论文地址:https://arxiv.org/abs/1704.04861
Introduction
自从AlexNet在2012年赢得ImageNet大赛的冠军一来,卷积神经网络就在计算机视觉领域变得越来越流行,一个主要趋势就是为了提高准确率就要做更深和更复杂的网络模型,然而这样的模型在规模和速度方面显得捉襟见肘,在许多真实场景,比如机器人、自动驾驶、增强现实等,
识别任务及时地在一个计算力有限的平台上完成,这是我们的大模型的局限性所在。
目前针对这一问题的研究主要是从两个方面来进行的:一是对复杂模型采取剪枝、量化、权重共享等方法,压缩模型得到小模型,这一部分的内容我已经在上篇博客中做了概括,感兴趣的同学可以阅读一下:https://blog.csdn.net/h__ang/article/details/88072278 ;二就是直接设计小模型进行训练。

本次要介绍的就是小模型中的一个代表作MobileNet v1,它是一种基于流水线结构,使用深度级可分离卷积构建的轻量级神经网络,并通过两个超参数的引入使得开发人员可以基于自己的应用和资源限制选择合适的模型。
Depthwise Separable Convolution
MobileNet是基于深度级可分离卷积构建的网络,其实这种结构最早是出现在GoogleNet v3的inception中,它是将标准卷积拆分为了两个操作:深度卷积(depthwise convolution) 和 逐点卷积(pointwise convolution),Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。

下面我们来分析一下两种卷积方式的计算量差异:
如上图所示:输入尺寸为 DF x DF x M,标准卷积核的尺寸为 DK x DK x M x N
- 采用标准卷积核进行卷积,步长为1且padding,那么输出尺寸应该为 DF x DF x N,计算量为 DK x DK x M x N x DF x DF;
- 采用depthwise separable convolution的方式进行卷积,先使用 M个Depthwise Convolutional Filter对输入的M个通道分别进行卷积得到尺寸为 DF x DF x M,这一步的计算量为 DK x DK x M x DF x DF;再使用N个 1 x 1 x M的卷积核进行逐点卷积得到输出尺寸为 DF x DF x M x N,这一步的计算量为 M x N x DF x DF;故总的计算量为 DK x DK x M x DF x DF + M x N x DF x DF。
第二种卷积方式的计算量与第一种相比:
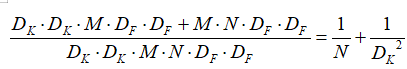
一般情况下N取值比较大,那么如果采用 3 x 3 卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。
Network Structure and Training
在实际使用深度级可分离卷积核时,我们加了BN和ReLU,其和标准卷积结构对比如下:

MobileNet的网络结构如下表1所示,一共由28层构成(不包括Avg Pool和FC层,且把深度卷积和逐点卷积分开算),其除了第一层采用的是标准卷积核之外,剩下的卷积层都用的是 Depth wise Separable Convolution。
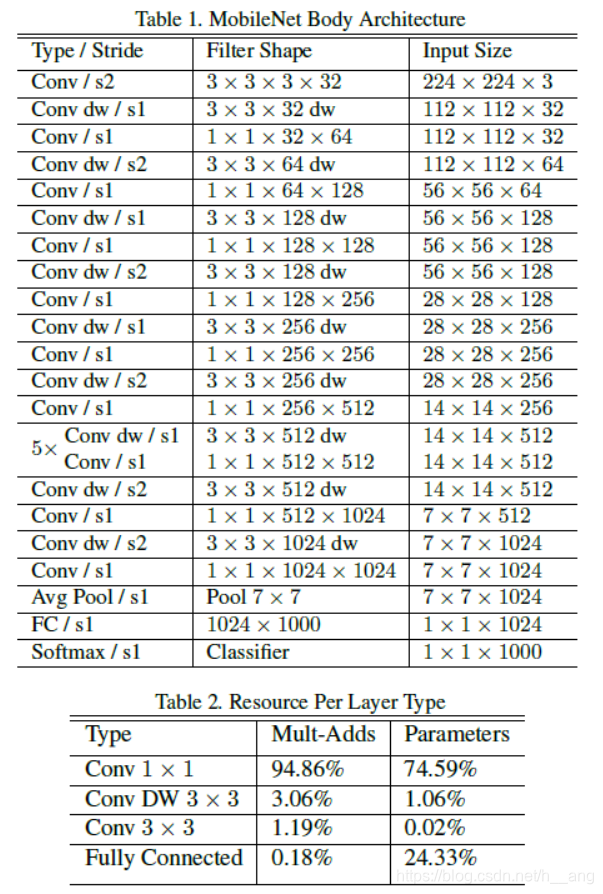
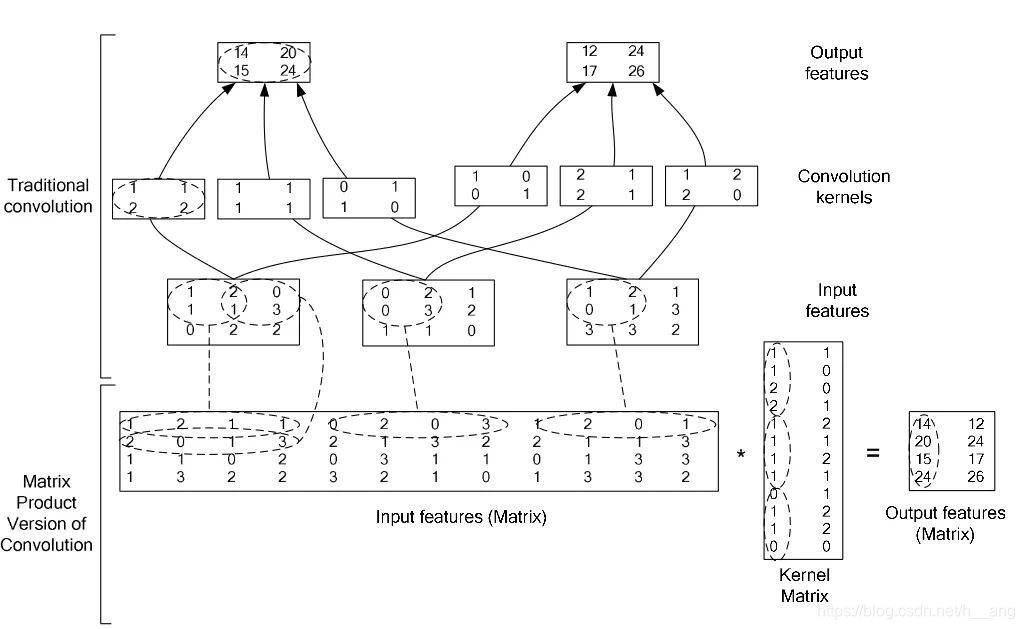
单纯的根据乘加运算的计算量来衡量网络是远远不够的,举个例子,非结构化的稀疏矩阵的计算并不一定比密集矩阵的计算快很多,除非稀疏化程度够高。我们知道,矩阵乘法一般都是通过General Matrix Multiply Functions的方法来进行计算的,但是在进行卷积前要先通过一种叫做im2col的方法对原来的卷积核和输入进行重新排序才可以进行矩阵乘法,其原理如下图所示。而如果我使用的是 1 x 1 的卷积核就不需要重新排序,这就是最优化的数值线性代数算法。如上表2,MobileNet有95%的计算量和74.59%的参数集中在 1 x 1 的卷积层上,而且几乎另外的参数也都在全连接层上。
 在TensorFlow中使用类似InceptionV3 的异步梯度下降RMSprop对MobileNet做训练。与训练大模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
在TensorFlow中使用类似InceptionV3 的异步梯度下降RMSprop对MobileNet做训练。与训练大模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
RMSprop的相关介绍:https://blog.csdn.net/willduan1/article/details/78070086
Width Mutiplier:Thinner Models
虽然MobileNet网络结构和延迟已经比较小了,但是很多时候在特定应用下还是需要更小更快的模型,为此引入了宽度因子 alpha(Width Mutiplier)在每一层对网络的输入输出通道数进行缩减,输入通道数由 M 到 alphaM,输出通道数由 N 到 alphaN,变换后的计算量变为: DK x DK x alpha x M x DF x DF + alpha x M x alpha x N x DF x DF;
通常alpha在(0, 1]之间,比较典型的值有 1, 0.75, 0.5 和 0.25。计算量和参数数量减少程度与未使用宽度因子之前提高了1/alpha**2倍。
Resolution Multiplier: Reduced Representation
我们引入的第二个控制模型大小的超参数是:分辨率因子ρ(resolution multiplier ),用于控制输入和内部层表示,即用分辨率因子控制输入的分辨率。
深度卷积和逐点卷积的计算量:
DK x DK x alpha x M x ρ x DF x ρ x DF + alpha x M x alpha x N x ρ x DF x ρ x DF;
通常 ρ在(0, 1]之间,比较典型的输入分辨为224、192、160、128。计算量量减少程度与未使用宽度因子之前提高了1/(alpha2 x ρ x ρ)倍,参数量没有影响。**
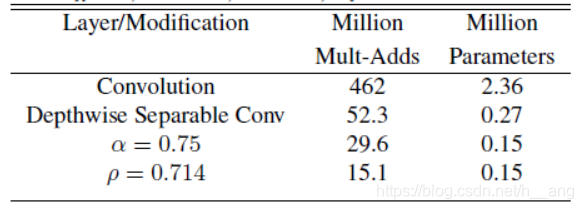
上表中的各种不同设置下的乘积运算量和参数量都是在 DK = 3, M = N = 512, DF = 14下得到的。
Experiments
1. Model Choices

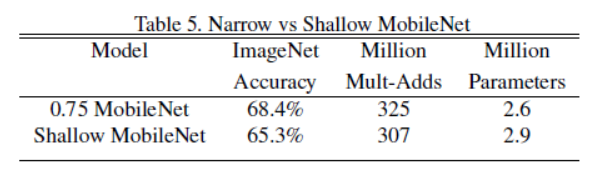
上面的Shallow MobileNet是把前五层 14 x 14 x 512 的可分离的卷积核去掉了
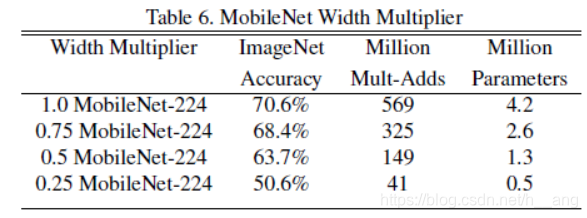
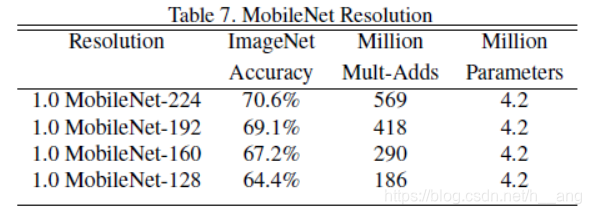
2. Model Shrinking Hyperparameters
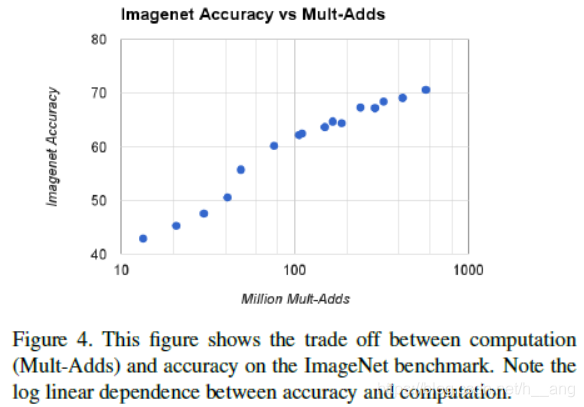
Figure4展示了当宽度因子分别取{1, 0.75, 0.5, 0.25},分辨率因子分别取{224, 192, 160, 128}时组合的16中模型对应准确率和计算量之间呈现出一种对数-线性关系,转折点是在宽度因子取0.25时有一个"跳跃"。
