
MobileNet网络中的亮点:DW卷积,增加了两个超参数,控制卷积层卷积核个数的α,控制输入图像大小的β,这两个超参数是我们人为设定的,并不是学习到的。BN batch normal批规范化,为了加快训练收敛速度,提升准确率。
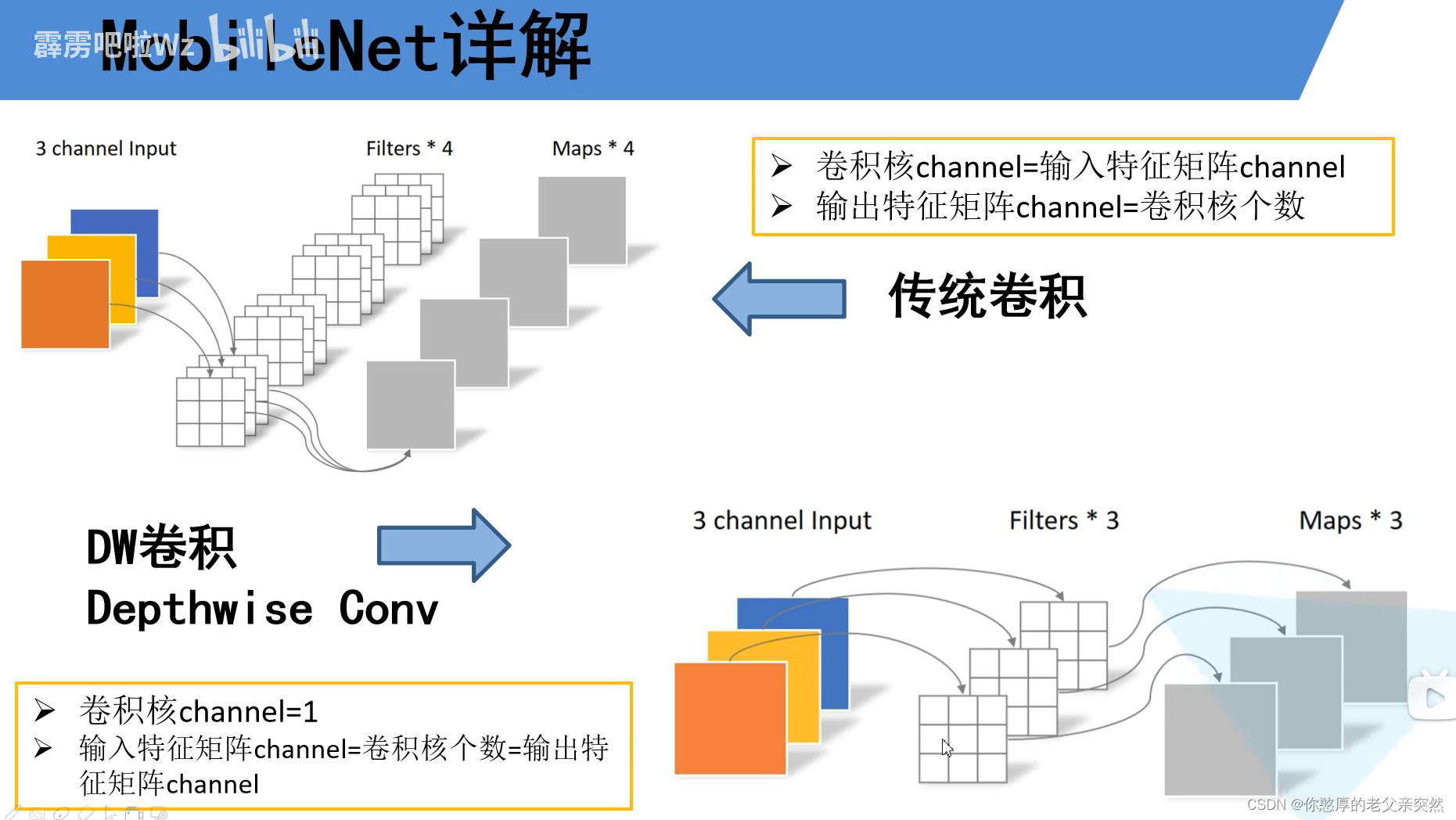
先来看传统的卷积网络,卷积核的通道数必须和输入的特征矩阵的通道数保持一致;输出特征的通道数等于卷积核的个数
而DW卷积,它的每一个卷积核的深度都是为1,一个输入特征矩阵的通道和一个卷积核进行卷积输出一个输出特征矩阵,每一个卷积核负责一个通道。
