- mobilenet网络结构:
注意:CIFAR10输入图像是32x32x3,没有必要非转成224x224x3,因此对结构进行了细微的调整,但是深度可分离卷积是mobilenet的重点,因此最后层数的细微更改不影响全局。

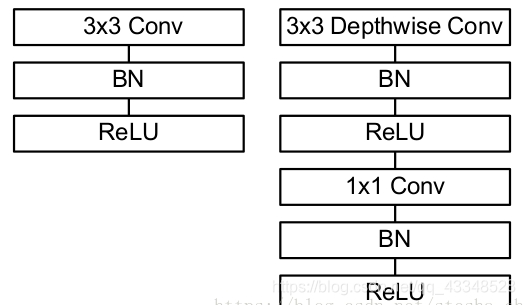
- 代码:
def run_model(session, predict, loss_val, Xd, yd,
epochs=1, batch_size=64, print_every=100,
training=None, plot_losses=False):
# have tensorflow compute accuracy
# tf.argmax返回predict每行数值最大的下标
correct_prediction = tf.equal(tf.argmax(predict,1), y)
#tf.cast 将输入的数据格式转换为dtype
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# shuffle indicies
# np.random.shuffle()生成随机列表
train_indicies = np.arange(Xd.shape[0])
np.random.shuffle(train_indicies)
training_now = training is not None
# setting up variables we want to compute (and optimizing)
# if we have a training function, add that to things we compute
variables = [mean_loss,correct_prediction,accuracy]
if training_now:
variables[-1] = training
# counter
iter_cnt = 0
for e in range(epochs):
# keep track of losses and accuracy
correct = 0
losses = []
# make sure we iterate over the dataset once
#math.ceil返回大于参量的最小整数
for i in range(int(math.ceil(Xd.shape[0]/batch_size))):
# generate indicies for the batch
start_idx = (i*batch_size)%Xd.shape[0]
idx = train_indicies[start_idx:start_idx+batch_size]
# create a feed dictionary for this batch
feed_dict = {X: Xd[idx,:],
y: yd[idx],
is_training: training_now }
# get batch size
#最后一次迭代中,实际的batch_size可能会小于设定的batch_size
actual_batch_size = yd[idx].shape[0]
# have tensorflow compute loss and correct predictions
# and (if given) perform a training step
#variables = [mean_loss,correct_prediction,accuracy]
# mean_loss = tf.reduce_mean(total_loss)
# correct_prediction = tf.equal(tf.argmax(predict,1), y)
# accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
loss, corr, _ = session.run(variables,feed_dict=feed_dict)
# aggregate performance stats
losses.append(loss*actual_batch_size)
correct += np.sum(corr)
# print every now and then
if training_now and (iter_cnt % print_every) == 0:
print("Iteration {0}: with minibatch training loss = {1:.3g} and accuracy of {2:.2g}"\
.format(iter_cnt,loss,np.sum(corr)/actual_batch_size))
iter_cnt += 1
total_correct = correct/Xd.shape[0]
total_loss = np.sum(losses)/Xd.shape[0]
print("Epoch {2}, Overall loss = {0:.3g} and accuracy of {1:.3g}"\
.format(total_loss,total_correct,e+1))
if plot_losses:
plt.plot(losses)
plt.grid(True)
plt.title('Epoch {} Loss'.format(e+1))
plt.xlabel('minibatch number')
plt.ylabel('minibatch loss')
plt.show()
return total_loss,total_correct
网络结构代码:
# Feel free to play with this cell
tf.reset_default_graph()
X = tf.placeholder(tf.float32, [None, 32, 32, 3])
y = tf.placeholder(tf.int64, [None])
is_training = tf.placeholder(tf.bool)
def separable_conv(x, N,stride,name,is_training):
with tf.variable_scope(name):
input_channel = x.get_shape().as_list()[-1]
#print(input_channel)
channel_wise_x = tf.split(x , input_channel , axis = 3)
#print(channel_wise_x)
output_channels = []
for i in range(len(channel_wise_x)):
output_channel = tf.layers.conv2d(channel_wise_x[i],
1,
(3,3),
strides = stride,
padding = 'same',
activation = None,
name = 'conv_%d' % i)
bn = tf.layers.batch_normalization(output_channel, training = is_training)
new_outpot_channel = tf.nn.relu(bn)
output_channels.append(new_outpot_channel)
#print('output_channels')
#print(output_channels)
concat_layer = tf.concat(output_channels, axis = 3)
#print('concat_layer:')
#print(concat_layer)
conv1_1 = tf.layers.conv2d(concat_layer,
N,
(1,1),
strides= (1,1),
padding = 'same',
activation = None,
name = name +'/conv1_1')
bn = tf.layers.batch_normalization(conv1_1,training = is_training)
return tf.nn.relu(bn)
def my_model(X,y,is_training):
conv1 = tf.layers.conv2d(X,32,(3,3),strides= (1,1),padding='same',activation = tf.nn.relu,name = 'conv1')
#print(conv1.shape)
pool1 = tf.layers.max_pooling2d(conv1,(2,2),(2,2), name= 'pool1')
#print(pool1.shape)
condw1 = separable_conv(pool1,64,stride=(1,1),name ='condw1', is_training=is_training)
#print(condw1.shape)
condw2 = separable_conv(condw1,128,stride=(2,2),name='condw2',is_training=is_training)
#print(condw2.shape)
condw3 = separable_conv(condw2,128,stride=(1,1),name='condw3',is_training=is_training)
condw4 = separable_conv(condw3,256,stride=(2,2),name='condw4',is_training=is_training)
#condw5 =separable_conv(condw4,256,stride=(1,1),name='condw5',is_training=is_training)
#condw6 = separable_conv(condw5,512,stride=(2,2),name= 'condw6',is_training=is_training)
#condw7_1 = separable_conv(condw6,512,stride=(1,1),name='condw7_1',is_training=is_training)
#condw7_2 = separable_conv(condw7_1,512,stride=(1,1),name='condw7_2',is_training=is_training)
#condw7_3 = separable_conv(condw7_2,512,stride=(1,1),name='condw7_3',is_training=is_training)
#condw7_4 = separable_conv(condw7_3,512,stride=(1,1),name='condw7_4',is_training=is_training)
#condw7_5 = separable_conv(condw7_4,512,stride=(1,1),name='condw7_5',is_training=is_training)
#condw8 = separable_conv(condw7_1,1024,stride=(1,1),name='condw8',is_training=is_training)
#condw9 = separable_conv(condw8,1024,stride=(1,1),name='condw9',is_training=is_training)
pool2 = tf.layers.average_pooling2d(condw4,(2,2),(2,2),name = 'pool2')
#print(pool2.shape)
flatten = tf.contrib.layers.flatten(pool2)
y_out = tf.layers.dense(flatten,10)
return y_out
print('my model')
y_out = my_model(X,y,is_training)
print('come on')
mean_loss = None
optimizer = None
print('loss')
total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels= tf.one_hot(y,10),logits=y_out))
#loss = tf.losses.sparse_softmax_cross_entropy( labels = y, logits = y_out)
mean_loss = tf.reduce_mean(total_loss)
optimizer = tf.train.RMSPropOptimizer(1e-3)
# batch normalization in tensorflow requires this extra dependency
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
train_step = optimizer.minimize(mean_loss)
- 结果:
并没有用到mobilenet当中那么多个卷积核,结果为:
