目录
1. 介绍
Resnet 提出的残差结构,在理论上已经将网络的深度提升到了不可思议的程度。而深度是和模型的性能挂钩的,正因为这样,网络的性能早已达到了期望的要求。
人工智能是为了用户服务的,网络的深注定了网络只能再昂贵的实验室才可以运行,或者部署到云端进行计算。为了实现边缘计算,即在用户身边就能实时反应出结果,不需要传递给云端的服务器。所以神经网络的轻量化、便捷化和计算量小是现在网络努力的方向之一
MobileNet V1就是专注于移动端或者嵌入式设备这种计算量不是特别大的轻量级CNN网络
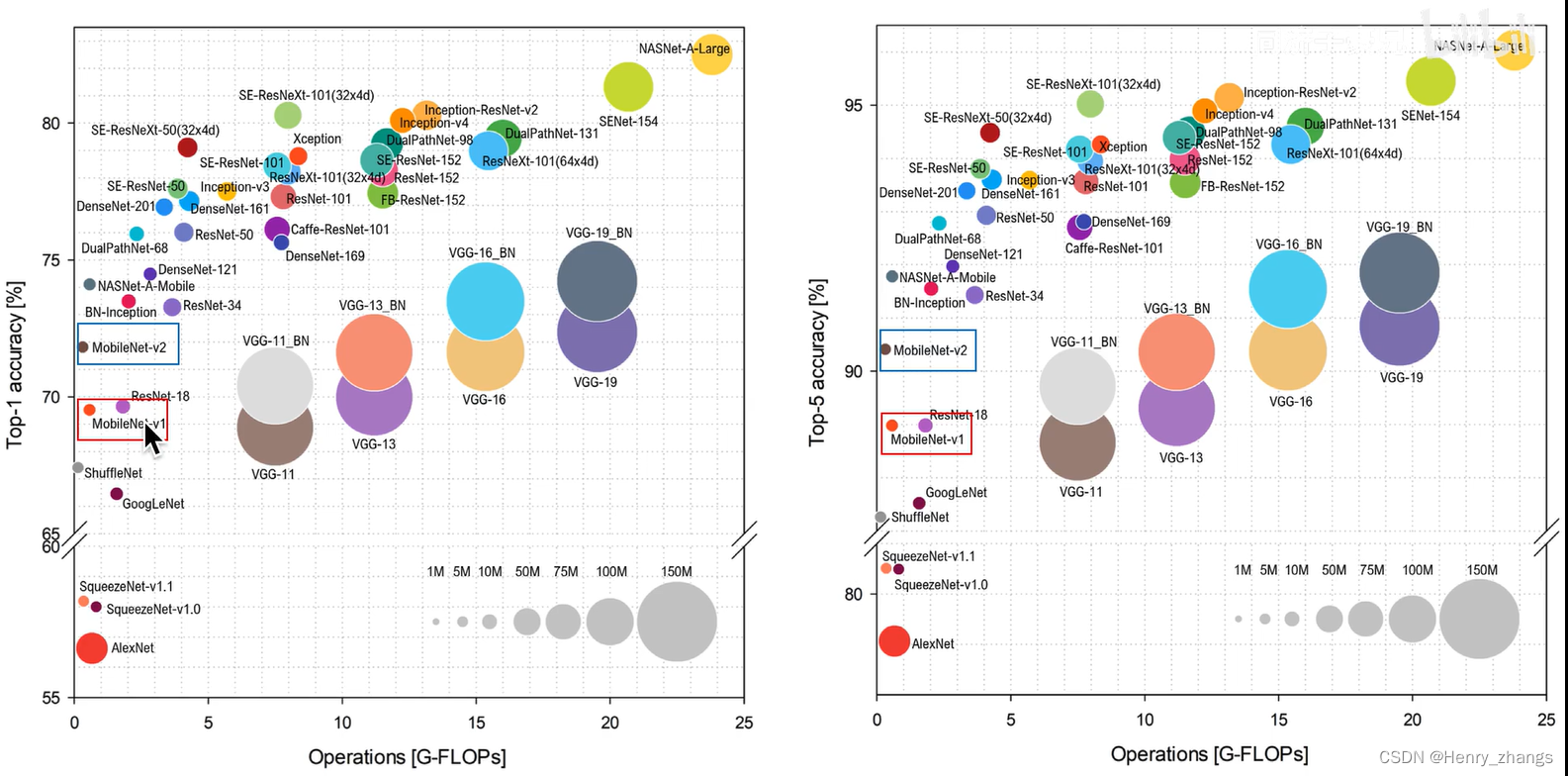
如图,MobileNet V1只是牺牲了一点精度,却大大减少模型的参数量和运算量
2. MobileNet V1 亮点
首先是深度可分离卷积可以大大减少运算量和参数量,其次就是增加超参数α、ρ可以根据需求调节网络的结构
2.1 深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution):depthwise(深度卷积)+pointwise(点卷积)
depthwise :在空间上进行卷积
pointwise : 在深度上进行卷积
普通的卷积是kernel_size ,然后输入的channel,输出的channel是四维的
而深度可分离卷积分为了两个部分,深度卷积是卷积核单独对输入通道进行卷积,例如输入是3维的,那么就用3个kernel_size的卷积进行深度卷积。然后输出的话,用1*1的点卷积进行融合,这样又是一个1*1*out_channel的卷积。
这样参数和计算量就会被大大的减少
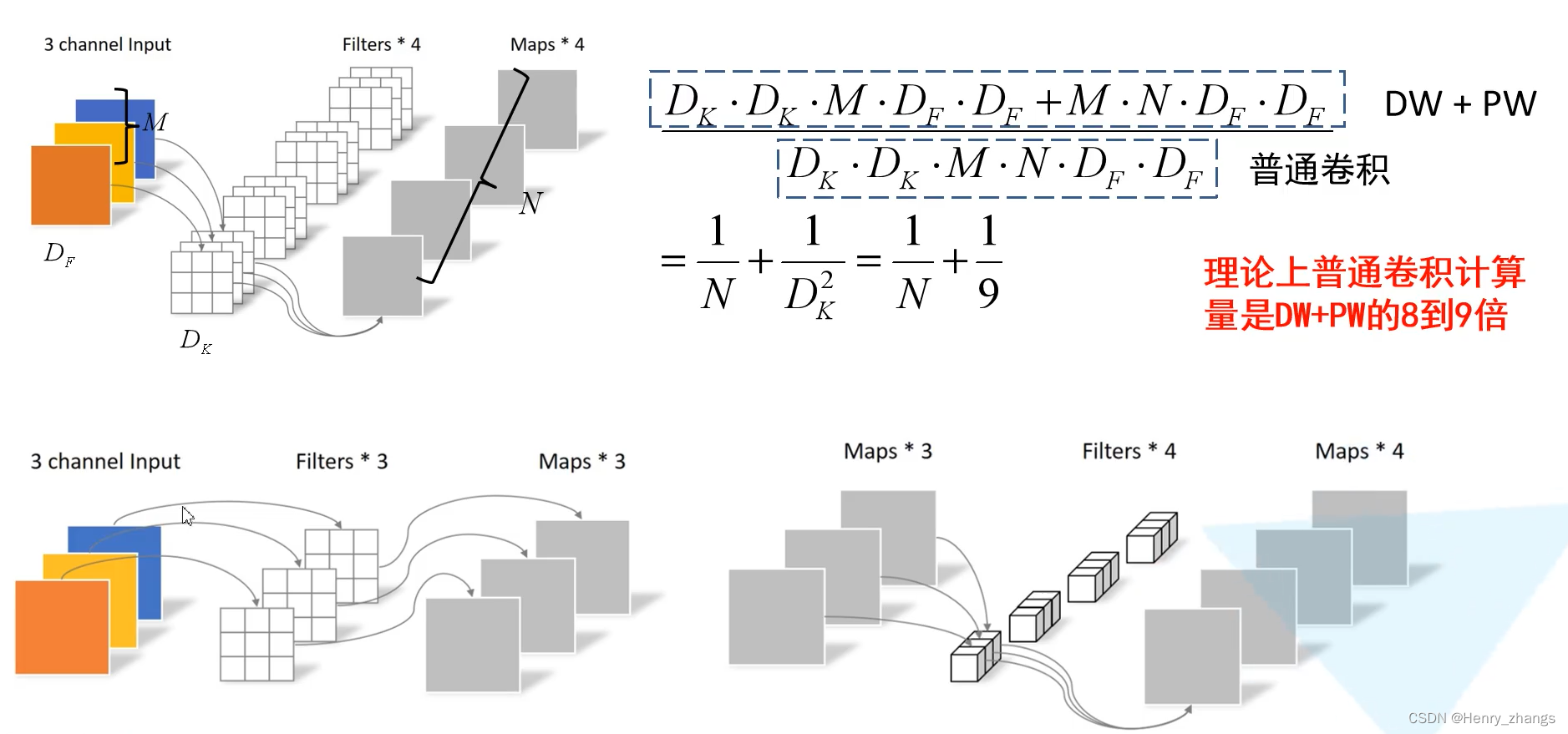
实现的过程如下:

2.2 超参数
至于α和ρ这两个超参数是为了控制网络的宽度和分辨率的
网络的宽度,代表卷积层的个数,也就是channel,之前的channel都是512,1024这种
网络的深度,就是卷积层的层数,也就是网络有多深,例如resnet34、resnet101这样
所以α(0-1)就是为了控制卷积核的个数,也就是输出的channel,因此α可以减少模型的参数
ρ是为了控制图像输入的size,是不会影响模型的参数,但是可以减少运算量
3. MobileNet V1网络
网络的结构如图:
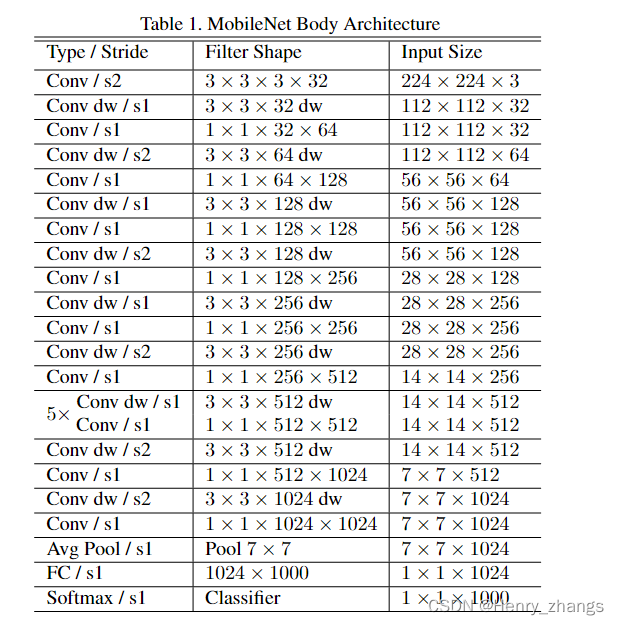
代码为:实现的方式很简单,对着结构图就行了
import torch.nn as nn
# MobileNetV1
class MobileNetV1(nn.Module):
def __init__(self,num_classes=1000):
super(MobileNetV1, self).__init__()
# 第一层的卷积,channel->32,size减半
def conv_bn(in_channel, out_channel, stride):
return nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, stride, 1, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
# 深度可分离卷积=depthwise卷积 + pointwise卷积
def conv_dw(in_channel, out_channel, stride):
return nn.Sequential(
