- 题目:Few-Shot Learning With Attention-Weighted Graph Convolutional Networks For Hyperspectral Image Classification
- 链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9190752
- 源码:-
- 时间:2020.10
- 会议:ICIP (CCF-C)
- 机构:北航
- 摘要:用CNN学习节点特征,用CNN+自注意力机制学习边特征(局部自注意机制学习了HSI数据的完整关系图结构),节点标签通过GCN在图上以半监督的方式从支持传播到查询集,适合于小样本学习。
- 其他:又是一篇只有4页的小短篇儿
介绍
分类任务:对高光谱图像HSI进行小样本分类
贡献:
- 首先在所有样本关系完整的图上引入GCN的半监督标签传播,这与HSI(高光谱图像)中现有的基于距离计算的小样本方法不同。
- 通过局部自注意机制实现注意加权图,量化HSI小样本分类中所有样本(包括支持集和查询集)之间的关系。实验结果证明了该方法的有效性。
方法
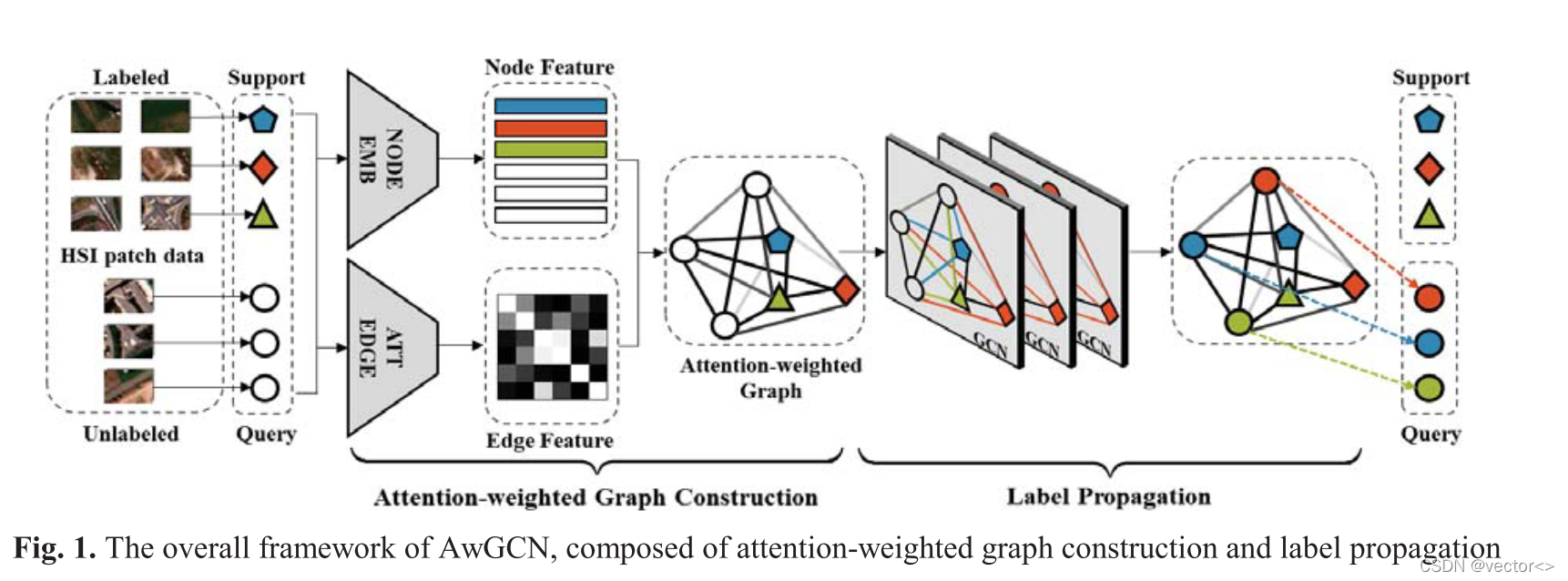
1. 问题定义
- HSI数据集: X = [ x 1 , x 2 , ⋯ , x n ] ∈ R l × w × b X=\left[x_{1}, x_{2}, \cdots, x_{n}\right] \in \mathbb{R}^{l \times w \times b} X=[x1,x2,⋯,xn]∈Rl×w×b
- 数据集标签: Υ = [ y 1 , y 2 , … , y n ] \Upsilon=\left[y_{1}, y_{2}, \ldots, y_{n}\right] Υ=[y1,y2,…,yn]
- l l l 和 w w w 分别为图片的长和宽
- 支持集: S = { ( x i , y i ) } i = 1 N × K S=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N \times K} S={ (xi,yi)}i=1N×K
- 查询集: Q = { ( x i , y i ) } i = N × K + 1 N × K + T Q=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=N \times K+1}^{N \times K+T} Q={ (xi,yi)}i=N×K+1N×K+T
2. 注意力加权图卷积网络
2.1 注意力加权图结构
Node feature
- CNN将输入x映射成为C维的嵌入。
- v i = f φ ( x i ; φ ) v_{i}=f_{\varphi}\left(x_{i} ; \varphi\right) vi=fφ(xi;φ)
Edge feature
- 为边缘特征设计了一种可训练的方式,而不是固定的相似性度量。
- 自注意机制通过注意值自适应量化输入位置之间的关系,无需计算距离。
- 受此思想的启发,本文设计了一个局部自注意机制,仅利用注意权重,以获得一个注意加权边矩阵(AwE),其中每个元素表示一个边缘特征eij。注意权重确定为 Attention_weight ( X ) = softmax ( X X T τ ∣ ) (X)=\operatorname{softmax}\left(\frac{X X^{T}}{\sqrt{\tau \mid}}\right) (X)=softmax(τ∣XXT).