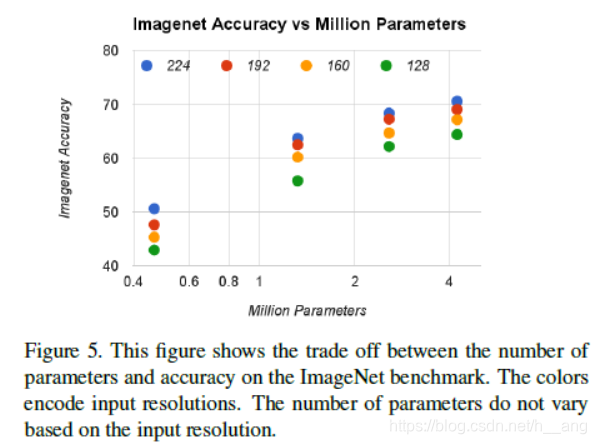
Figure展5示了当宽度因子分别取{1, 0.75, 0.5, 0.25},分辨率因子分别取{224, 192, 160, 128}时组合的16中模型对应准确率和参数量之间的关系。
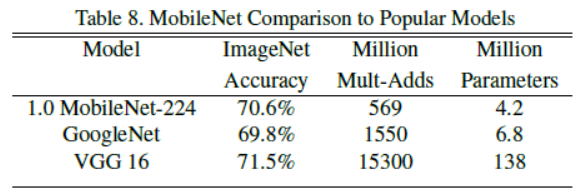
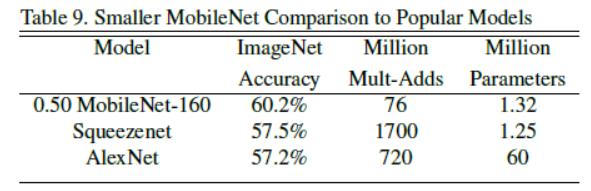
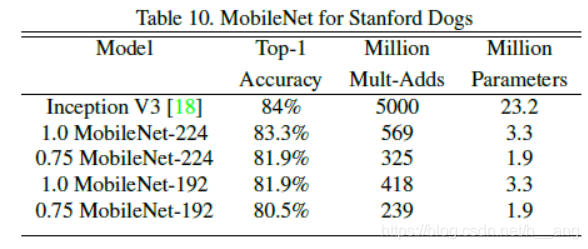
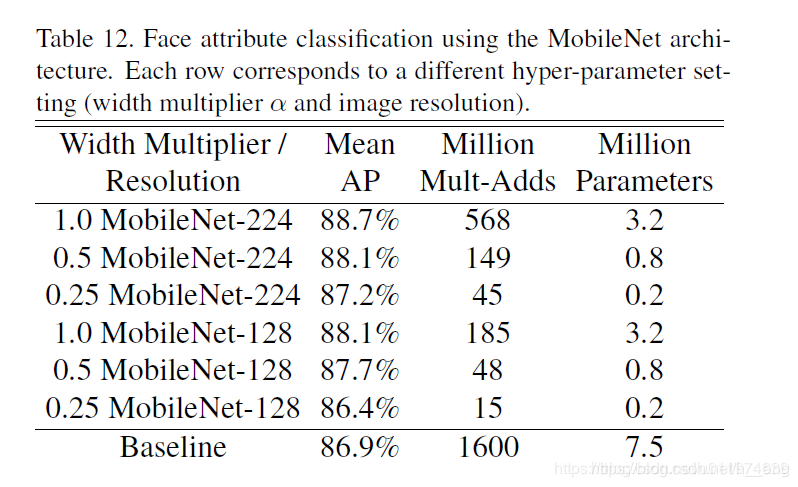
3. Face Attributes
MobileNet的框架技术可用于压缩大型模型,在Face Attributes任务中,我们验证了MobileNet的蒸馏(distillation )技术的关系,蒸馏的核心是让小模型去模拟大模型,而不是直接逼近Ground Label:
Conclusion
论文提出了一种基于深度可分离卷积的新模型MobileNet,同时提出了两个超参数用于快速调节模型适配到特定环境。实验部分将MobileNet与许多先进模型做对比,展现出MobileNet的在尺寸、计算量、速度上的优越性。
源码解读
源码主体还是mobilenet_v1_base和mobilenet_v1部分,在mobilenet_v1_base中对自己定义的卷积结构展开,这里需要注意的是为了在depthwise卷积过程中扩大感受野采用了空洞卷积。
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# =============================================================================
"""MobileNet v1.
MobileNet is a general architecture and can be used for multiple use cases.
Depending on the use case, it can use different input layer size and different
head (for example: embeddings, localization and classification).
As described in https://arxiv.org/abs/1704.04861.
MobileNets: Efficient Convolutional Neural Networks for
Mobile Vision Applications
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang,
Tobias Weyand, Marco Andreetto, Hartwig Adam
100% Mobilenet V1 (base) with input size 224x224:
See mobilenet_v1()
Layer params macs
--------------------------------------------------------------------------------
MobilenetV1/Conv2d_0/Conv2D: 864 10,838,016
MobilenetV1/Conv2d_1_depthwise/depthwise: 288 3,612,672
MobilenetV1/Conv2d_1_pointwise/Conv2D: 2,048 25,690,112
MobilenetV1/Conv2d_2_depthwise/depthwise: 576 1,806,336
MobilenetV1/Conv2d_2_pointwise/Conv2D: 8,192 25,690,112
MobilenetV1/Conv2d_3_depthwise/depthwise: 1,152 3,612,672
MobilenetV1/Conv2d_3_pointwise/Conv2D: 16,384 51,380,224
MobilenetV1/Conv2d_4_depthwise/depthwise: 1,152 903,168
MobilenetV1/Conv2d_4_pointwise/Conv2D: 32,768 25,690,112
MobilenetV1/Conv2d_5_depthwise/depthwise: 2,304 1,806,336
MobilenetV1/Conv2d_5_pointwise/Conv2D: 65,536 51,380,224
MobilenetV1/Conv2d_6_depthwise/depthwise: 2,304 451,584
MobilenetV1/Conv2d_6_pointwise/Conv2D: 131,072 25,690,112
MobilenetV1/Conv2d_7_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_7_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_8_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_8_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_9_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_9_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_10_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_10_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_11_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_11_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_12_depthwise/depthwise: 4,608 225,792
MobilenetV1/Conv2d_12_pointwise/Conv2D: 524,288 25,690,112
MobilenetV1/Conv2d_13_depthwise/depthwise: 9,216 451,584
MobilenetV1/Conv2d_13_pointwise/Conv2D: 1,048,576 51,380,224
--------------------------------------------------------------------------------
Total: 3,185,088 567,716,352
75% Mobilenet V1 (base) with input size 128x128:
See mobilenet_v1_075()
Layer params macs
--------------------------------------------------------------------------------
MobilenetV1/Conv2d_0/Conv2D: 648 2,654,208
MobilenetV1/Conv2d_1_depthwise/depthwise: 216 884,736
MobilenetV1/Conv2d_1_pointwise/Conv2D: 1,152 4,718,592
MobilenetV1/Conv2d_2_depthwise/depthwise: 432 442,368
MobilenetV1/Conv2d_2_pointwise/Conv2D: 4,608 4,718,592
MobilenetV1/Conv2d_3_depthwise/depthwise: 864 884,736
MobilenetV1/Conv2d_3_pointwise/Conv2D: 9,216 9,437,184
MobilenetV1/Conv2d_4_depthwise/depthwise: 864 221,184
MobilenetV1/Conv2d_4_pointwise/Conv2D: 18,432 4,718,592
MobilenetV1/Conv2d_5_depthwise/depthwise: 1,728 442,368
MobilenetV1/Conv2d_5_pointwise/Conv2D: 36,864 9,437,184
MobilenetV1/Conv2d_6_depthwise/depthwise: 1,728 110,592
MobilenetV1/Conv2d_6_pointwise/Conv2D: 73,728 4,718,592
MobilenetV1/Conv2d_7_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_7_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_8_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_8_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_9_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_9_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_10_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_10_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_11_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_11_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_12_depthwise/depthwise: 3,456 55,296
MobilenetV1/Conv2d_12_pointwise/Conv2D: 294,912 4,718,592
MobilenetV1/Conv2d_13_depthwise/depthwise: 6,912 110,592
MobilenetV1/Conv2d_13_pointwise/Conv2D: 589,824 9,437,184
--------------------------------------------------------------------------------
Total: 1,800,144 106,002,432
"""
# Tensorflow mandates these.
# 绝对引入,与之对应的是相对引入
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from collections import namedtuple
import functools
import tensorflow as tf
slim = tf.contrib.slim
# Conv and DepthSepConv namedtuple define layers of the MobileNet architecture
# Conv defines 3x3 convolution layers
# DepthSepConv defines 3x3 depthwise convolution followed by 1x1 convolution.
# stride is the stride of the convolution
# depth is the number of channels or filters in a layer
Conv = namedtuple('Conv', ['kernel', 'stride', 'depth'])
DepthSepConv = namedtuple('DepthSepConv', ['kernel', 'stride', 'depth'])
# MOBILENETV1_CONV_DEFS specifies the MobileNet body
MOBILENETV1_CONV_DEFS = [
Conv(kernel=[3, 3], stride=2, depth=32),
DepthSepConv(kernel=[3, 3], stride=1, depth=64),
DepthSepConv(kernel=[3, 3], stride=2, depth=128),
DepthSepConv(kernel=[3, 3], stride=1, depth=128),
DepthSepConv(kernel=[3, 3], stride=2, depth=256),
DepthSepConv(kernel=[3, 3], stride=1, depth=256),
DepthSepConv(kernel=[3, 3], stride=2, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=2, depth=1024),
DepthSepConv(kernel=[3, 3], stride=1, depth=1024)
]
# 做全零填充
def _fixed_padding(inputs, kernel_size, rate=1):
"""Pads the input along the spatial dimensions independently of input size.
Pads the input such that if it was used in a convolution with 'VALID' padding,
the output would have the same dimensions as if the unpadded input was used
in a convolution with 'SAME' padding.
Args:
inputs: A tensor of size [batch, height_in, width_in, channels].
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
rate: An integer, rate for atrous convolution.
Returns:
output: A tensor of size [batch, height_out, width_out, channels] with the
input, either intact (if kernel_size == 1) or padded (if kernel_size > 1).
"""
kernel_size_effective = [kernel_size[0] + (kernel_size[0] - 1) * (rate - 1),
kernel_size[0] + (kernel_size[0] - 1) * (rate - 1)]
pad_total = [kernel_size_effective[0] - 1, kernel_size_effective[1] - 1]
pad_beg = [pad_total[0] // 2, pad_total[1] // 2]
pad_end = [pad_total[0] - pad_beg[0], pad_total[1] - pad_beg[1]]
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg[0], pad_end[0]],
[pad_beg[1], pad_end[1]], [0, 0]])
return padded_inputs
# 将MOBILENETV1_CONV_DEFS定义的卷积操作展开
def mobilenet_v1_base(inputs,
final_endpoint='Conv2d_13_pointwise',
min_depth=8,
depth_multiplier=1.0,
conv_defs=None,
output_stride=None,
use_explicit_padding=False,
scope=None):
"""Mobilenet v1.
Constructs a Mobilenet v1 network from inputs to the given final endpoint.
Args:
inputs: a tensor of shape [batch_size, height, width, channels].
final_endpoint: specifies the endpoint to construct the network up to. It
can be one of ['Conv2d_0', 'Conv2d_1_pointwise', 'Conv2d_2_pointwise',
'Conv2d_3_pointwise', 'Conv2d_4_pointwise', 'Conv2d_5'_pointwise,
'Conv2d_6_pointwise', 'Conv2d_7_pointwise', 'Conv2d_8_pointwise',
'Conv2d_9_pointwise', 'Conv2d_10_pointwise', 'Conv2d_11_pointwise',
'Conv2d_12_pointwise', 'Conv2d_13_pointwise'].
min_depth: Minimum depth value (number of channels) for all convolution ops.
Enforced when depth_multiplier < 1, and not an active constraint when
depth_multiplier >= 1.
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
conv_defs: A list of ConvDef namedtuples specifying the net architecture.
output_stride: An integer that specifies the requested ratio of input to
output spatial resolution. If not None, then we invoke atrous convolution
if necessary to prevent the network from reducing the spatial resolution
of the activation maps. Allowed values are 8 (accurate fully convolutional
mode), 16 (fast fully convolutional mode), 32 (classification mode).
use_explicit_padding: Use 'VALID' padding for convolutions, but prepad
inputs so that the output dimensions are the same as if 'SAME' padding
were used.
scope: Optional variable_scope.
Returns:
tensor_out: output tensor corresponding to the final_endpoint.
end_points: a set of activations for external use, for example summaries or
losses.
Raises:
ValueError: if final_endpoint is not set to one of the predefined values,
or depth_multiplier <= 0, or the target output_stride is not
allowed.
"""
# 定义"瘦身"后的卷积核通道数
depth = lambda d: max(int(d * depth_multiplier), min_depth)
end_points = {}
# Used to find thinned depths for each layer.
if depth_multiplier <= 0:
raise ValueError('depth_multiplier is not greater than zero.')
# 如果没有设置conv_dfs,就用上面我们定义的网络结构
if conv_defs is None:
conv_defs = MOBILENETV1_CONV_DEFS
if output_stride is not None and output_stride not in [8, 16, 32]:
raise ValueError('Only allowed output_stride values are 8, 16, 32.')
padding = 'SAME'
if use_explicit_padding:
padding = 'VALID'
with tf.variable_scope(scope, 'MobilenetV1', [inputs]):
with slim.arg_scope([slim.conv2d, slim.separable_conv2d], padding=padding):
# The current_stride variable keeps track of the output stride of the
# activations, i.e., the running product of convolution strides up to the
# current network layer. This allows us to invoke atrous convolution
# whenever applying the next convolution would result in the activations
# having output stride larger than the target output_stride.
current_stride = 1
# 空洞卷积中的rate参数,当rate=1时等价于标准卷积
rate = 1
net = inputs
# 展开 conv_defs 中定义的各种卷积操作
for i, conv_def in enumerate(conv_defs):
# 第i个卷积操作
end_point_base = 'Conv2d_%d' % i
# 如果当前stride已经满足用户指定的输出stride 则后面的stride强制为1
# 但是rate=rate*stride保证感受野;
# 如果没有满足输出stride, stride和网络配置一样,但是layer_rate=1
if output_stride is not None and current_stride == output_stride:
# If we have reached the target output_stride, then we need to employ
# atrous convolution with stride=1 and multiply the atrous rate by the
# current unit's stride for use in subsequent layers.
layer_stride = 1
layer_rate = rate
rate *= conv_def.stride
else:
layer_stride = conv_def.stride
layer_rate = 1
current_stride *= conv_def.stride
if isinstance(conv_def, Conv):
end_point = end_point_base
if use_explicit_padding:
net = _fixed_padding(net, conv_def.kernel)
net = slim.conv2d(net, depth(conv_def.depth), conv_def.kernel,
stride=conv_def.stride,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
elif isinstance(conv_def, DepthSepConv):
end_point = end_point_base + '_depthwise'
# By passing filters=None
# separable_conv2d produces only a depthwise convolution layer
if use_explicit_padding:
net = _fixed_padding(net, conv_def.kernel, layer_rate)
net = slim.separable_conv2d(net, None, conv_def.kernel,
depth_multiplier=1,
stride=layer_stride,
rate=layer_rate,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
end_point = end_point_base + '_pointwise'
net = slim.conv2d(net, depth(conv_def.depth), [1, 1],
stride=1,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
else:
raise ValueError('Unknown convolution type %s for layer %d'
% (conv_def.ltype, i))
raise ValueError('Unknown final endpoint %s' % final_endpoint)
# 在mobilenet_v1_base的基础上增加池化
def mobilenet_v1(inputs,
num_classes=1000,
dropout_keep_prob=0.999,
is_training=True,
min_depth=8,
depth_multiplier=1.0,
conv_defs=None,
prediction_fn=tf.contrib.layers.softmax,
spatial_squeeze=True,
reuse=None,
scope='MobilenetV1',
global_pool=False):
"""Mobilenet v1 model for classification.
Args:
inputs: a tensor of shape [batch_size, height, width, channels].
num_classes: number of predicted classes. If 0 or None, the logits layer
is omitted and the input features to the logits layer (before dropout)
are returned instead.
dropout_keep_prob: the percentage of activation values that are retained.
is_training: whether is training or not.
min_depth: Minimum depth value (number of channels) for all convolution ops.
Enforced when depth_multiplier < 1, and not an active constraint when
depth_multiplier >= 1.
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
conv_defs: A list of ConvDef namedtuples specifying the net architecture.
prediction_fn: a function to get predictions out of logits.
spatial_squeeze: if True, logits is of shape is [B, C], if false logits is
of shape [B, 1, 1, C], where B is batch_size and C is number of classes.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
global_pool: Optional boolean flag to control the avgpooling before the
logits layer. If false or unset, pooling is done with a fixed window
that reduces default-sized inputs to 1x1, while larger inputs lead to
larger outputs. If true, any input size is pooled down to 1x1.
Returns:
net: a 2D Tensor with the logits (pre-softmax activations) if num_classes
is a non-zero integer, or the non-dropped-out input to the logits layer
if num_classes is 0 or None.
end_points: a dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: Input rank is invalid.