# depthwise 卷积,channel不变,stride = 2的时候,size减半
nn.Conv2d(in_channel, in_channel, 3, stride, padding=1, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel),
nn.ReLU(inplace=True),
# pointwise卷积(1*1卷积) same卷积, 只改变channel
nn.Conv2d(in_channel, out_channel, 1, 1, padding=0, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn(3, 32, 2), # conv/s2 out=224*224*32
conv_dw(32, 64, 1), # conv dw +1*1 out=112*112*64
conv_dw(64, 128, 2), # conv dw +1*1 out=56*56*128
conv_dw(128, 128, 1), # conv dw +1*1 out=56*56*128
conv_dw(128, 256, 2), # conv dw +1*1 out=28*28*256
conv_dw(256, 256, 1), # conv dw +1*1 out=28*28*256
conv_dw(256, 512, 2), # conv dw +1*1 out=14*14*512
conv_dw(512, 512, 1), # 5个 conv dw +1*1 ----> size不变,channel不变,out=14*14*512
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2), # conv dw +1*1 out=7*7*1024
conv_dw(1024, 1024, 1), # conv dw +1*1 out=7*7*1024
nn.AvgPool2d(7), # avg pool out=1*1*1024
)
self.fc = nn.Linear(1024, num_classes) # fc
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
4. torchsummary
安装方式
pip install torchsummary
可以查看网络的结构
方式如下:
from torchsummary import summary
import torch
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
net = MobileNetV1()
net.to(DEVICE)
print(summary(net, input_size=(3, 224, 224),device=DEVICE))
这里的input默认是在cuda上,所以这里需要根据自己的设备看情况选择:
![]()
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
ReLU-3 [-1, 32, 112, 112] 0
Conv2d-4 [-1, 32, 112, 112] 288
BatchNorm2d-5 [-1, 32, 112, 112] 64
ReLU-6 [-1, 32, 112, 112] 0
Conv2d-7 [-1, 64, 112, 112] 2,048
BatchNorm2d-8 [-1, 64, 112, 112] 128
ReLU-9 [-1, 64, 112, 112] 0
Conv2d-10 [-1, 64, 56, 56] 576
BatchNorm2d-11 [-1, 64, 56, 56] 128
ReLU-12 [-1, 64, 56, 56] 0
Conv2d-13 [-1, 128, 56, 56] 8,192
BatchNorm2d-14 [-1, 128, 56, 56] 256
ReLU-15 [-1, 128, 56, 56] 0
Conv2d-16 [-1, 128, 56, 56] 1,152
BatchNorm2d-17 [-1, 128, 56, 56] 256
ReLU-18 [-1, 128, 56, 56] 0
Conv2d-19 [-1, 128, 56, 56] 16,384
BatchNorm2d-20 [-1, 128, 56, 56] 256
ReLU-21 [-1, 128, 56, 56] 0
Conv2d-22 [-1, 128, 28, 28] 1,152
BatchNorm2d-23 [-1, 128, 28, 28] 256
ReLU-24 [-1, 128, 28, 28] 0
Conv2d-25 [-1, 256, 28, 28] 32,768
BatchNorm2d-26 [-1, 256, 28, 28] 512
ReLU-27 [-1, 256, 28, 28] 0
Conv2d-28 [-1, 256, 28, 28] 2,304
BatchNorm2d-29 [-1, 256, 28, 28] 512
ReLU-30 [-1, 256, 28, 28] 0
Conv2d-31 [-1, 256, 28, 28] 65,536
BatchNorm2d-32 [-1, 256, 28, 28] 512
ReLU-33 [-1, 256, 28, 28] 0
Conv2d-34 [-1, 256, 14, 14] 2,304
BatchNorm2d-35 [-1, 256, 14, 14] 512
ReLU-36 [-1, 256, 14, 14] 0
Conv2d-37 [-1, 512, 14, 14] 131,072
BatchNorm2d-38 [-1, 512, 14, 14] 1,024
ReLU-39 [-1, 512, 14, 14] 0
Conv2d-40 [-1, 512, 14, 14] 4,608
BatchNorm2d-41 [-1, 512, 14, 14] 1,024
ReLU-42 [-1, 512, 14, 14] 0
Conv2d-43 [-1, 512, 14, 14] 262,144
BatchNorm2d-44 [-1, 512, 14, 14] 1,024
ReLU-45 [-1, 512, 14, 14] 0
Conv2d-46 [-1, 512, 14, 14] 4,608
BatchNorm2d-47 [-1, 512, 14, 14] 1,024
ReLU-48 [-1, 512, 14, 14] 0
Conv2d-49 [-1, 512, 14, 14] 262,144
BatchNorm2d-50 [-1, 512, 14, 14] 1,024
ReLU-51 [-1, 512, 14, 14] 0
Conv2d-52 [-1, 512, 14, 14] 4,608
BatchNorm2d-53 [-1, 512, 14, 14] 1,024
ReLU-54 [-1, 512, 14, 14] 0
Conv2d-55 [-1, 512, 14, 14] 262,144