- 同时,采用多头范式,在h个不同的表示子空间中共同参与,以减少随机误差。
Graph construction structure
- 下图中a表示结点嵌入特征网络,b表示提取边特征的自注意力网络结构。
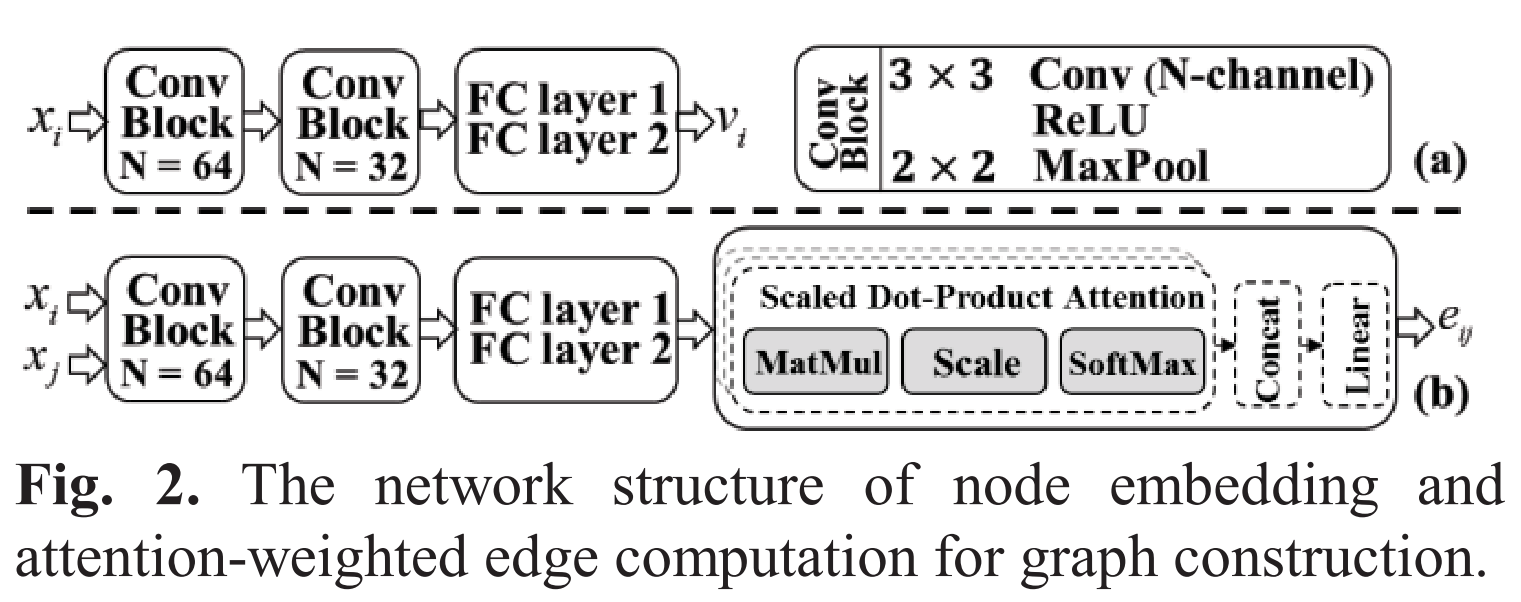
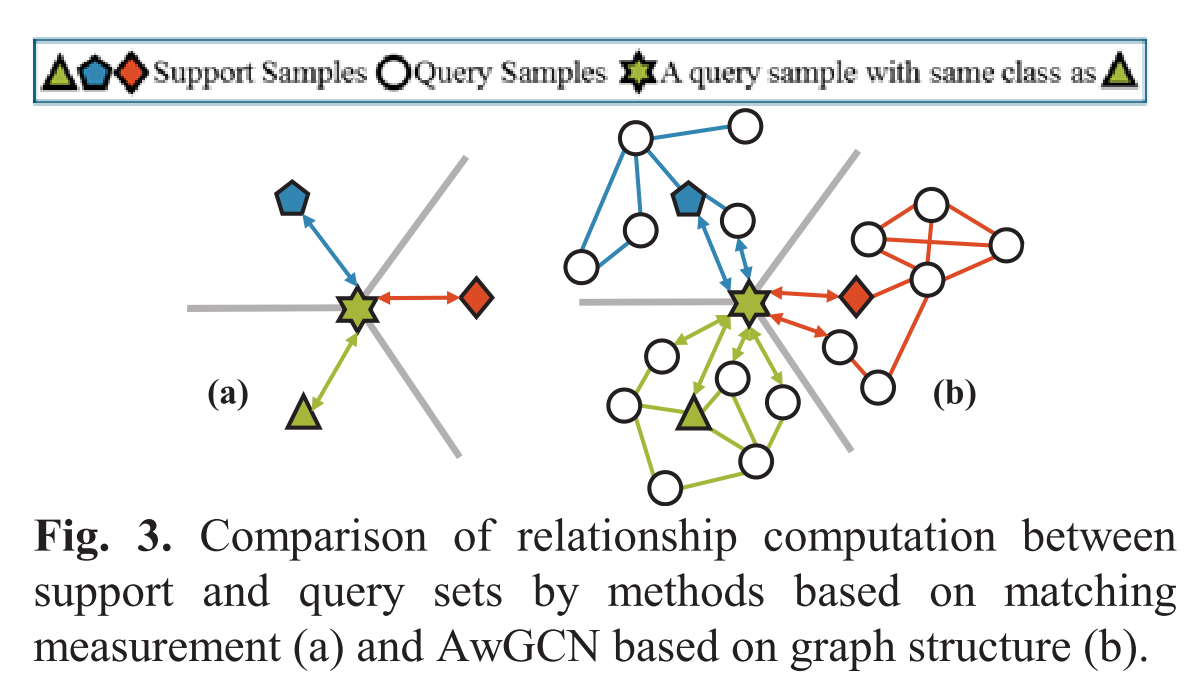
- 不同于现有的依赖于支持集和查询集之间的匹配和比较的方法,图构造输出确定了整个HSI数据之间的关系,如下图。它描述了支持集和查询集中所有示例之间的彻底连接。
- 图作为有用的先验信息,可以通过HSI样本的相关性进行特征提取和聚合,从全局角度更好地服务于半监督标签传播。
Graph construction in episode training
- 损失函数定义: L awe = ∑ i , j = 1 ∣ τ ∣ − e i j log ( σ ( e ^ i j ) ) − ( 1 − e i j ) log ( 1 − σ ( e ^ i j ) ) . \mathcal{L}_{\text {awe }}=\sum_{i, j=1}^{|\tau|}-e_{i j} \log \left(\sigma\left(\hat{e}_{i j}\right)\right)-\left(1-e_{i j}\right) \log \left(1-\sigma\left(\hat{e}_{i j}\right)\right) . Lawe =∑i,j=1∣τ∣−eijlog(σ(e^ij))−(1−eij)log(1−σ(e^ij)).