"""
input_shape = inputs.get_shape().as_list()
if len(input_shape) != 4:
raise ValueError('Invalid input tensor rank, expected 4, was: %d' %
len(input_shape))
with tf.variable_scope(scope, 'MobilenetV1', [inputs], reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = mobilenet_v1_base(inputs, scope=scope,
min_depth=min_depth,
depth_multiplier=depth_multiplier,
conv_defs=conv_defs)
# 网络输入图像尺寸为224 * 224时,此时的net尺寸为 7*7*1024
with tf.variable_scope('Logits'):
if global_pool:
# Global average pooling.
# 如果直接采用global_pool进行采样,则输出维度变为[batch, 1, 1, 1024]
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
end_points['global_pool'] = net
else:
# Pooling with a fixed kernel size.
# 这里主要是为了防止采用分辨率因子缩小图像尺寸之后,输入就不是原来的 7 * 7 *1024,所以先调用函数所有池化核的尺寸
kernel_size = _reduced_kernel_size_for_small_input(net, [7, 7])
net = slim.avg_pool2d(net, kernel_size, padding='VALID',
scope='AvgPool_1a')
end_points['AvgPool_1a'] = net
# 如果num_classes为0或者None,直接返回
if not num_classes:
return net, end_points
# 1 x 1 x 1024
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
# 用 1 x 1的卷积来替代全连接层
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='Conv2d_1c_1x1')
# logits维度为 batch x 1 x 1 x 1000, 调用tf.squeeze将1, 2维度的1删掉变为 batch x 1000
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
if prediction_fn:
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
mobilenet_v1.default_image_size = 224
def wrapped_partial(func, *args, **kwargs):
partial_func = functools.partial(func, *args, **kwargs)
functools.update_wrapper(partial_func, func)
return partial_func
mobilenet_v1_075 = wrapped_partial(mobilenet_v1, depth_multiplier=0.75)
mobilenet_v1_050 = wrapped_partial(mobilenet_v1, depth_multiplier=0.50)
mobilenet_v1_025 = wrapped_partial(mobilenet_v1, depth_multiplier=0.25)
def _reduced_kernel_size_for_small_input(input_tensor, kernel_size):
"""Define kernel size which is automatically reduced for small input.
If the shape of the input images is unknown at graph construction time this
function assumes that the input images are large enough.
Args:
input_tensor: input tensor of size [batch_size, height, width, channels].
kernel_size: desired kernel size of length 2: [kernel_height, kernel_width]
Returns:
a tensor with the kernel size.
"""
shape = input_tensor.get_shape().as_list()
if shape[1] is None or shape[2] is None:
kernel_size_out = kernel_size
else:
kernel_size_out = [min(shape[1], kernel_size[0]),
min(shape[2], kernel_size[1])]
return kernel_size_out
def mobilenet_v1_arg_scope(
is_training=True,
weight_decay=0.00004,
stddev=0.09,
regularize_depthwise=False,
batch_norm_decay=0.9997,
batch_norm_epsilon=0.001,
batch_norm_updates_collections=tf.GraphKeys.UPDATE_OPS,
normalizer_fn=slim.batch_norm):
"""Defines the default MobilenetV1 arg scope.
Args:
is_training: Whether or not we're training the model. If this is set to
None, the parameter is not added to the batch_norm arg_scope.
weight_decay: The weight decay to use for regularizing the model.
stddev: The standard deviation of the trunctated normal weight initializer.
regularize_depthwise: Whether or not apply regularization on depthwise.
batch_norm_decay: Decay for batch norm moving average.
batch_norm_epsilon: Small float added to variance to avoid dividing by zero
in batch norm.
batch_norm_updates_collections: Collection for the update ops for
batch norm.
normalizer_fn: Normalization function to apply after convolution.
Returns:
An `arg_scope` to use for the mobilenet v1 model.
"""
batch_norm_params = {
'center': True,
'scale': True,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'updates_collections': batch_norm_updates_collections,
}
if is_training is not None:
batch_norm_params['is_training'] = is_training
# Set weight_decay for weights in Conv and DepthSepConv layers.
weights_init = tf.truncated_normal_initializer(stddev=stddev)
regularizer = tf.contrib.layers.l2_regularizer(weight_decay)
if regularize_depthwise:
depthwise_regularizer = regularizer
else:
depthwise_regularizer = None
with slim.arg_scope([slim.conv2d, slim.separable_conv2d],
weights_initializer=weights_init,
activation_fn=tf.nn.relu6, normalizer_fn=normalizer_fn):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d], weights_regularizer=regularizer):
with slim.arg_scope([slim.separable_conv2d],
weights_regularizer=depthwise_regularizer) as sc:
return sc