BatchNorm2d-56 [-1, 512, 14, 14] 1,024
ReLU-57 [-1, 512, 14, 14] 0
Conv2d-58 [-1, 512, 14, 14] 4,608
BatchNorm2d-59 [-1, 512, 14, 14] 1,024
ReLU-60 [-1, 512, 14, 14] 0
Conv2d-61 [-1, 512, 14, 14] 262,144
BatchNorm2d-62 [-1, 512, 14, 14] 1,024
ReLU-63 [-1, 512, 14, 14] 0
Conv2d-64 [-1, 512, 14, 14] 4,608
BatchNorm2d-65 [-1, 512, 14, 14] 1,024
ReLU-66 [-1, 512, 14, 14] 0
Conv2d-67 [-1, 512, 14, 14] 262,144
BatchNorm2d-68 [-1, 512, 14, 14] 1,024
ReLU-69 [-1, 512, 14, 14] 0
Conv2d-70 [-1, 512, 7, 7] 4,608
BatchNorm2d-71 [-1, 512, 7, 7] 1,024
ReLU-72 [-1, 512, 7, 7] 0
Conv2d-73 [-1, 1024, 7, 7] 524,288
BatchNorm2d-74 [-1, 1024, 7, 7] 2,048
ReLU-75 [-1, 1024, 7, 7] 0
Conv2d-76 [-1, 1024, 7, 7] 9,216
BatchNorm2d-77 [-1, 1024, 7, 7] 2,048
ReLU-78 [-1, 1024, 7, 7] 0
Conv2d-79 [-1, 1024, 7, 7] 1,048,576
BatchNorm2d-80 [-1, 1024, 7, 7] 2,048
ReLU-81 [-1, 1024, 7, 7] 0
AvgPool2d-82 [-1, 1024, 1, 1] 0
Linear-83 [-1, 1000] 1,025,000
================================================================
Total params: 4,231,976
Trainable params: 4,231,976
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 115.43
Params size (MB): 16.14
Estimated Total Size (MB): 132.15
----------------------------------------------------------------
None
5. 训练train
训练的代码一样
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from model import MobileNetV1
from torch.utils.data import DataLoader
from tqdm import tqdm
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
data_transform = {
"train" : transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.255])]),
"test": transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])}
# 训练集
trainset = datasets.CIFAR10(root='./data', train=True, download=False, transform=data_transform['train'])
trainloader = DataLoader(trainset, batch_size=16, shuffle=True)
# 测试集
testset = datasets.CIFAR10(root='./data', train=False, download=False, transform=data_transform['test'])
testloader = DataLoader(testset, batch_size=16, shuffle=False)
# 样本的个数
num_trainset = len(trainset) # 50000
num_testset = len(testset) # 10000
# 构建网络
net =MobileNetV1(num_classes=10)
net.to(DEVICE)
# 加载损失和优化器
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './MobileNetV1.pth'
for epoch in range(10):
net.train() # 训练模式
running_loss = 0.0
for data in tqdm(trainloader):
images, labels = data
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
out = net(images) # 总共有三个输出
loss = loss_function(out,labels)
loss.backward() # 反向传播
optimizer.step()
running_loss += loss.item()
# test
net.eval() # 测试模式
acc = 0.0
with torch.no_grad():
for test_data in tqdm(testloader):
test_images, test_labels = test_data
test_images, test_labels = test_images.to(DEVICE), test_labels.to(DEVICE)
outputs = net(test_images)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == test_labels).sum().item()
accurate = acc / num_testset
train_loss = running_loss / num_trainset
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, train_loss, accurate))
if accurate > best_acc:
best_acc = accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
6. 训练日志
100%|██████████| 3125/3125 [12:43<00:00, 4.09it/s]
100%|██████████| 625/625 [01:01<00:00, 10.24it/s]
[epoch 1] train_loss: 0.098 test_accuracy: 0.527
100%|██████████| 3125/3125 [13:01<00:00, 4.00it/s]
100%|██████████| 625/625 [01:03<00:00, 9.88it/s]
[epoch 2] train_loss: 0.075 test_accuracy: 0.631
100%|██████████| 3125/3125 [13:08<00:00, 3.96it/s]
100%|██████████| 625/625 [01:05<00:00, 9.50it/s]
[epoch 3] train_loss: 0.062 test_accuracy: 0.696
100%|██████████| 3125/3125 [12:56<00:00, 4.03it/s]
100%|██████████| 625/625 [01:02<00:00, 10.00it/s]
[epoch 4] train_loss: 0.053 test_accuracy: 0.730
100%|██████████| 3125/3125 [13:20<00:00, 3.90it/s]
100%|██████████| 625/625 [01:06<00:00, 9.35it/s]
[epoch 5] train_loss: 0.046 test_accuracy: 0.751
100%|██████████| 3125/3125 [13:19<00:00, 3.91it/s]
100%|██████████| 625/625 [01:03<00:00, 9.88it/s]
[epoch 6] train_loss: 0.040 test_accuracy: 0.777
100%|██████████| 3125/3125 [13:20<00:00, 3.90it/s]
100%|██████████| 625/625 [01:01<00:00, 10.10it/s]
[epoch 7] train_loss: 0.035 test_accuracy: 0.790
100%|██████████| 3125/3125 [13:00<00:00, 4.01it/s]
100%|██████████| 625/625 [01:01<00:00, 10.11it/s]
[epoch 8] train_loss: 0.030 test_accuracy: 0.802
100%|██████████| 3125/3125 [13:27<00:00, 3.87it/s]
100%|██████████| 625/625 [01:05<00:00, 9.59it/s]
[epoch 9] train_loss: 0.025 test_accuracy: 0.805
100%|██████████| 3125/3125 [13:23<00:00, 3.89it/s]
100%|██████████| 625/625 [01:02<00:00, 10.02it/s]
[epoch 10] train_loss: 0.021 test_accuracy: 0.803
Finished Training
7. MobileNet V1 在CIFAR10 的表现
代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import numpy as np