2.2 标签传播
在构造好了HSI数据的图结构之后,由GCN完成标签传播。
GCN on Attentionweighted Graph
- GCN通过卷积核聚集邻居结点之间的特征。
- 卷积核: g θ ∗ x = θ D ~ − 1 2 A ~ D ~ − 1 2 x g_{\theta} * x=\theta \tilde{D}^{\frac{-1}{2}} \tilde{A} \tilde{D}^{\frac{-1}{2}} x gθ∗x=θD~2−1A~D~2−1x
- 拉普拉斯算子: D ~ − 1 2 A ~ D ~ − 1 2 \tilde{D}^{\frac{-1}{2}} \tilde{A} \tilde{D}^{\frac{-1}{2}} D~2−1A~D~2−1
- H l + 1 = δ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{l+1}=\delta\left(\tilde{D}^{\frac{-1}{2}} \tilde{A} \tilde{D}^{\frac{-1}{2}} H^{(l)} W^{(l)}\right) Hl+1=δ(D~2−1A~D~2−1H(l)W(l))
- H ( l ) H^{(l)} H(l) 是第 l l l 层的输出
- 标记数据和未标记数据的节点特征相互聚合,引导标签流动,对应于边缘特征,这是通过注意加权图上的双层GCN实现的。
- A i j = A j i = 1 2 ( A w E i j ( V ) + A w E j i ( V ) ) A_{i j}=A_{j i}=\frac{1}{2}\left(A w E_{i j}(V)+A w E_{j i}(V)\right) Aij=Aji=21(AwEij(V)+AwEji(V))
- 模型最终描述为: y ^ = softmax ( A ^ ReLU ( A ^ V W ( 0 ) ) W ( 1 ) ) \hat{y}=\operatorname{softmax}\left(\hat{A} \operatorname{ReLU}\left(\hat{A} V W^{(0)}\right) W^{(1)}\right) y^=softmax(A^ReLU(A^VW(0))W(1))
Label propagation in episode training
- 在每一个episode中计算所有有标签样本的损失: L l p ( y l , y ^ l ) = − ∑ l ∈ L y l In y ^ l \mathcal{L}_{l p}\left(y_{l}, \hat{y}_{l}\right)=-\sum_{l \in L} y_{l} \operatorname{In} \hat{y}_{l} Llp(yl,y^l)=−∑l∈LylIny^l
- 训练过程分为两部分,训练任务中的支持集和查询集都有ground-truth,而测试任务中的查询集是无标签的。
- 首先,用训练样本初始化模型,其收敛速度很快。
- 然后,预测测试任务中未标记的查询数据,损失仅仅是在标记支持集上计算的。
实验
三个HSI小样本数据集:
- Indian Pines (IP)
- Pavia Center (PC)
- University of Pavia (UP)
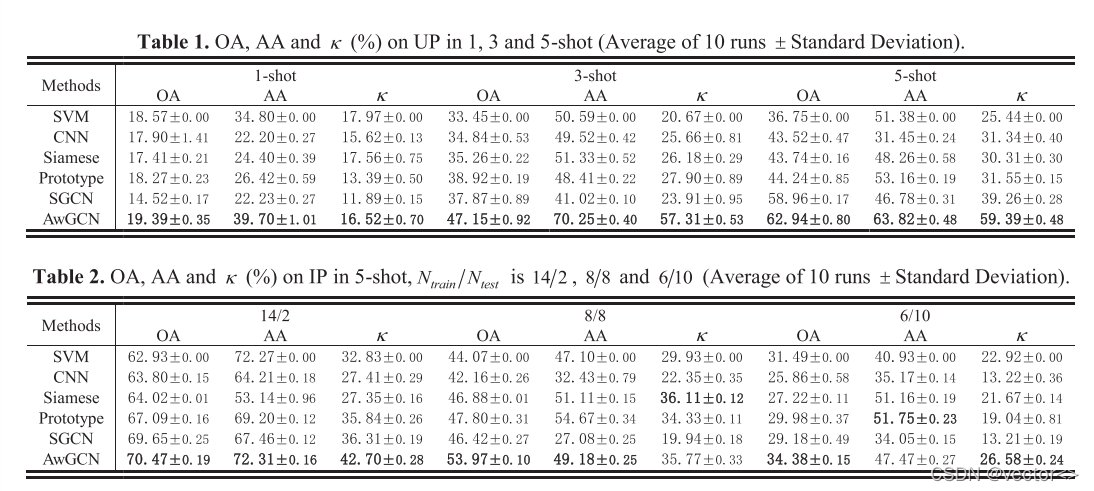
实验结果:
结论
- 在本文中,提出了一个用于HSI小样本分类的AwGCN,包括注意加权图的构造和标签的传播。
- 局部自注意机制学习了HSI数据的完整关系图结构。
- 节点标签通过GCN在图上以半监督的方式从支持传播到查询集,适合于小样本学习。
- 在未来的工作中,我们将节省我们的影响,寻求一种更高效的端到端网络,结合两个损失函数,同时升级图结构和预测