MobileNet v1
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。
深度可分离卷积
要说MobileNet网络的优点,无疑是其中的Depthwise Convolution结构(大大减少运算量和参数数量)。
传统卷积,输入是3个通道特征图,经过4个(3x3x3)的卷积核,得到4个通道的特征图。有几个卷积核,卷积后输出就会得到几个通道。
深度可分离卷积(depthwise separable convolution),由depthwise(DW)和pointwise(PW)两个部分,用来提取特征feature map。优点:1、减少参数数量。2、减少运算量。
2.1 逐通道卷积(Depthwise Convolution)
逐通道卷积:一个卷积核负责一个通道,一个通道只被一个卷积核卷积,输出通道数和输入的通道数完全一样。
Params:3x3x3=27
MAdds:3x3x3x(H-2)X(W-2)
2.2 深度可分离卷积-逐点卷积(Pointwise Convolution)
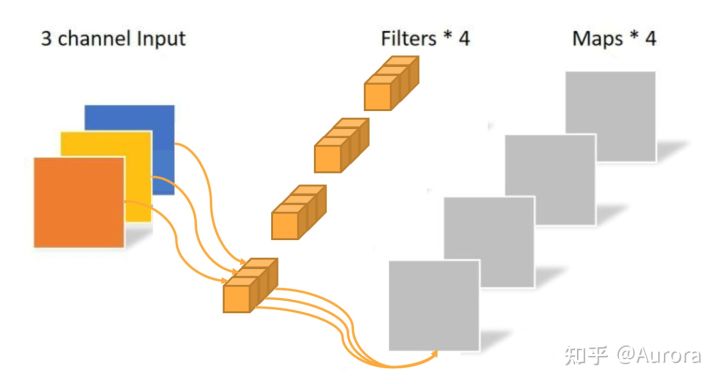
逐点卷积:卷积核的形状为 Cx1×1,C为输入的通道数。深度方向上进行加权求和(也可以理解成在每一个像素点上操作),输入的通道数等于卷积和个数。
Params:4x3x1x1=12
MAdds:4x3x1x1xHxW
下图展示了传统卷积与DW卷积的差异,在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算)。
而在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数)
刚刚说了使用DW卷积后输出特征矩阵的channel是与输入特征矩阵的channel相等的,如果想改变/自定义输出特征矩阵的channel,那只需要在DW卷积后接上一个PW卷积即可,如下图所示,其实PW卷积就是普通的卷积而已(只不过卷积核大小为1)。通常DW卷积和PW卷积是放在一起使用的,一起叫做Depthwise Separable Convolution(深度可分卷积)。
计算量
那Depthwise Separable Convolution(深度可分卷积)与传统的卷积相比有到底能节省多少计算量呢,下图对比了这两个卷积方式的计算量,其中Df是输入特征矩阵的宽高(这里假设宽和高相等),Dk是卷积核的大小,M是输入特征矩阵的channel,N是输出特征矩阵的channel,卷积计算量近似等于卷积核的高 x 卷积核的宽 x 卷积核的channel x 输入特征矩阵的高 x 输入特征矩阵的宽(这里假设stride等于1),在我们mobilenet网络中DW卷积都是是使用3x3大小的卷积核。所以理论上普通卷积计算量是DW+PW卷积的8到9倍
网络结构
在mobilenetv1原论文中,还提出了两个超参数,一个是α一个是β。α参数是一个倍率因子,用来调整卷积核的个数,β是控制输入网络的图像尺寸参数,下图右侧给出了使用不同α和β网络的分类准确率,计算量以及模型参数。


mobilenet v1的网络结构,左侧的表格是mobileNetv1的网络结构,表中标Conv的表示普通卷积,Conv dw代表刚刚说的DW卷积,s表示步距,
首先是一个3x3的标准卷积,s2进行下采样。然后就是堆积深度可分离卷积,并且其中的部分深度卷积会利用s2进行下采样。然后采用平均池化层将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。整个网络有28层,其中深度卷积层有13层。
根据表格信息就能很容易的搭建出mobileNet v1网络。
MobileNet v2
而且有人反映说MobileNet v1网络中的DW卷积很容易训练废掉,效果并没有那么理想。
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
Relu做了啥?
这是将低维流形的ReLU变换embedded到高维空间中的的例子。

我们在这里抛弃掉流形这个概念,通俗理解一下。
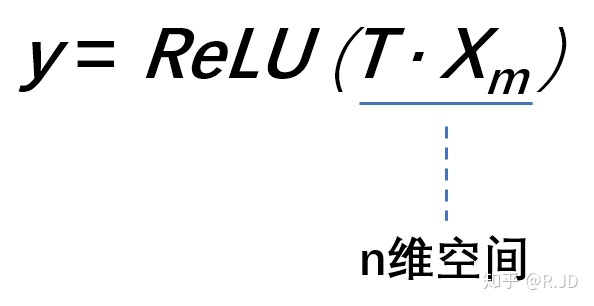
假设在2维空间有一组由m个点组成的螺旋线Xm数据(如input),利用随机矩阵T映射到n维空间上并进行ReLU运算,即:

其中,Xm被随机矩阵T映射到了n维空间:
再利用随机矩阵T的逆矩阵T-1,将y映射回2维空间当中:
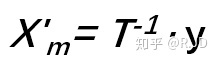
全过程如下表示:
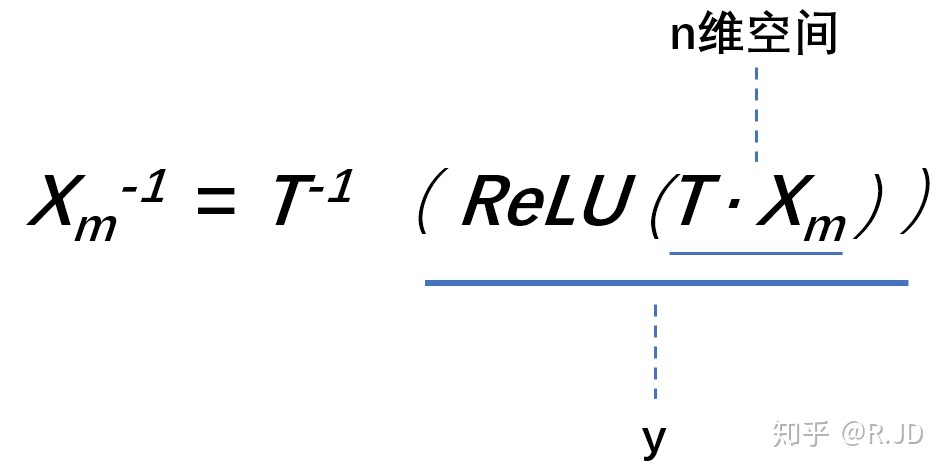
换句话说,就是对一个n维空间中的一个“东西”做ReLU运算,然后(利用T的逆矩阵T-1恢复)对比ReLU之后的结果与Input的结果相差有多大。
可以看到:
当n = 2,3时,与Input相比有很大一部分的信息已经丢失了。而当n = 15到30,还是有相当多的地方被保留了下来。
也就是说,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
什么是Linear Bottlenck结构(Mobilenetv2提出)?
由于DW、PW都是以Relu作为激活函数,且PW会做降维,再对低维特征做ReLU时会丢失很多信息,所以从高维向低维转换,使用ReLU激活函数可能会造成信息丢失或破坏(所以不使用非线性激活数函数),即在PW这一部分,我们不再使用ReLU激活函数而是使用线性激活函数。
Inverted residual block(倒残差结构)
如下下图所示,左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的到残差结构。在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。
MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。
实验结果:
Object Detection
SSDLite
目标检测方面,作者首先提出了SSDLite。就是对SSD结构做了修改,将SSD的预测层中所有标准卷积替换为深度可分离卷积。作者说这样参数量和计算成本大大降低,计算更高效
MobileNet v3
1)加入了注意力机制(SE模块)
主要的操作是针对输出的特征矩阵的每一个channel进行池化处理,所得到的向量个数就是channel的个数。然后再通过两个全连接层,得到我们输出的向量。其中,第一个全连接层的向量个数是channel个数的四分之一,然后第二个全连接层的输出与channel个数相同。而且,这两个全连接的所使用的的激活函数是不一样的。前一个使用的ReLu激活函数,后一个使用h-swish激活函数。
对得到的每个channel进行池化,假设输出的特征矩阵的channel是为2的,进行平均池化得到一个元素个数为2的向量,依次经过两个全连接层,所得到的的这个向量可以理解为对刚刚输入的每一个channel分析出了一个权重关系。也就是如果他觉得比较重要的channel就会赋予一个比较大的权重,而如果是没有那么重要的channel就会赋予一个比较小的权重。

2)h-swish激活函数
swish非线性激活函数作为ReLU的替代,可以可以显着提高神经网络的准确性,其定义如下:
尽管这种非线性提高了准确性,但在嵌入式环境中却带来了非零成本,因为S型函数在移动设备上的计算成本更高。主要是计算、求导复杂,
对量化过程不友好。
激活函数h-swish
swish
h-swish是基于swish的改进

swish论文的作者认为,Swish具备无上界有下界、平滑、非单调的特性。并且Swish在深层模型上的效果优于ReLU。仅仅使用Swish单元替换ReLU就能把MobileNet,NASNetA在 ImageNet上的top-1分类准确率提高0.9%,Inception-ResNet-v的分类准确率提高0.6%。
V3也利用swish当作为ReLU的替代时,它可以显著提高神经网络的精度。但是呢,作者认为这种非线性激活函数虽然提高了精度,但在嵌入式环境中,是有不少的成本的。原因就是在移动设备上计算sigmoid函数是非常明智的选择。所以提出了h-swish。
h-swish
sigmoid激活函数:
swish激活函数:
ReLU6激活函数:就是在relu的基础上加了一个上限6
可以用一个近似函数来逼急这个swish,让swish变得硬(hard)。作者选择的是基于ReLU6,作者认为几乎所有的软件和硬件框架上都可以使用ReLU6的优化实现。其次,它能在特定模式下消除了由于近似sigmoid的不同实现而带来的潜在的数值精度损失。

下图是Sigmoid和swish的hard、soft形式:

我们可以简单的认为,hard形式是soft形式的低精度化。作者认为swish的表现和其他非线性相比,能够将过滤器的数量减少到16个的同时保持与使用ReLU或swish的32个过滤器相同的精度,这节省了3毫秒的时间和1000万MAdds的计算量。
并且同时,作者认为随着网络的深入,应用非线性激活函数的成本会降低,能够更好的减少参数量。作者发现swish的大多数好处都是通过在更深的层中使用它们实现的。因此,在V3的架构中,只在模型的后半部分使用h-swish(HS)。
3)重新设计耗时层结构
减少第一个卷积层的卷积核个数 (32->16):原论文作者发现将卷积的filters的个数从32变成16之后准确率是一样的,使用更少的卷积核更节省计算时间。
精简last stage:
当前基于MobileNetV2的倒置瓶颈结构和变体的模型使用1x1卷积作为最后一层,以便扩展到更高维度的特征空间。为了具有丰富的预测特征,这一层至关重要。 但是,这要付出额外的计算和延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少7ms的开销,在提速11%的同时减小了30m的操作数。
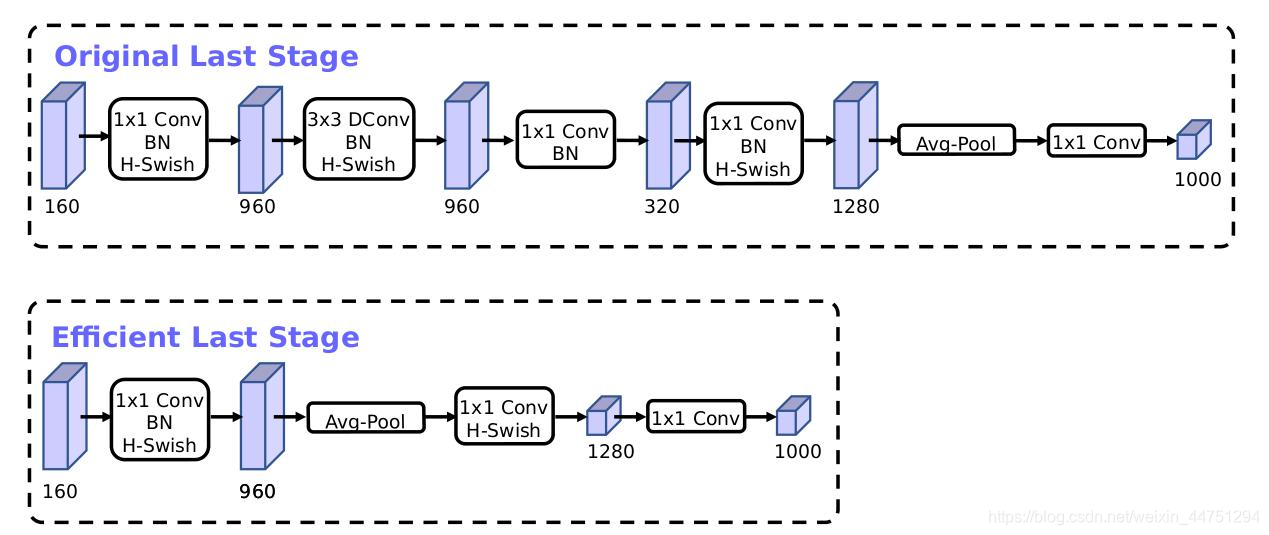
4)头部channel数量改变
当前的MobilenetV2开始使用32个 3 * 3的滤波器,作者发现使用h-swish激活函数相比于使用sigmoid和swish函数,可以在保持精度不减的情况下,将channel降低到16个,并且提速2ms。
给出MobilenetV2和MobilenetV3的结构如下,重点关注前面的通道数 32/16。
MobileNetV3定义了两个模型: MobileNetV3-Large和MobileNetV3-Small。V3-Large是针对高资源情况下的使用,相应的,V3-small就是针对低资源情况下的使用
网络结构搜索NAS
主要结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt。
资源受限的NAS,用于在计算和参数量受限的前提下搜索网络来优化各个块(block),所以称之为模块级搜索(Block-wise Search) 。
NetAdapt,用于对各个模块确定之后网络层的微调每一层的卷积核数量,所以称之为层级搜索(Layer-wise Search)。
一旦通过体系结构搜索找到模型,我们就会发现最后一些层以及一些早期层计算代价比较高昂。于是作者决定对这些架构进行一些修改,以减少这些慢层(slow layers)的延迟,同时保持准确性。这些修改显然超出了当前搜索的范围。