import matplotlib.pyplot as plt
from model import MobileNetV1
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
import torchvision
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 预处理
transformer = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])
# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MobileNetV1(num_classes=10)
model.load_state_dict(torch.load('./MobileNetV1.pth'))
model.to(DEVICE)
# 加载数据
testSet = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)
# 获取一批数据
imgs, labels = next(iter(testLoader))
imgs = imgs.to(DEVICE)
# show
with torch.no_grad():
model.eval()
prediction = model(imgs) # 预测
prediction = torch.max(prediction, dim=1)[1]
prediction = prediction.data.cpu().numpy()
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs, labels)):
x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像
x[:, :, 0] = x[:, :, 0] * 0.229 + 0.485 # 去 normalization
x[:, :, 1] = x[:, :, 1] * 0.224 + 0.456 # 去 normalization
x[:, :, 2] = x[:, :, 2] * 0.255 + 0.406 # 去 normalization
y = label.numpy().item() # label
plt.subplot(3, 4, i + 1)
plt.axis(False)
plt.imshow(x)
plt.title('R:{},P:{}'.format(classes[y], classes[prediction[i]]))
plt.show()
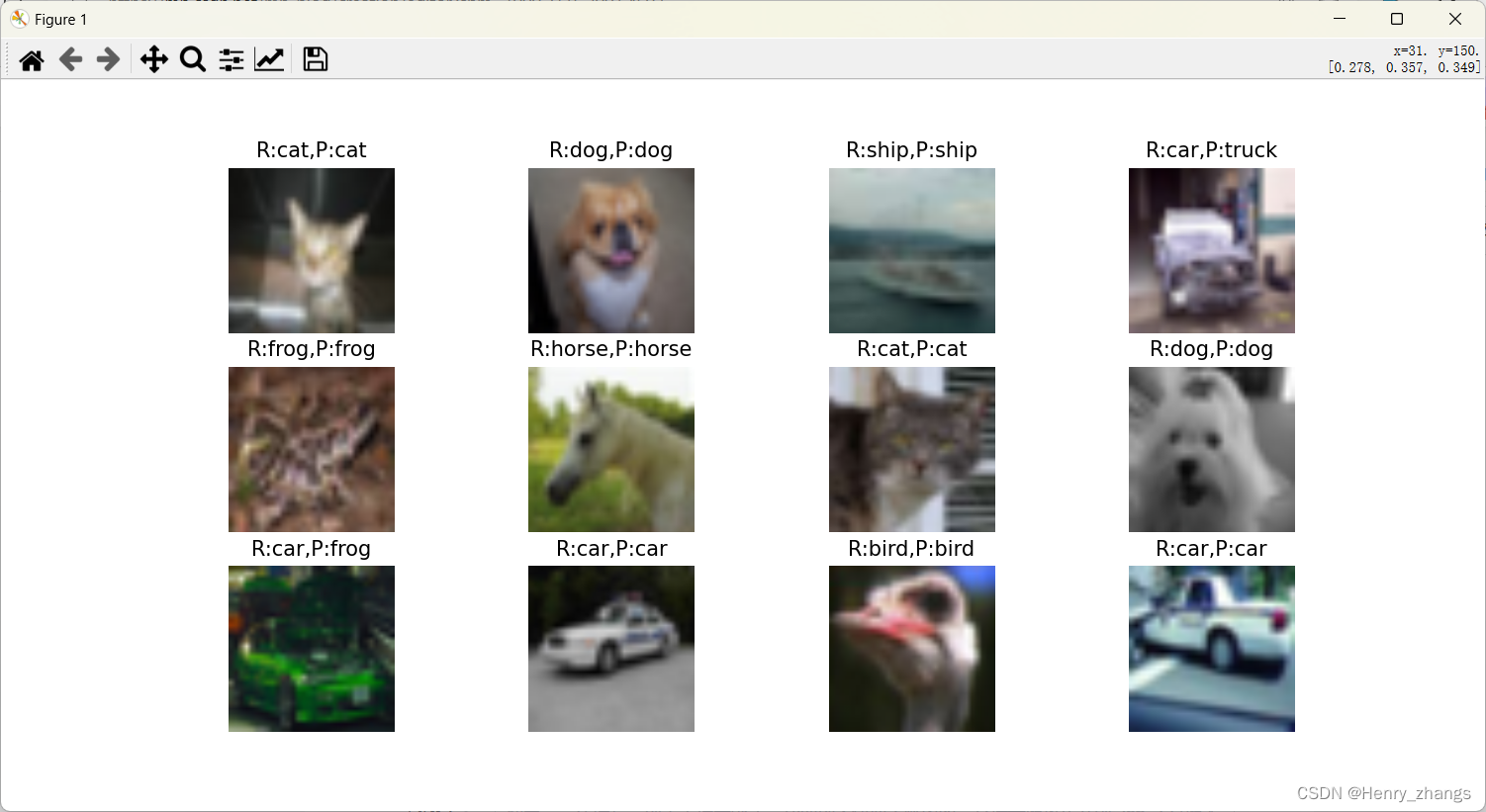
结果展示:
8. 查看参数值
具体可以看:关于迁移学习的方法
from model import MobileNetV1
import torch
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
net = MobileNetV1(num_classes=10)
net.load_state_dict(torch.load('./MobileNetV1.pth'))
net.to(DEVICE)
with torch.no_grad():
for i in range(0,14): # 查看 depthwise 的权值
print(net.model[i][0].weight)