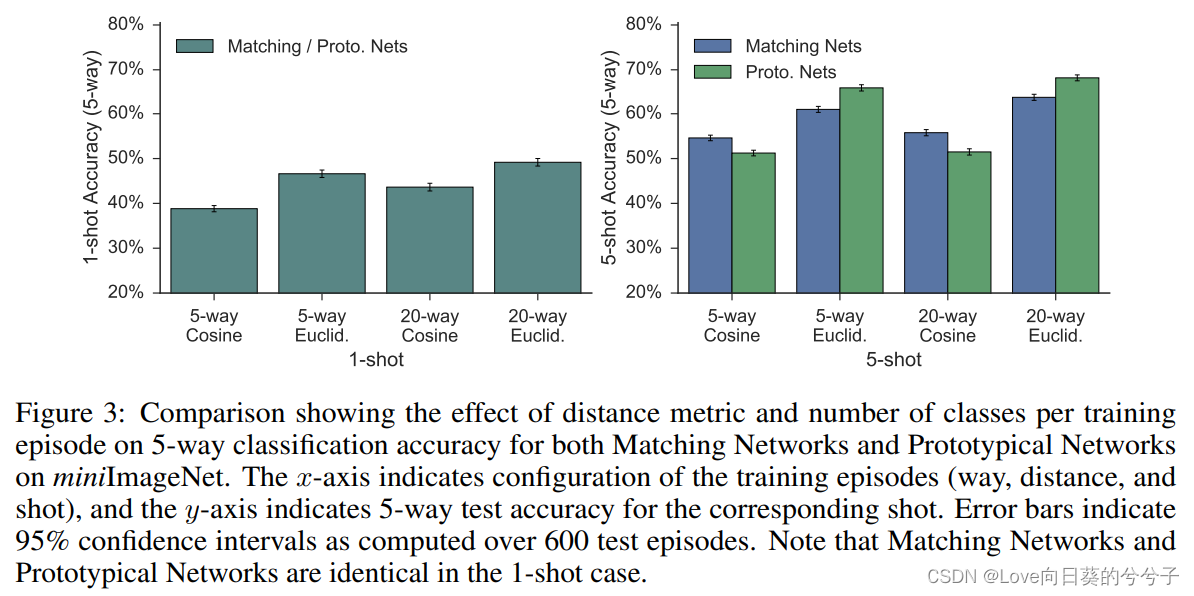
消融实验
5. 结论
1)对于Protypical Networks和Matching Networks,任何距离都是允许的,并且本文发现使用平方欧氏距离可以大大改善这两种网络的结果。对于Protypical Networks,我们猜想这主要是因为余弦距离不是Bregman散度
2)已有工作使用了一种直接构建episodes的方法,即选择 N c N_c Nc类和每个类的 N S N_S NS个support点,以匹配测试时的预期情况。也就是说,如果我们期望在测试时间进行5-way分类和1-shot学习,那么训练集可以由 N c N_c Nc = 5, N S N_S NS = 1组成。然而,我们已经发现,使用更高的 N c N_c Nc或way进行训练比在测试时使用更有益处。在我们的实验中,我们在一个封闭的验证集上调整训练 N c N_c Nc。另一个需要考虑的问题是在训练和测试时是否匹配 N S N_S NS或shot。对于Prototypical Networks,我们发现通常用相同的shot数进行训练和测试是最好的。