目录
MobileNet 三个系列的代码:MobileNet 网络对CIFAR10数据集应用
1. 介绍
MobileNet V3 相比MobileNet V2更加的准确,也同样是一个轻量级的网络
它的亮点如下:
- 更新了Block结构(bneck)
- 使用了NSA(Neural Architecture Search) 参数搜索
- 重新设计耗时层结构
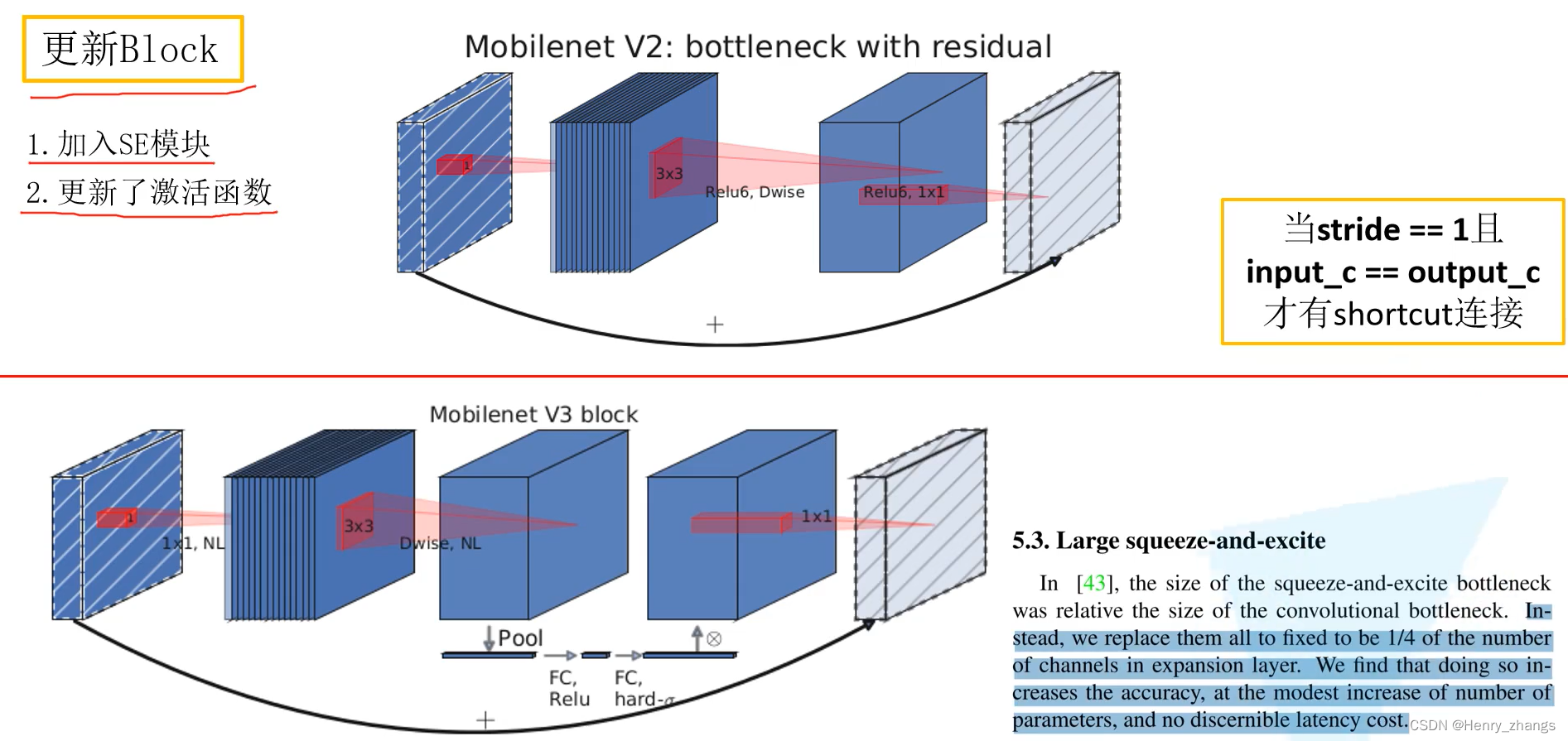
2. MobileNet V3的Block结构
如图,相比于MobileNet V2的block,MobileNet V3更新的部分有两个,更新了激活函数并且加入了SE(Squeeze-Excitation)注意力机制模块
2.1 h-swish 激活函数
非线性激活函数使用的是h-swish激活函数,对网络的正确率有重要的改进
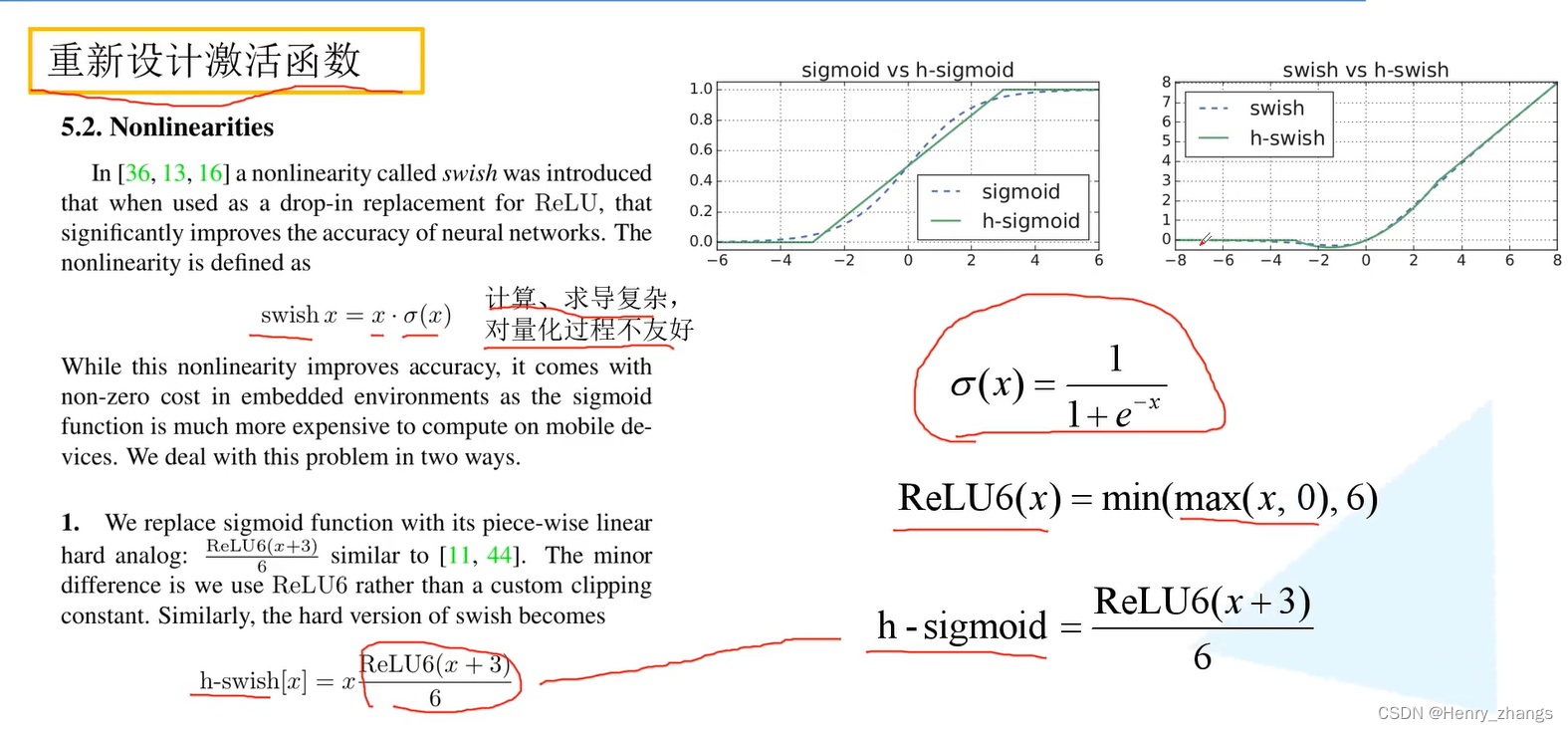
介绍h-swish之前,要介绍一下swish激活函数,swish = x * sigmoid(x) ,没有使用swish的原因是swish中的sigmoid求导很复杂。所以要想办法替代sigmoid函数
而 ReLU6( ReLU6 = min(max(x,0),6) ) 函数,不看中间y=x部分的话,两边的饱和区是和sigmoid一样的,而把ReLU6进行平移的时候,就产生了一个和sigmoid相似的函数,这里称为h-sigmoid,其中h-sigmoid = ReLU6(x + 3) / 6
所以sigmoid是类似于h-sigmoid的,那么swish函数中的sigmoid就可以换成h-sigmoid,这样就可以定义成一个新的激活函数h-swish = x*(ReLU6(x+3)/6)
这里出现了好多个函数,其实就是sigmoid和relu的变种,其中用近似sigmoid函数的就加个h,为hard的意思。若乘了x的话,就称为swish
例如:
- relu6(x+3)/6 近似于 sigmoid,那么 relu6(x+3)/6 就称为h-sigmoid
- sigmoid * x 就成为 swish
- h-swish 两者皆有,就是relu6近似sigmoid并且乘上了x,即 x * relu(x+3) / 6
代码实现上述的函数:
import numpy as np
import matplotlib.pyplot as plt
# sigmoid
def sigmoid(x):
y = 1 / (1 + np.exp(-x))
return y
# relu
def relu6(x):
y = np.minimum(np.maximum(x,0),6)
return y
# h-sigmoid
def h_sigmoid(x):
y = relu6(x+3) / 6
return y
x = np.arange(-8,8,0.1)
plt.figure(figsize=(12,8))
plt.subplot(2,2,1) # sigmoid 函数
plt.title('sigmoid')
plt.plot(x,sigmoid(x))
plt.subplot(2,2,2) # relu6 函数
plt.title('relu6')
plt.plot(x,relu6(x))
plt.subplot(2,2,3) # h-sigmoid(relu6变换)和 sigmoid相似
plt.plot(x,h_sigmoid(x),'--r',label = 'h-sigmoid')
plt.plot(x,sigmoid(x),':g',label = 'sigmoid')
plt.legend()
plt.subplot(2,2,4) # swish(x*sigmoid) 类似于 h-swish(x*h-sigmoid)
plt.plot(x,x*h_sigmoid(x),'--r',label = 'h-swish')
plt.plot(x,x*sigmoid(x),':g',label = 'swish')
plt.legend()
plt.show()
显示结果:

因此,h-swish 函数为MobileNet V3 新的激活函数,其属性与 swish = x*sigmoid(x) 曲线类似,并且h-swish中的relu计算梯度方便
2.2 SE 注意力机制
注意力机制就是将每个特征图的比重进行加权的过程,计算过程如下

这里值得注意的是,MobileNet V3中,第一个avg pooling的输入为特征图的1/4
3. 重新设计耗时层
如下,只是做了更为简单的设计,加快速度的同时还不损失精度

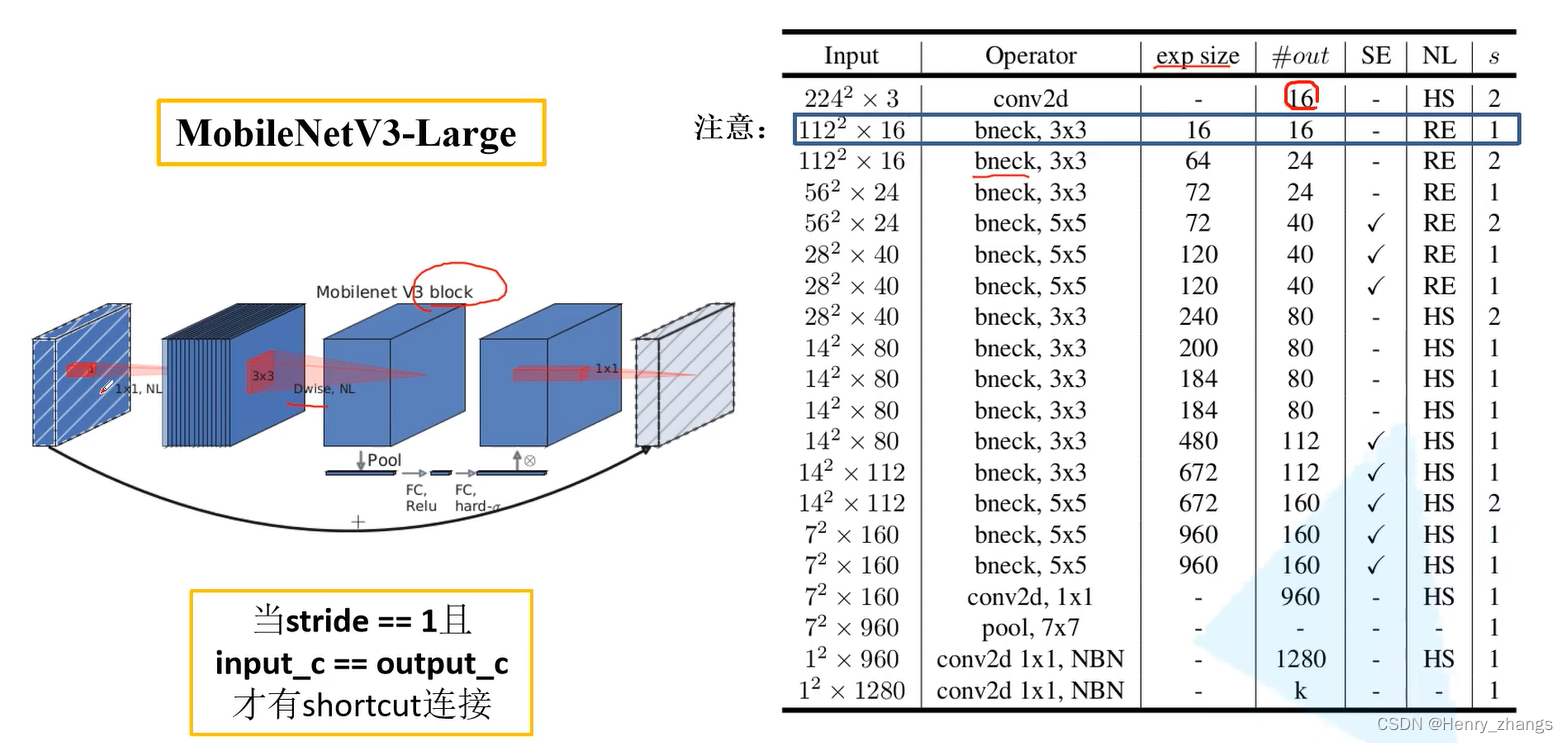
4. MobileNet V3 网络搭建
这里MobileNet V3 的网络结构如下
实现代码可以参考下,这里没看懂...
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
# 将 α 更改后的channel调整到最近的8的整数倍
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 卷积 + BN + activation
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int, # input channel
out_planes: int, # output channel
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None, # BN
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2 # 保证same 卷积,stride控制size是否减半
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
# SE 注意力机制
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4): # 第一个全连接层是输入channel的 1/4
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1) # 1*1卷积代替全连接,效果一样的
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1)) # 对每一个channel进行返回(1*1)的池化操作
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
width_multi: float): # α 参数
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se # 是否有注意力机制模块
self.use_hs = activation == "HS" # h-swish activation = x * ReLU6(x+3)/6
self.stride = stride
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
5. 迁移学习训练
官方提供的预训练权重在这里查看:找不到可以搜索 url
from torchvision.models import MobileNetV3 # 查看预训练模型这里将训练过程封装成了一个函数:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model import mobilenet_v3_large # 导入 mobilenet v3
from torch.utils.data import DataLoader
#from torchvision.models import MobileNetV3 # 查看预训练模型
def train(model,batch_size=16,lr=0.01,epochs=10,device=None):
# 预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"test": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 载入训练集
train_dataset = datasets.CIFAR10(root='./data', train=True,transform=data_transform['train']) # 下载数据集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 读取数据集
# 载入测试集
test_dataset = datasets.CIFAR10(root='./data', train=False,transform=data_transform['test']) # 下载数据集
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 读取数据集
# 样本个数
num_train = len(train_dataset) # 50000
num_test = len(test_dataset) # 10000
# 网络模型
model.to(device)
loss_function = nn.CrossEntropyLoss() # 定义交叉熵损失函数
params = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=lr) # 定义优化器
# train
best_acc = 0.0
for epoch in range(epochs):
net.train() # 开启dropout
running_loss = 0.0
for images, labels in tqdm(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 梯度下降
outputs = net(images) # 前向传播
loss = loss_function(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 梯度更新
running_loss += loss.item()
# test
net.eval() # 关闭dropout
acc = 0.0
with torch.no_grad():
for x, y in tqdm(test_loader):
x, y = x.to(device), y.to(device)
outputs = net(x)
predicted = torch.max(outputs, dim=1)[1]
acc += (predicted == y).sum().item()
accurate = acc / num_test # 计算正确率
train_loss = running_loss / num_train # 计算损失
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, train_loss, accurate))
if accurate > best_acc:
best_acc = accurate
torch.save(net.state_dict(),'./MobileNetV3.pth')
if __name__ == '__main__':
# 超参数
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 16
EPOCHS = 2
LEARNING_RATE = 0.0001
# mobilenet v3 迁移学习
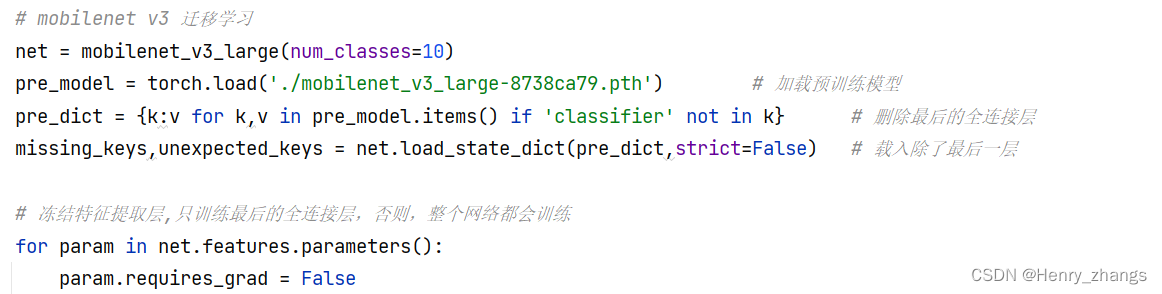
net = mobilenet_v3_large(num_classes=10)
pre_model = torch.load('./mobilenet_v3_large-8738ca79.pth') # 加载预训练模型
pre_dict = {k:v for k,v in pre_model.items() if 'classifier' not in k} # 删除最后的全连接层
missing_keys,unexpected_keys = net.load_state_dict(pre_dict,strict=False) # 载入除了最后一层
# 冻结特征提取层,只训练最后的全连接层,否则,整个网络都会训练
for param in net.features.parameters():
param.requires_grad = False
# 训练
train(model=net,batch_size=BATCH_SIZE,lr=LEARNING_RATE,epochs=EPOCHS,device=DEVICE)
print('Finished Training....')
值得注意的是,这里,只加载特征提取层的参数,并冻结这些参数
然后,在优化器这里也可以定义一下,这样更新的时候,就不会对参数全部更新
也可以不加这步,那么更新的时候,特征提取层的梯度都是0,结果是一样的

6. MobileNet V3 在CIFAR10 的表现