PW卷积它就是普通的卷积只不过它的卷积核的大小等于1,我们可以看到每个卷积核深度和输入矩阵的深度相同,输出特征矩阵的深度与我们卷积核的个数是相同的。通常我们的DW和PW是放到一起使用的。
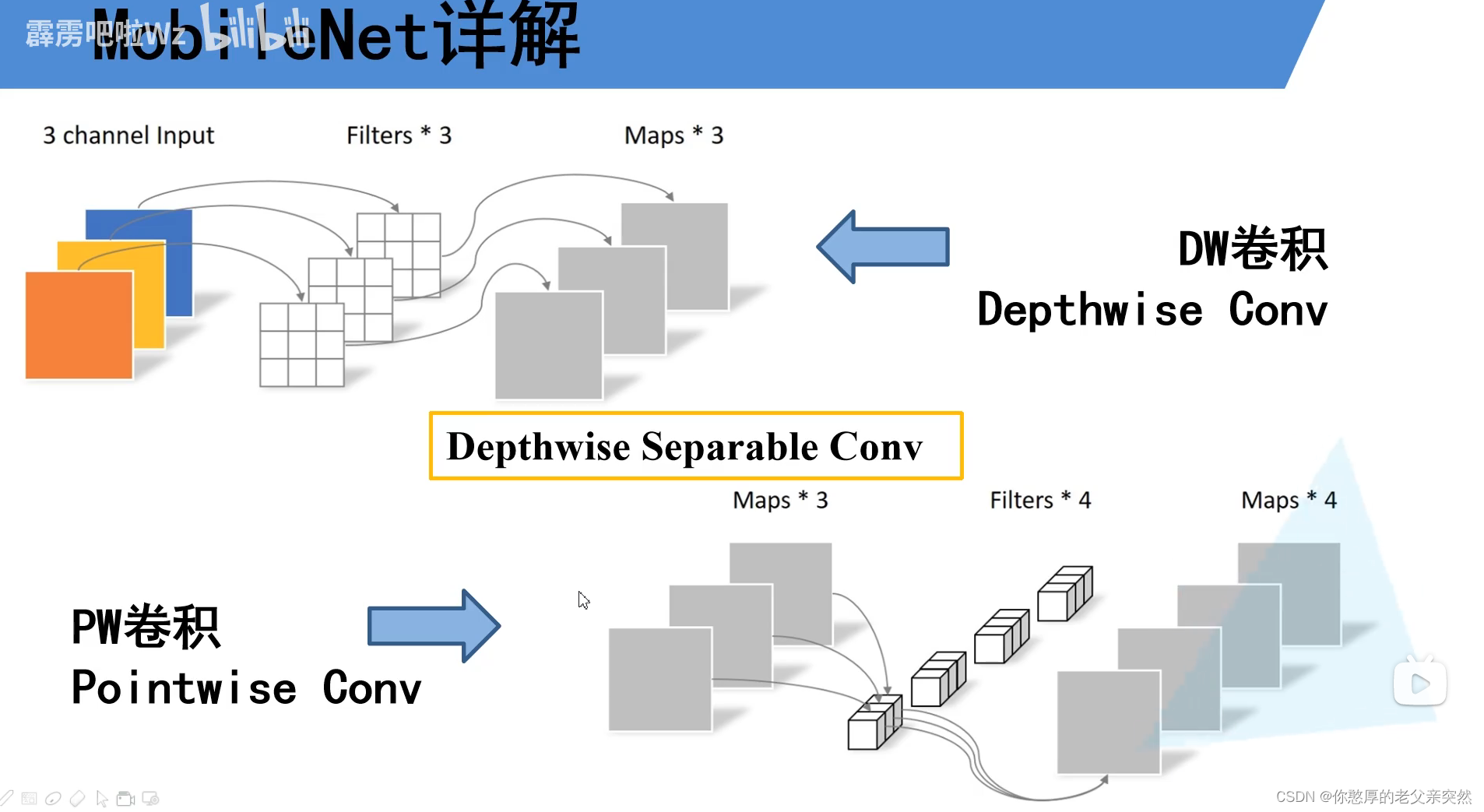
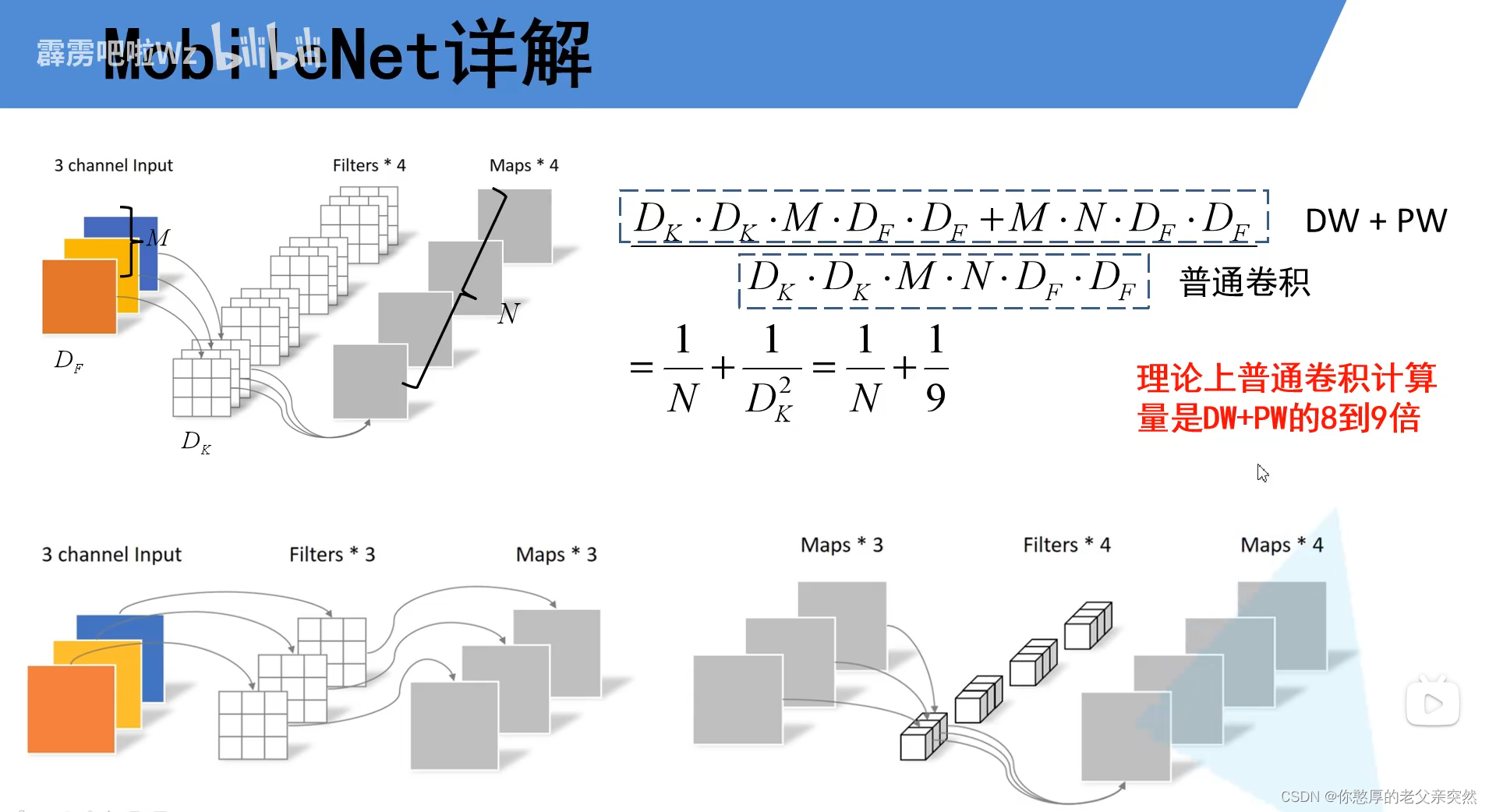
PW的输入特征矩阵等于DW的输出特征矩阵。而DW的输出特征矩阵的深度等于DW的输入特征矩阵深度。我们再对比相对于传统网络的计算量和深度可分离卷积DW+PW的计算量.
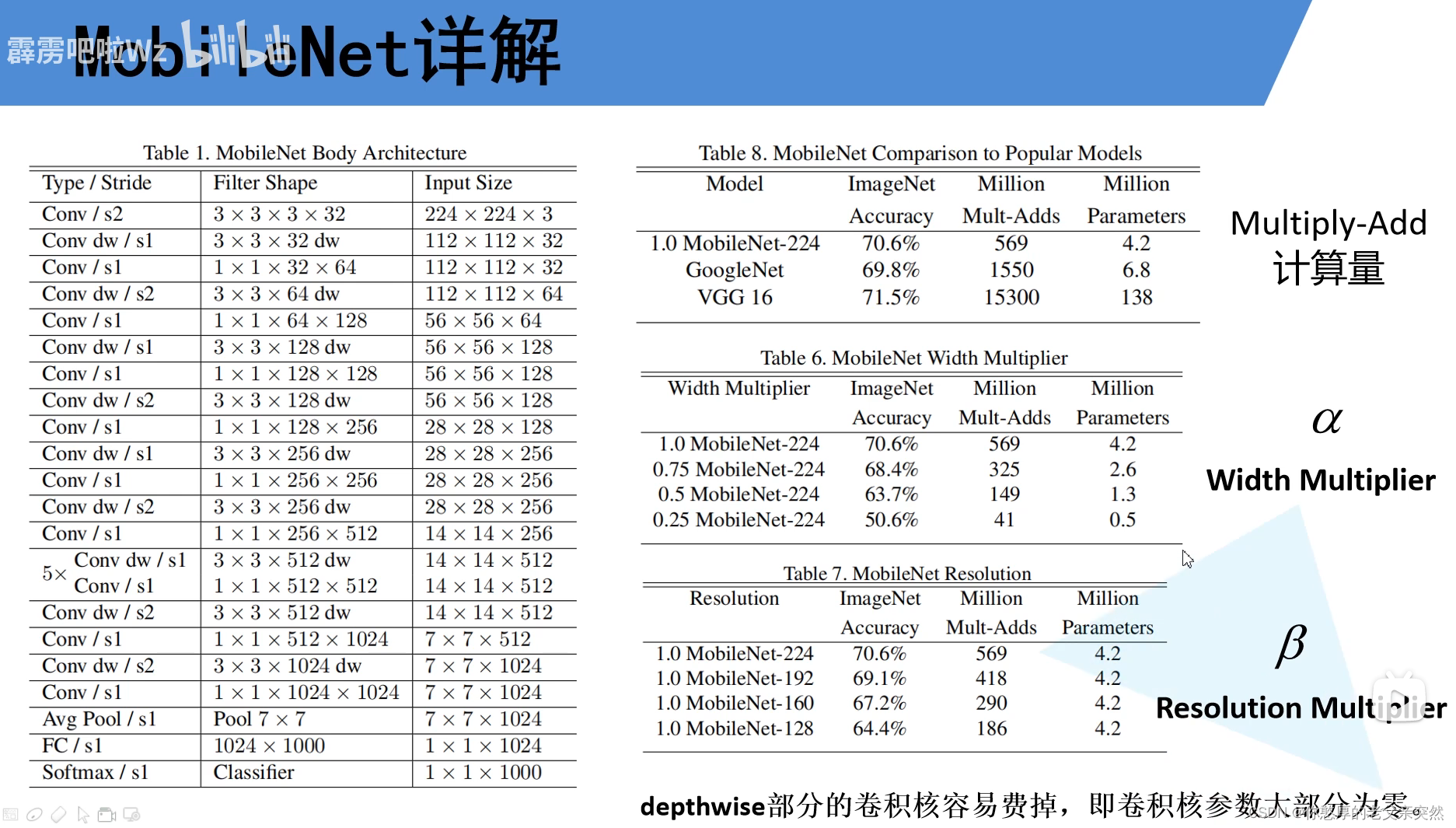
MobileNet模型
MobileNetV2

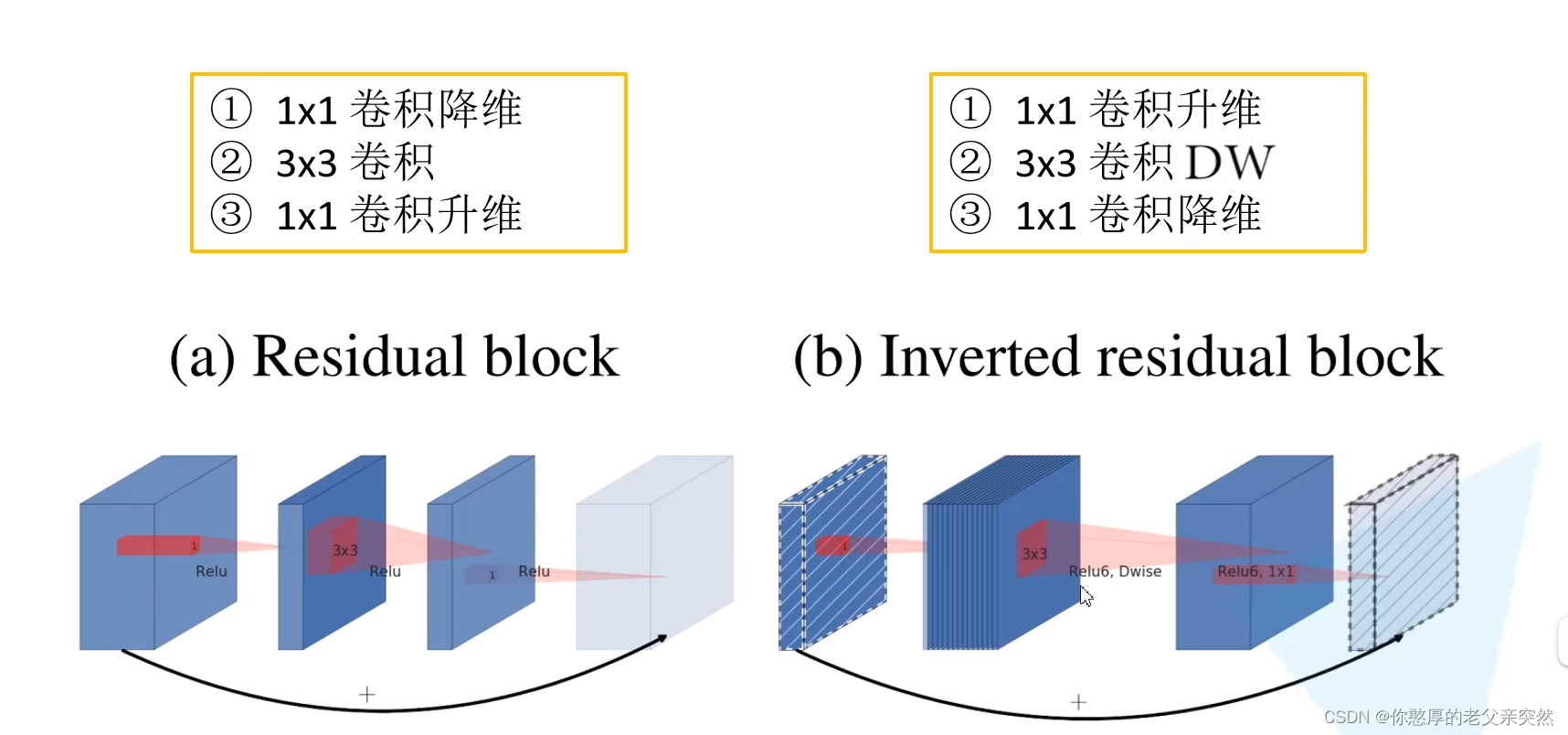
下面我们来看倒残差
普通残差是先经过1x1卷积降维,然后通过3x3卷积,之后通过1x1卷积升维。
倒残差是先经过1x1卷积升维,然后使用3x3dw卷积,之后通过1x1卷积降维
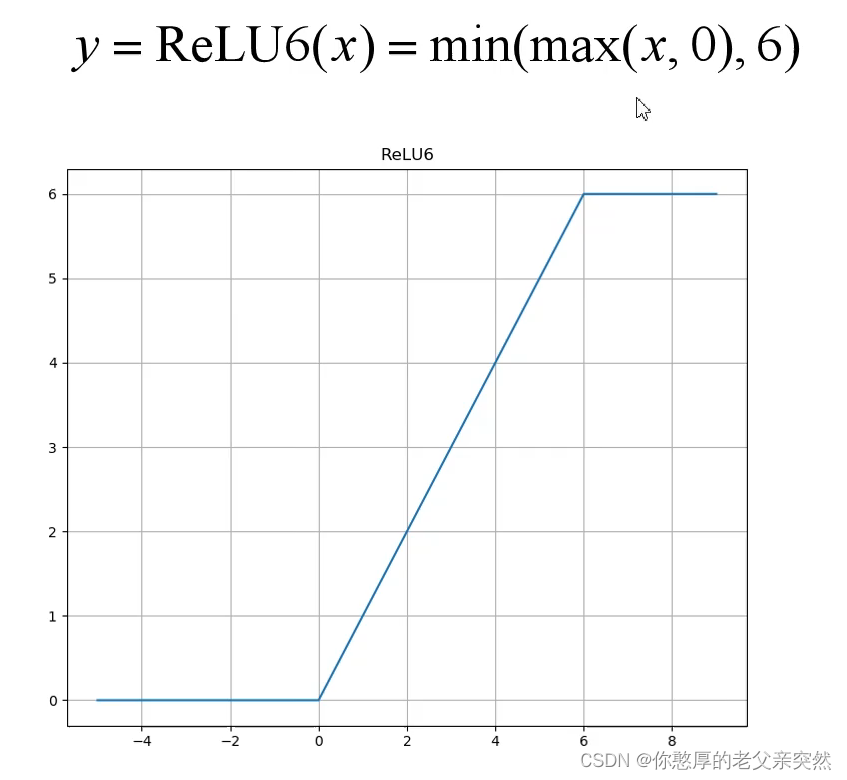
需要注意的是普通残差网络使用激活函数是ReLu,倒残差使用的激活函数是ReLu6.
在普通的Relu中,当我们的输入值小于0时那么我们默认将他置为0,当它大于0我们不对其进行处理
在Relu6中,当输入值小于0时我们将他置为0,如果在0到6的区间我们不会改变输入值,当输入值大于6的时候就会将输入值全部置为6.
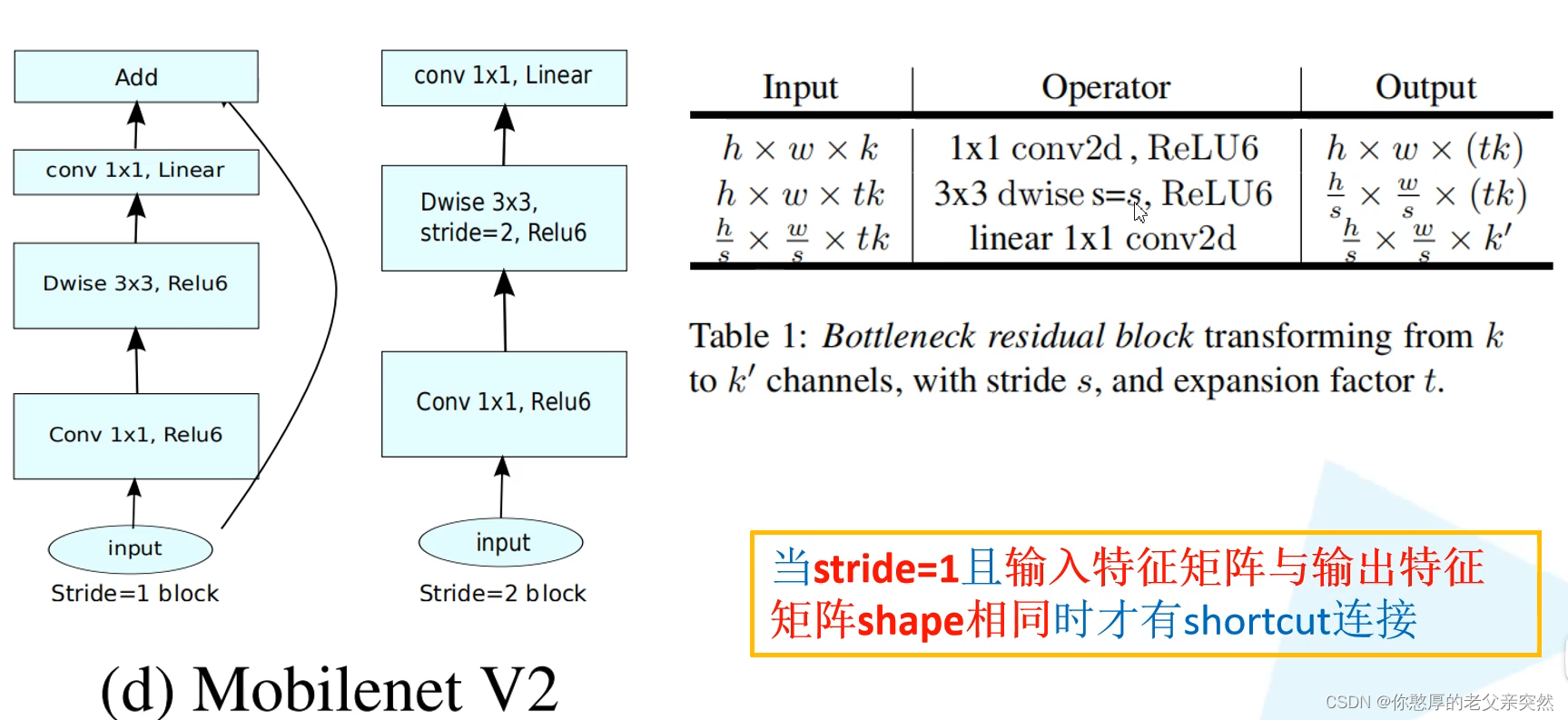
在MobileNetv2针对倒残差结构的最后一个1x1的卷积层,使用了线性激活函数,而不是Relu,因为Relu激活函数对低维特征信息造成大量损失。因为我们倒残差是两边细,中间粗的结构所以在输出的时候就是一个低维的特征向量。所以我们需要使用线性激活函数替代Relu避免信息损失。

在MobileNetv2中倒残差结构并不是每个都有shortcut连接。
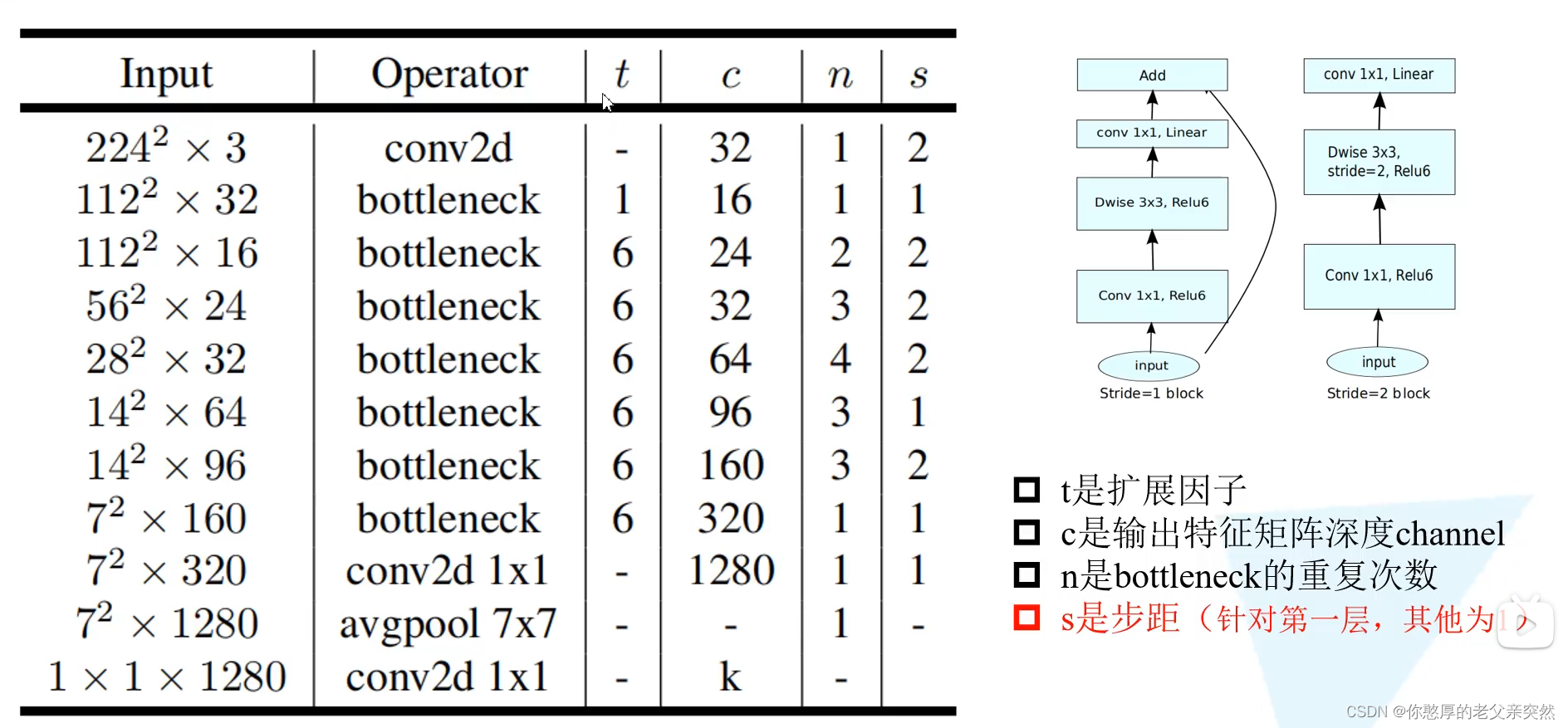
MobilenetV2模型参数
bottleneck就是倒残差
MobilenetV3
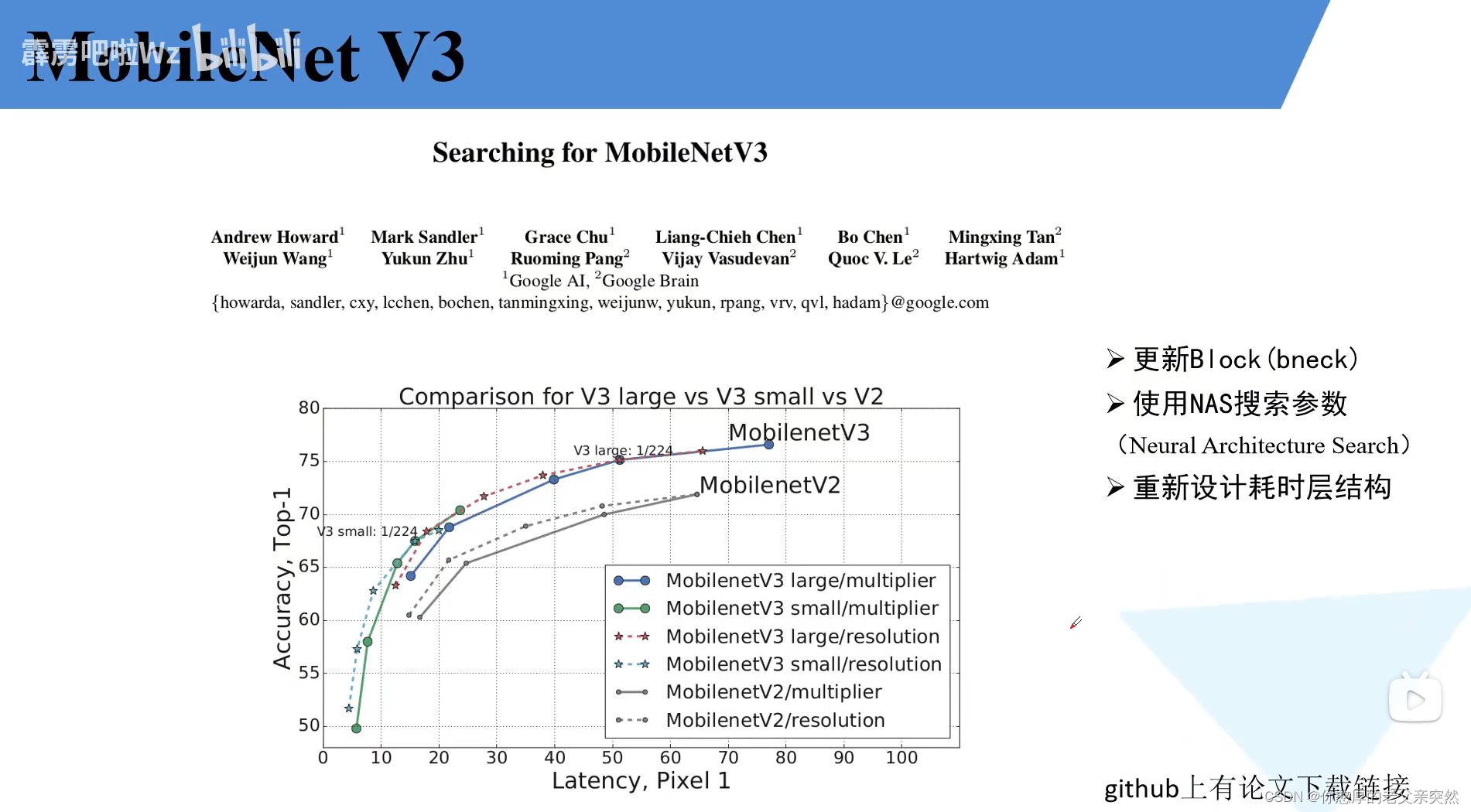
SE模块:注意力机制
注意力机制思路:针对得到的特征矩阵对其每一个通道进行池化处理然后通过两个全连接层得到输出的向量,需要注意的是对于第一个全连接层它的全连接层的节点个数等于特征矩阵channel的1/4,第二个全连接层的节点个数适于我们的特征矩阵的channel保持一致的。
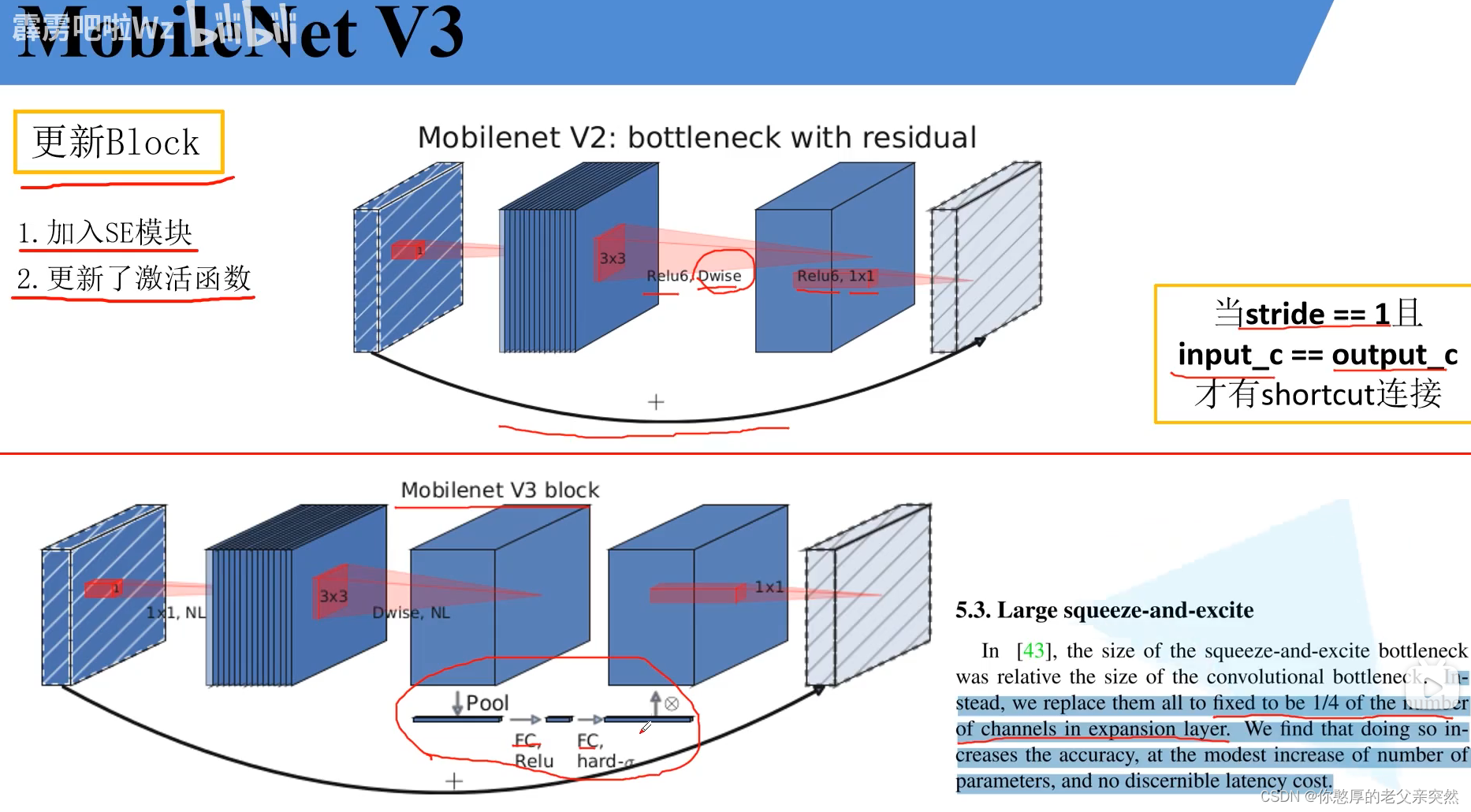
如果我们假设输入的特征矩阵的channel为2,利用平局池化得到两个向量,第一个全连接层按理说要为2的1/4,但是这里为了举例让它为2,之后利用Relu,第二个全连接层的channel和输入特征矩阵channel保持一致,为2,之后利用H-sig函数输出0.5和0.6,让0.5分别乘第一个输入的全部特征,然后让0.6分别乘第二个输入的全部特征得到新的channel数据。这就是SE模块的简单实现流程。
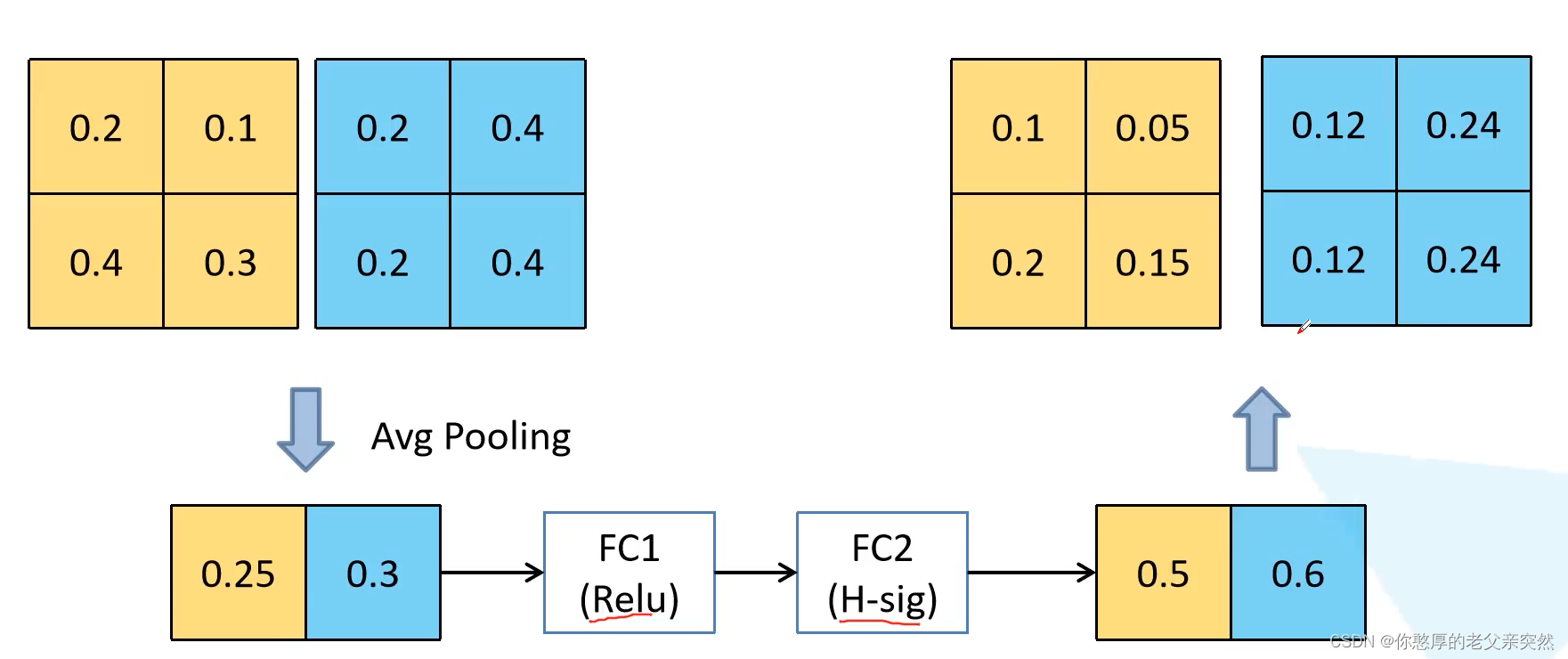
NL表示非线性激活函数,这里需要注意1x1的降维的卷积层是没有使用激活函数的,也可以说它使用的是线性激活函数。
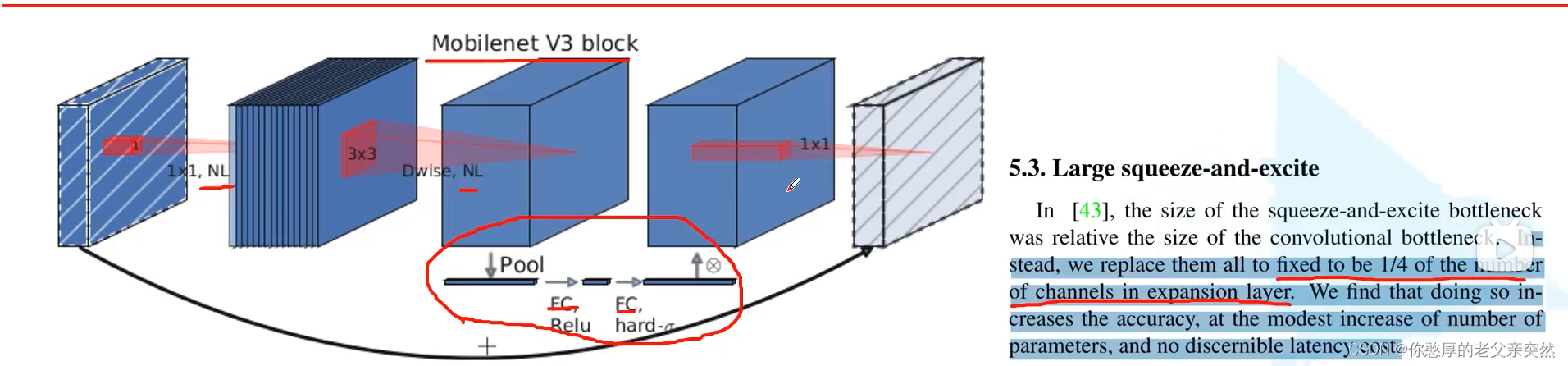
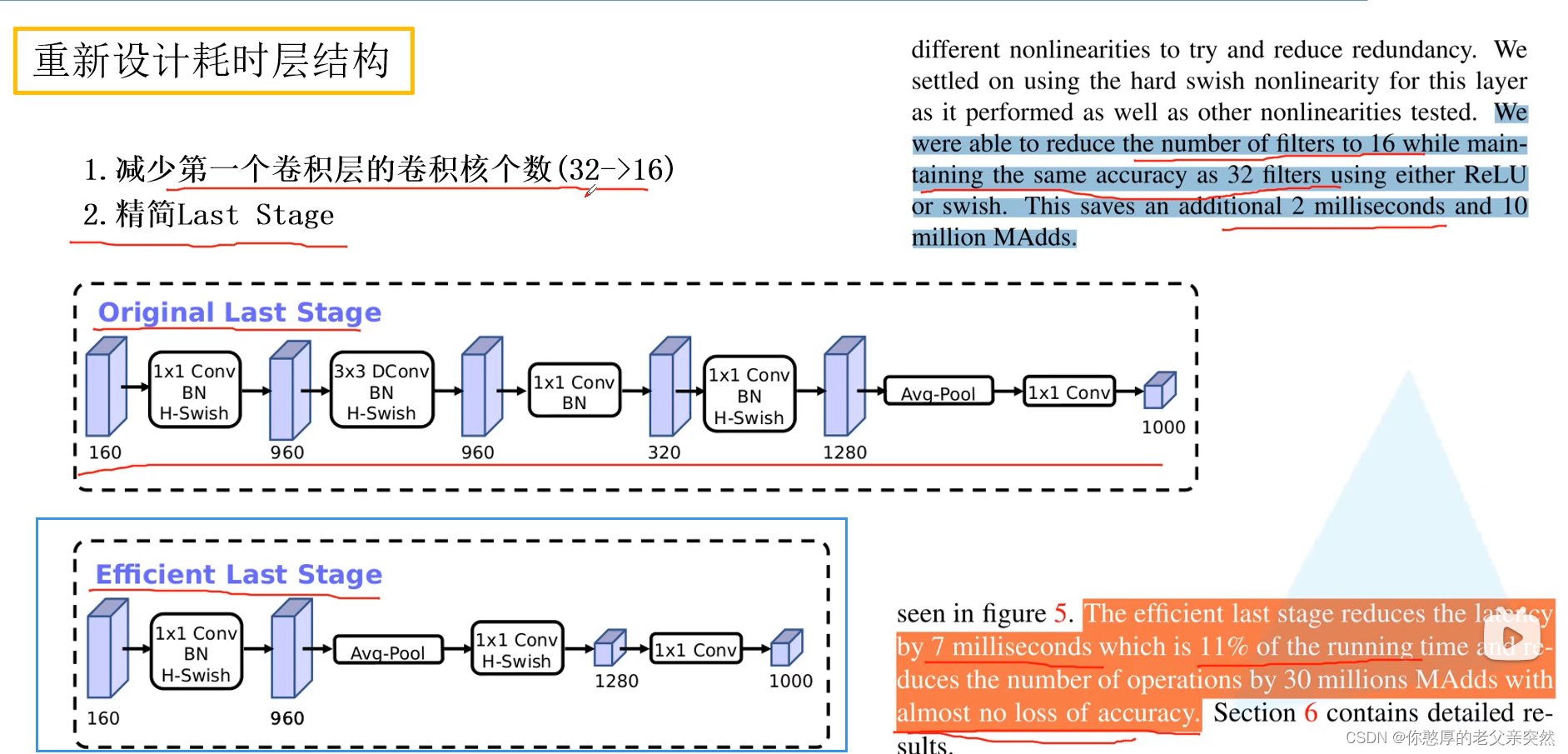
重新设计耗时层结构

MobileNetV3模型参数
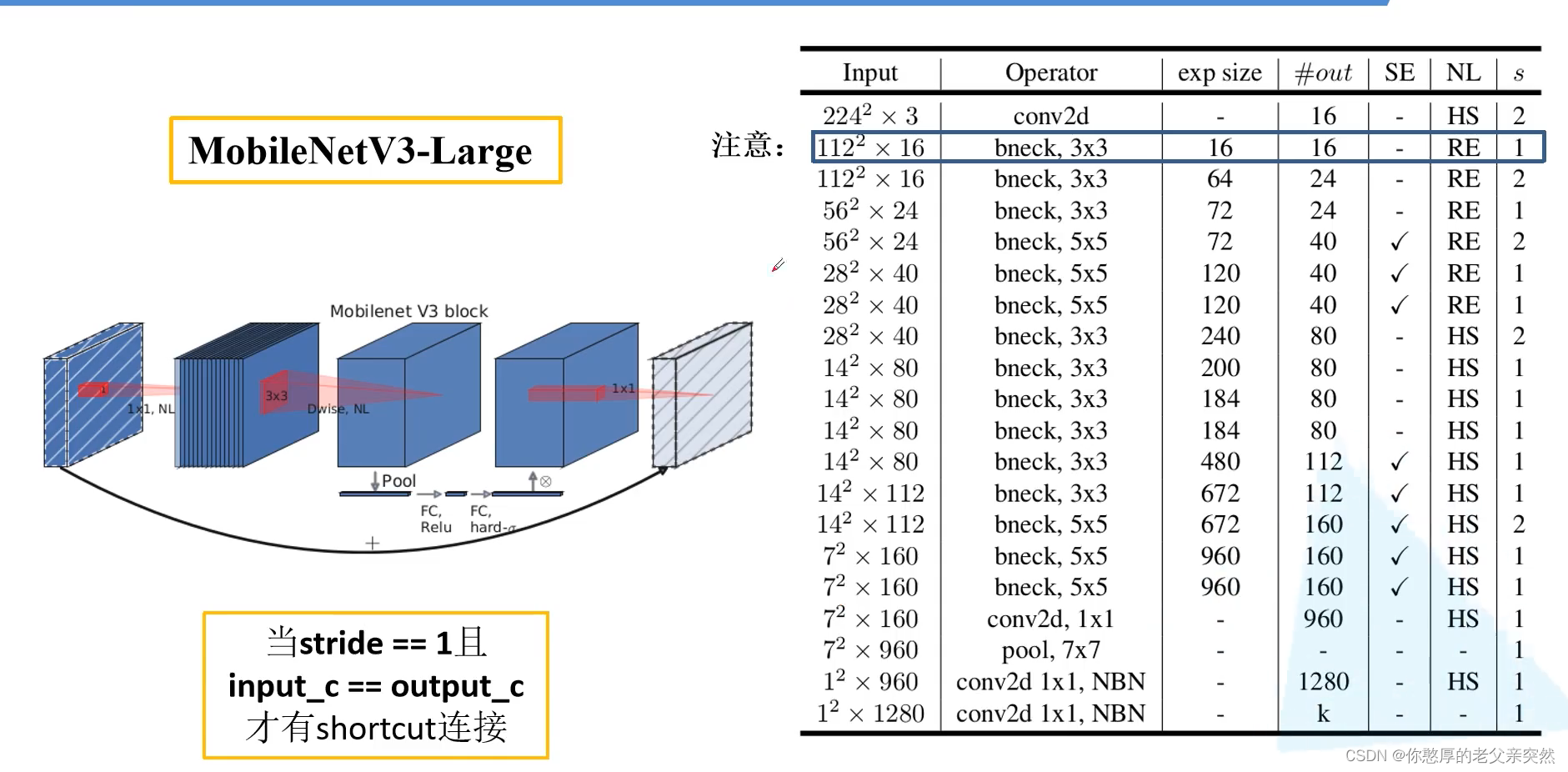
注意这里画蓝色框的部分,它的input和expsize是一样的,说明没有使用1x1进行卷积而是直接使用DW卷积输出。bneck表示DW卷积的卷积核。
expsize代表第一个升维的卷积,我们要将它的维度升到多少。这里的expsize给的多少,我们就会利用1x1的卷积将我们的特征矩阵的channel升到多少维。out对应我们使用1x1降维之后的数值。SE代表是否使用注意力机制,HS表示H-swish函数,RE表示RElu激活函数。
关于MobileNet的三个版本的介绍就到这里结束了,仅供学习和参考。