【轻量型卷积网络】MobileNet系列:MobileNet V1网络解析
文章目录
1. 介绍
论文地址:论文链接
传统卷积神经网络,内存需求大、运算量大导致无法在移动设备以及嵌入式设备上运行。
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
- 压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;
- 还有一种训练小型网络的方法叫蒸馏(distillation) 蒸馏方法解读,使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
- 直接训练小型模型。 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
本文MobileNet网络架构属于上述第二种,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32), 网络主要体现两方面:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加了两个超参数α,β,其中 α 控制卷积核个数的超参数,β 控制输入图像大小,这两个参数是人为设定的,并不是网络学习到的。
MobileNet是Google提出的一种小巧而高效的CNN模型,MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions, 即Xception变体结构)来构建轻量级深度神经网络。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型也在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。
2. 模型
2.1 基本单元:深度可分离卷积(depthwise separable convolution)
mobileNet的基本单元是深度可分离卷积(depthwise separable convolution)。深度可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution(DW 卷积)和pointwise convolution(PW卷积)。
2.1.1 DW卷积
Depthwise Convolution和传统卷积不同,对于传统卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。
-
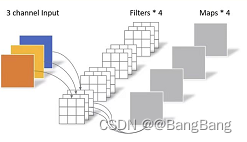
传统卷积
- 卷积核的channel=输入特征channel
- 输出特征矩阵的channel=卷积核个数
-
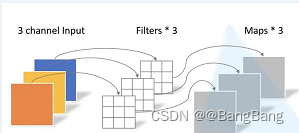
DW卷积
- 卷积核的channel=1
- 输入特征channel=卷积核个数=输出特征channel
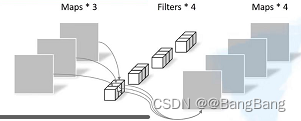
2.1.2 PW卷积
pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。
对于depthwise separable convolution,
- 其首先是采用depthwise convolution对不同输入通道分别进行卷积,
- 然后采用pointwise convolution将上面的输出再进行结合,
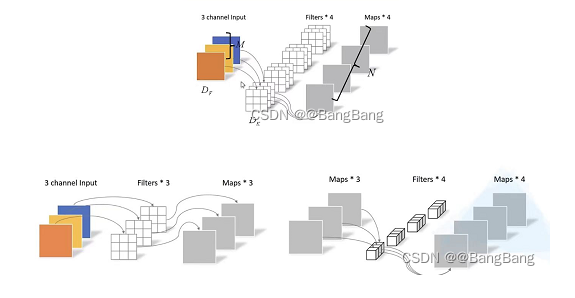
这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。使用depthwise separable convolution(深度可分离卷积),能减少多少参数呢?请看下图对比说明:

2.2 网络结构
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入BN层,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图4右边所示。标准卷积和MobileNet中使用的深度分离卷积结构对比如下:
 、
、
MobieNet V1网络结构细节如下:
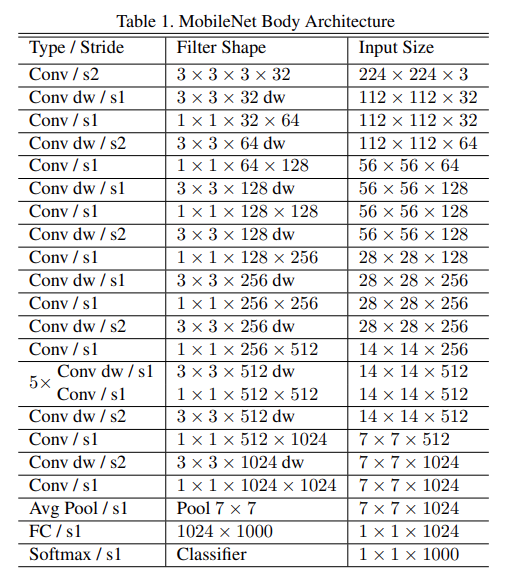
- mobienet v1 网络结构中第一行Conv/s2表示普通卷积,步距为2.Filter Shape为3x3x3x32表示卷积核大小为3x3,输入为彩色图片3通道,输出为32通道
- Conv dw/s1表示 DW卷积,步距为1,Filter Shape为3 x 3 x 32表示卷积核大小3x3,dw卷积的channel为1,卷积核的个数为32
- 由于可分离卷积是mobienet v1基本组件,可分离卷积表示为dw +pw,因此dw 和1x1的pw是成对出现的
- mobienet v1的模型结构有点类似于VGG结构,简单的将一系列卷积进行串行链接。
3. 实验
3.1 对比大模型
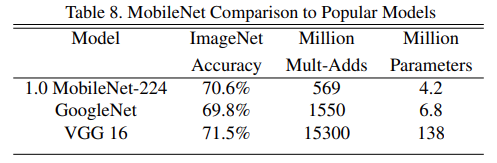
对比了 MobieNet 和GoogleNet、VGG16在imageNet数据集上的准确率、运算量和模型参数,可以看到MobieNet相对于VGG16 它的准确率只减少了0.9%,但它的模型参数大概只有VGG网络的1/32。
3.2 对比小模型
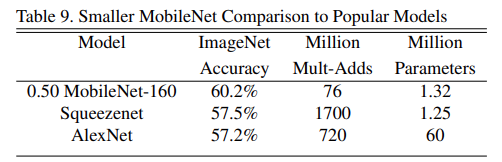
对比了 MobieNet 和squeezenet、AlexNet在imageNet数据集上的准确率、运算量和模型参数,可以看到MobieNet准确率高且模型参数少。
3.3 超参数 α 和 β
-
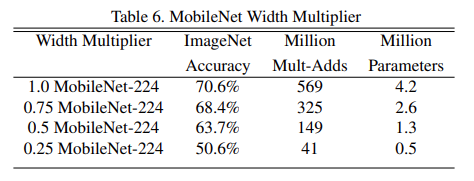
α 是卷积核个数的倍率,控制卷积过程中采用的卷积核个数。看看取不同 α 时网络的效果。
- α 取1.0的时候,它的准确率是70.6%,当α 取0.75时,即卷积个数缩减为原来的0.75倍的时候,它的准确率为68.4%,同时计算量和参数也不同程度的减少;当α 取0.5时,准确率为63.7%,计算量和参数同时也在减少。可以发现将我们卷积核个数减少之后,准确率上没有太大的变化,但模型参数大幅减少。可以根据自己的项目需求去选择合适的α值。
-
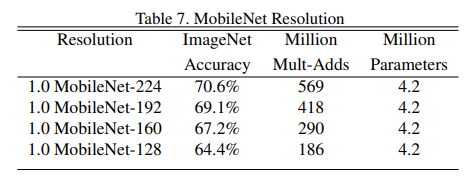
β 是分辨率的参数,输入图像的尺寸对网络的分类准确率,模型计算量、模型参数的对比。可以发现通过适当减低图片尺寸大小,能够保证准确率降低很小的情况下,来大幅减少我们的运算量。根据你自己项目的需求来设置β 参数。
4. 总结
在mobienet v1网络的实际使用中,很多人发现dw卷积,它在训练完之后部分卷积核容易废掉,即卷积核参数大部分为0。因为你观察DW卷积的参数时,你会发现它的大部分参数都是等于0的,DW卷积核是没有起到作用的。针对这个问题 在mobienet v2中会得到改善。
5. 参考
【1】https://blog.csdn.net/weixin_38346042/article/details/125329726