代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import json
import torch
import numpy as np
import matplotlib.pyplot as plt
from model import mobilenet_v3_large
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
import torchvision
# 获取 label
try:
json_file = open('./class_indices.json', 'r')
classes = json.load(json_file)
except Exception as e:
print(e)
# 预处理
transformer = transforms.Compose([transforms.Resize(256), # 保证比例不变,短边变为256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])
# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = mobilenet_v3_large(num_classes=10)
model.load_state_dict(torch.load('./MobileNetV3.pth'))
model.to(DEVICE)
# 加载数据
testSet = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)
# 获取一批数据
imgs, labels = next(iter(testLoader))
imgs = imgs.to(DEVICE)
# show
with torch.no_grad():
model.eval()
prediction = model(imgs) # 预测
prediction = torch.max(prediction, dim=1)[1]
prediction = prediction.data.cpu().numpy()
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs, labels)):
x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像
x[:, :, 0] = x[:, :, 0] * 0.229 + 0.485 # 去 normalization
x[:, :, 1] = x[:, :, 1] * 0.224 + 0.456 # 去 normalization
x[:, :, 2] = x[:, :, 2] * 0.255 + 0.406 # 去 normalization
y = label.numpy().item() # label
plt.subplot(3, 4, i + 1)
plt.axis(False)
plt.imshow(x)
plt.title('R:{},P:{}'.format(classes[str(y)], classes[str(prediction[i])]))
plt.show()
结果为:
