在之前的文章中讲的AlexNet、VGG、GoogLeNet以及ResNet网络,它们都是传统卷积神经网络(都是使用的传统卷积层),缺点在于内存需求大、运算量大导致无法在移动设备以及嵌入式设备上运行。而本文要讲的MobileNet网络就是专门为移动端,嵌入式端而设计。
MobileNet v1
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。
要说MobileNet网络的优点,无疑是其中的Depthwise Convolution结构(大大减少运算量和参数数量)。下图展示了传统卷积与DW卷积的差异,在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算)。
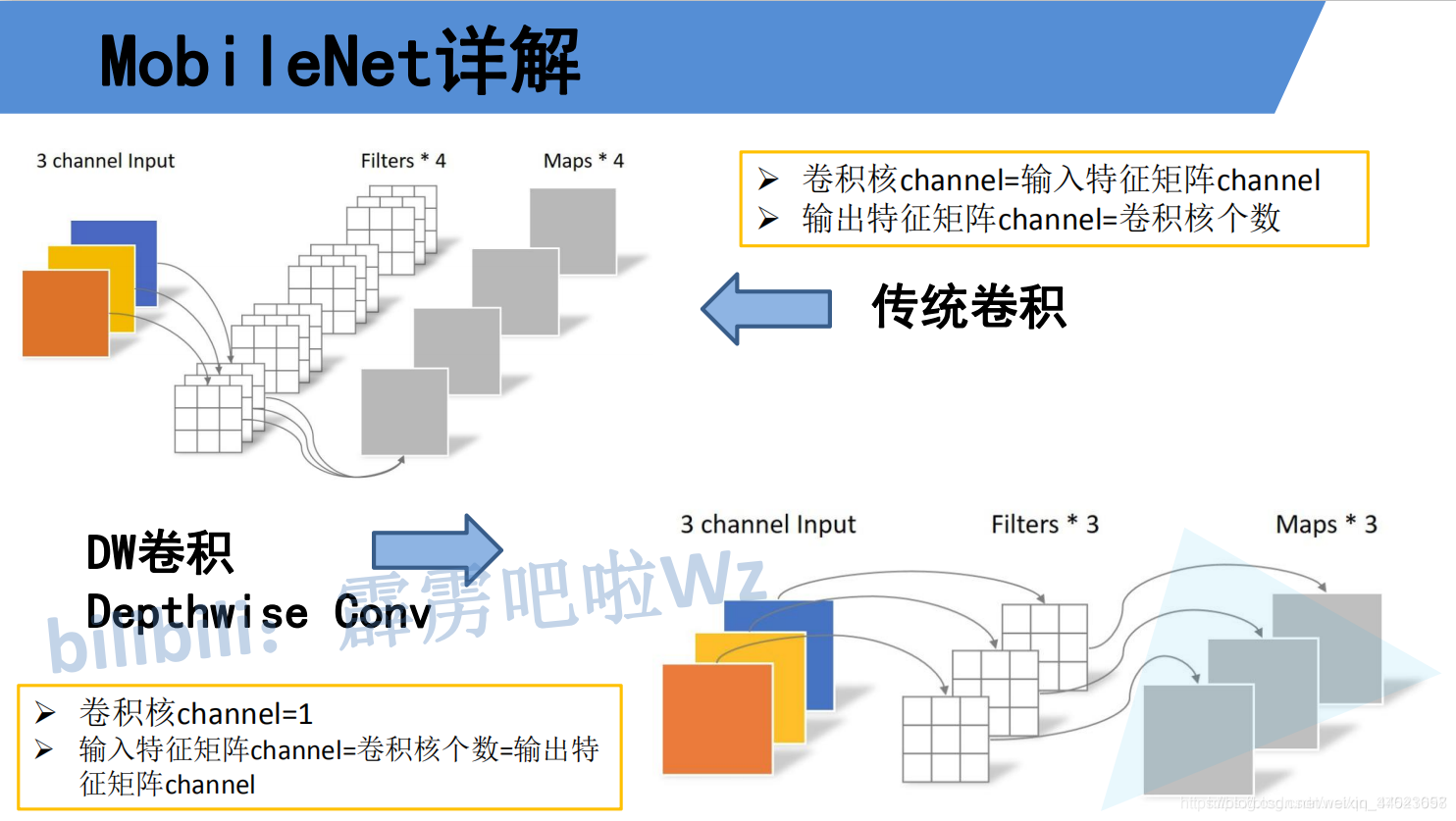
而在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数)
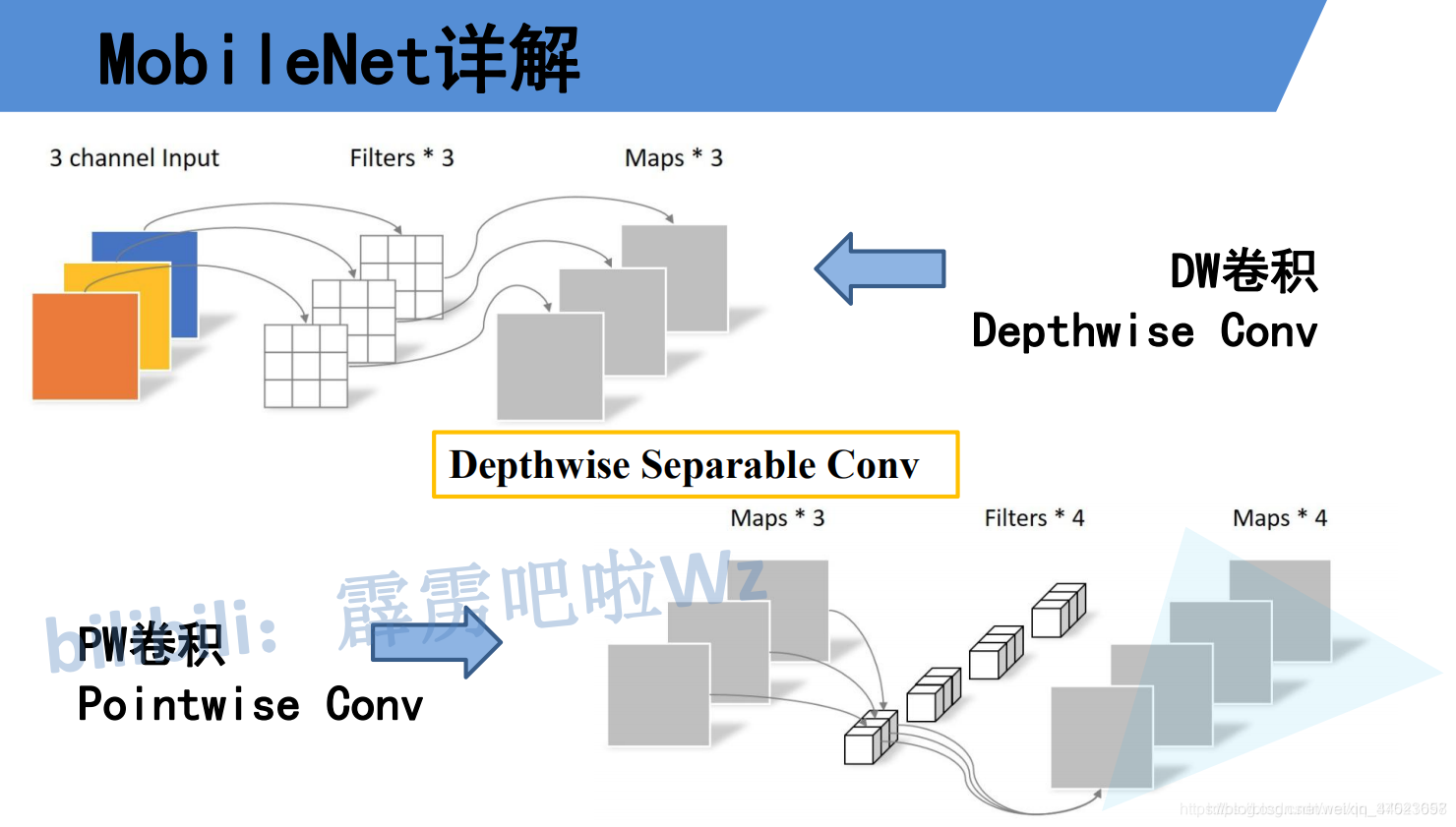
刚刚说了使用DW卷积后输出特征矩阵的channel是与输入特征矩阵的channel相等的,如果想改变/自定义输出特征矩阵的channel,那只需要在DW卷积后接上一个PW卷积即可.
如下图所示,其实PW卷积就是普通的卷积而已(只不过卷积核大小为1)。通常DW卷积和PW卷积是放在一起使用的,一起叫做Depthwise Separable Convolution(深度可分卷积)。
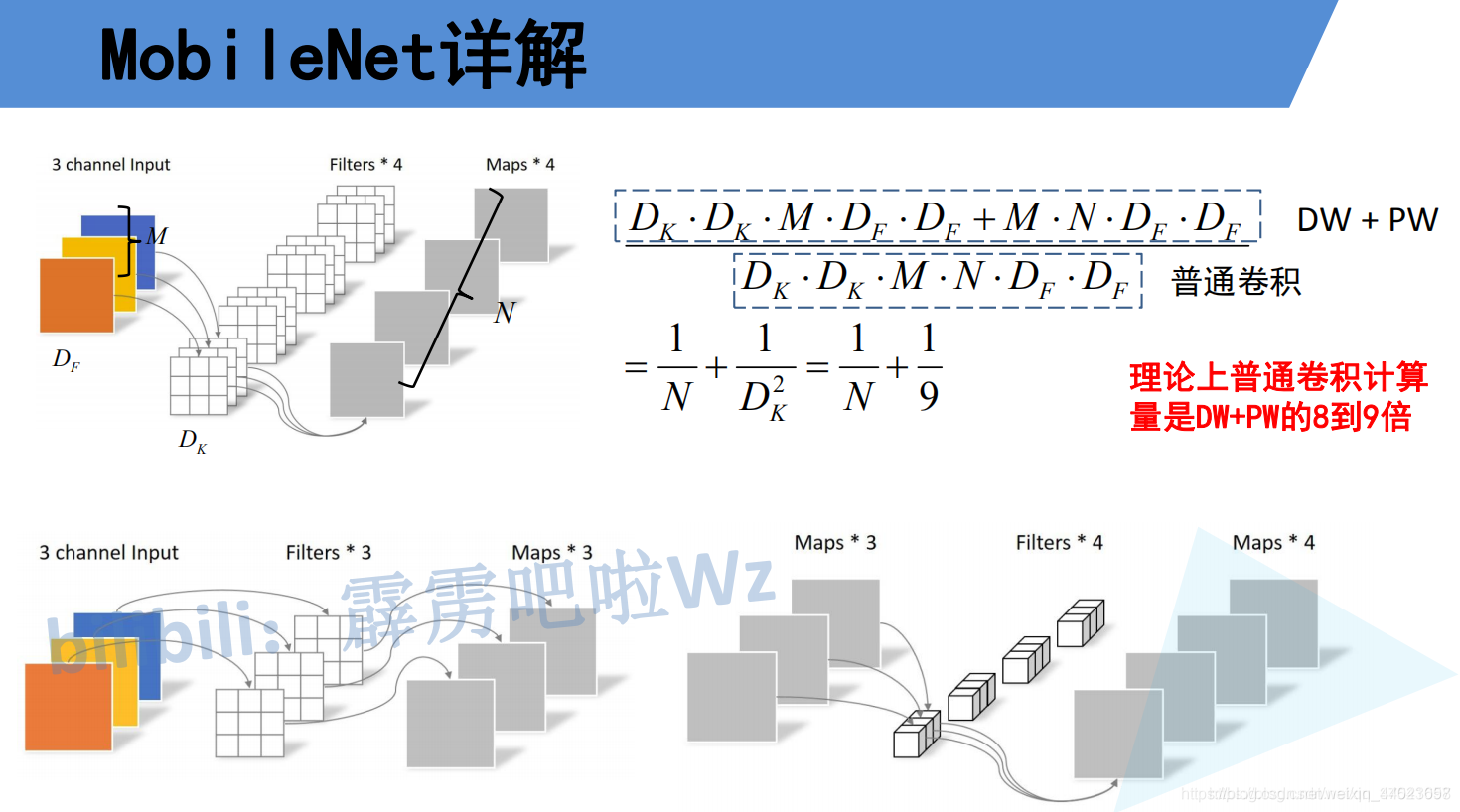
那Depthwise Separable Convolution(深度可分卷积)与传统的卷积相比有到底能节省多少计算量呢,下图对比了这两个卷积方式的计算量,其中Df是输入特征矩阵的宽高(这里假设宽和高相等),Dk是卷积核的大小,M是输入特征矩阵的channel,N是输出特征矩阵的channel,卷积计算量近似等于卷积核的高 x 卷积核的宽 x 卷积核的channel x 输入特征矩阵的高 x 输入特征矩阵的宽(这里假设stride等于1),在我们mobilenet网络中DW卷积都是是使用3x3大小的卷积核。所以理论上普通卷积计算量是DW+PW卷积的8到9倍(公式来源于原论文):
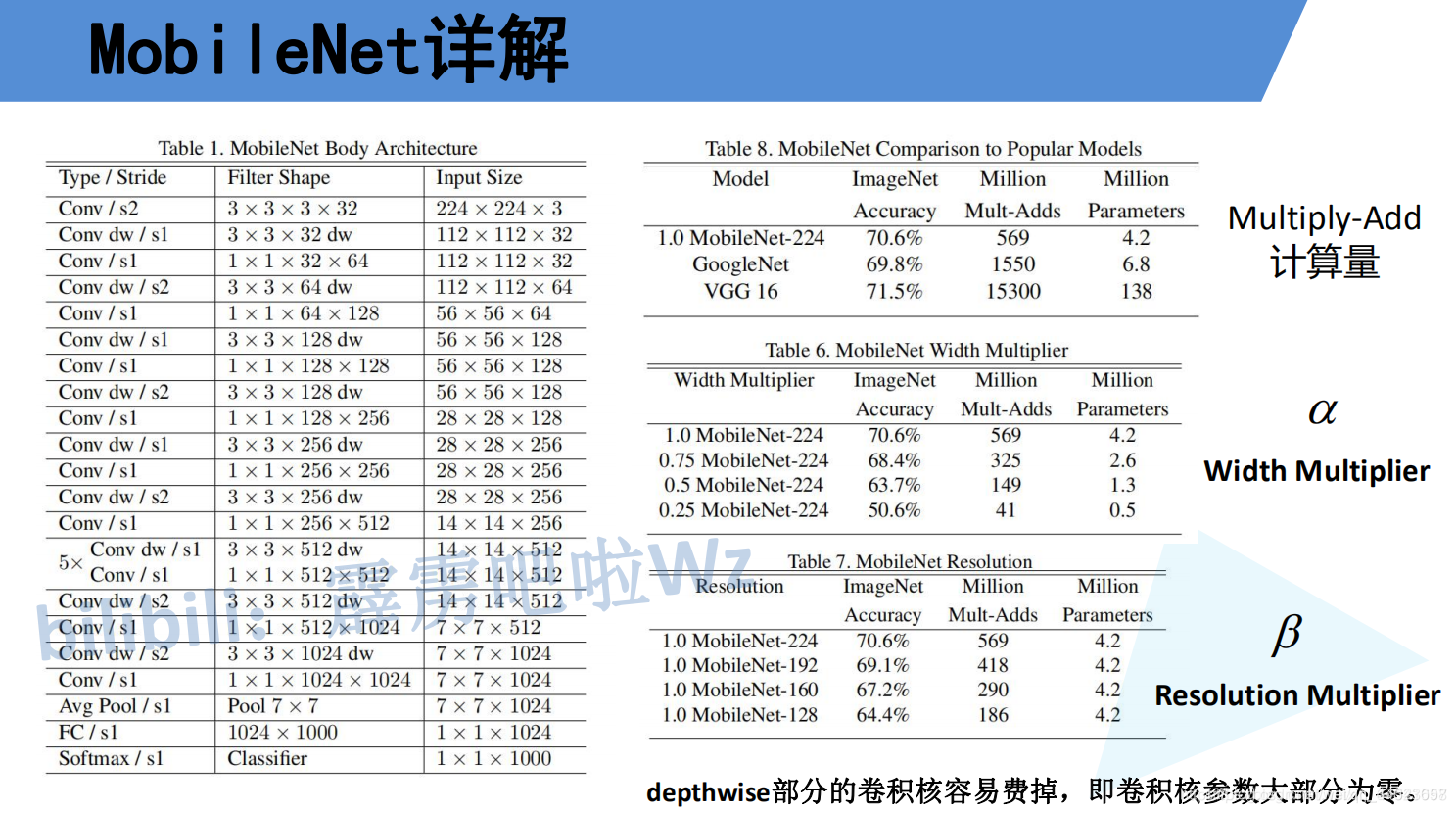
在了解完Depthwise Separable Convolution(深度可分卷积)后在看下mobilenet v1的网络结构,左侧的表格是mobileNetv1的网络结构,表中标Conv的表示普通卷积,Conv dw代表刚刚说的DW卷积,s表示步距,根据表格信息就能很容易的搭建出mobileNet v1网络。
在mobilenetv1原论文中,还提出了两个超参数,一个是α一个是β。
宽度因子
为了构造这些结构更小且计算量更小的模型,我们引入了一个参数α,称为宽度因子。宽度因子α的作用是在每层均匀地稀疏网络,为每层通道乘以一定的比例,从而减少各层的通道数。常用值有1、0.75、0.5、0.25。
分辨率因子
为了减少计算量,引入了第二个参数ρ,称为分辨率因子。其作用是在每层特征图的大小乘以一定的比例。
下图右侧给出了使用不同α和β网络的分类准确率,计算量以及模型参数:
MobileNet v2
在MobileNet v1的网络结构表中能够发现,网络的结构就像VGG一样是个直筒型的,不像ResNet网络有shorcut之类的连接方式。而且有人反映说MobileNet v1网络中的DW卷积很容易训练废掉,效果并没有那么理想。所以我们接着看下MobileNet v2网络。
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
MobileNet v2 模型的特点:
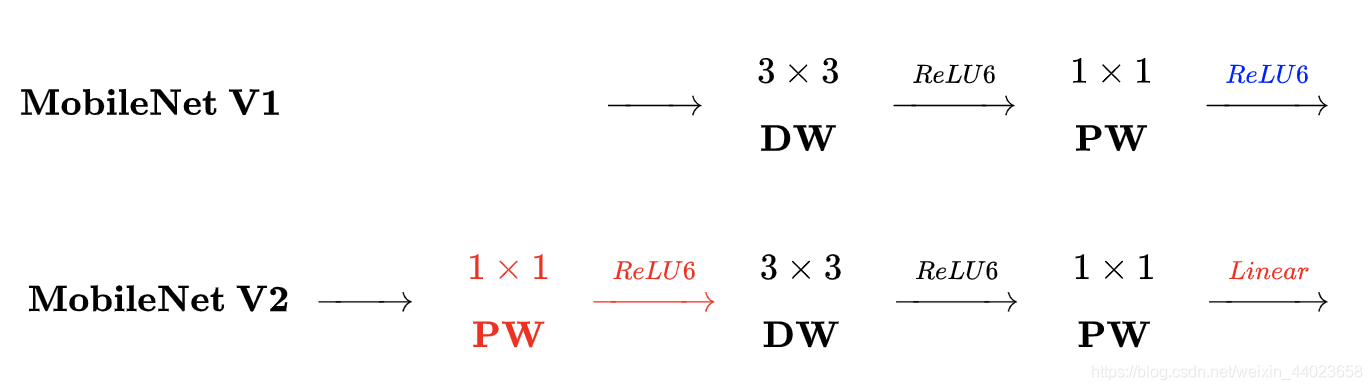 如上图,mobileNet v2在V1基础上进行了改进。
如上图,mobileNet v2在V1基础上进行了改进。
刚刚说了MobileNet v1网络中的亮点是DW卷积,那么在MobileNet v2中的亮点就是Inverted residual block(倒残差结构),同时分析了v1的几个缺点并针对性的做了改进。v2的改进策略非常简单,但是在编写论文时,缺点分析的时候涉及了流行学习等内容,将优化过程弄得非常难懂。我们在这里简单总结一下v2中给出的问题分析,希望能对论文的阅读有所帮助,对v2的motivation感兴趣的同学推荐阅读论文。
当我们单独去看Feature Map的每个通道的像素的值的时候,其实这些值代表的特征可以映射到一个低维子空间的一个流形区域上。在进行完卷积操作之后往往会接一层激活函数来增加特征的非线性性,一个最常见的激活函数便是ReLU。根据我们在残差网络中介绍的数据处理不等式(DPI),ReLU一定会带来信息损耗,而且这种损耗是没有办法恢复的,ReLU的信息损耗是当通道数非常少的时候更为明显。为什么这么说呢?我们看图6中这个例子,其输入是一个表示流形数据的矩阵,和卷机操作类似,他会经过 n个ReLU的操作得到 n个通道的Feature Map,然后我们试图通过这n个Feature Map还原输入数据,还原的越像说明信息损耗的越少。从图6中我们可以看出,当 n的值比较小时,ReLU的信息损耗非常严重,但是当n 的值比较大的时候,输入流形就能还原的很好了。

根据对上面提到的信息损耗问题分析,我们可以有两种解决方案:
- 既然是ReLU导致的信息损耗,那么我们就将ReLU替换成线性激活函数;
- 如果比较多的通道数能减少信息损耗,那么我们就使用更多的通道。
如下下图所示,左侧是ResNet网络中的残差结构,右侧就是MobileNet v2中的到残差结构。
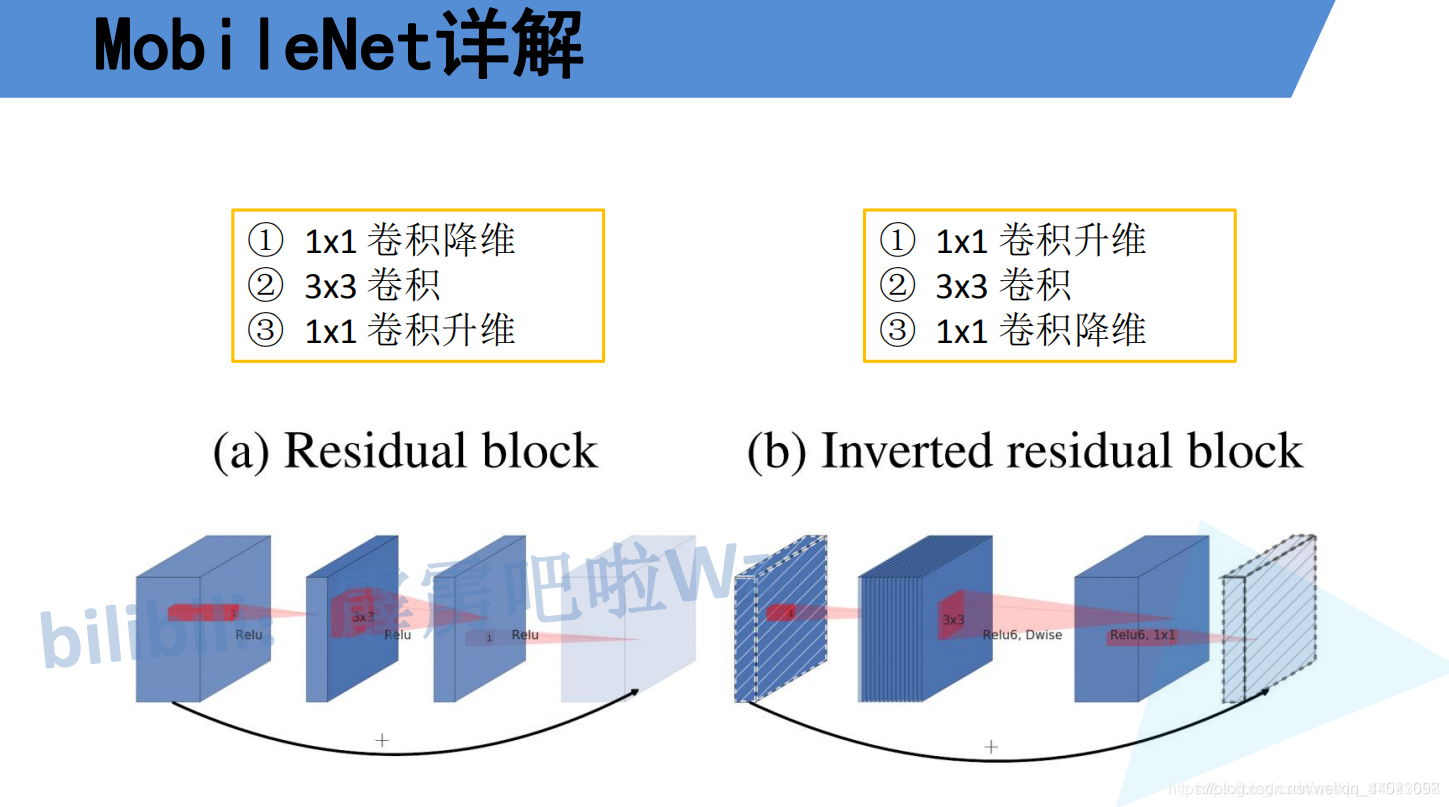
在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。
在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。
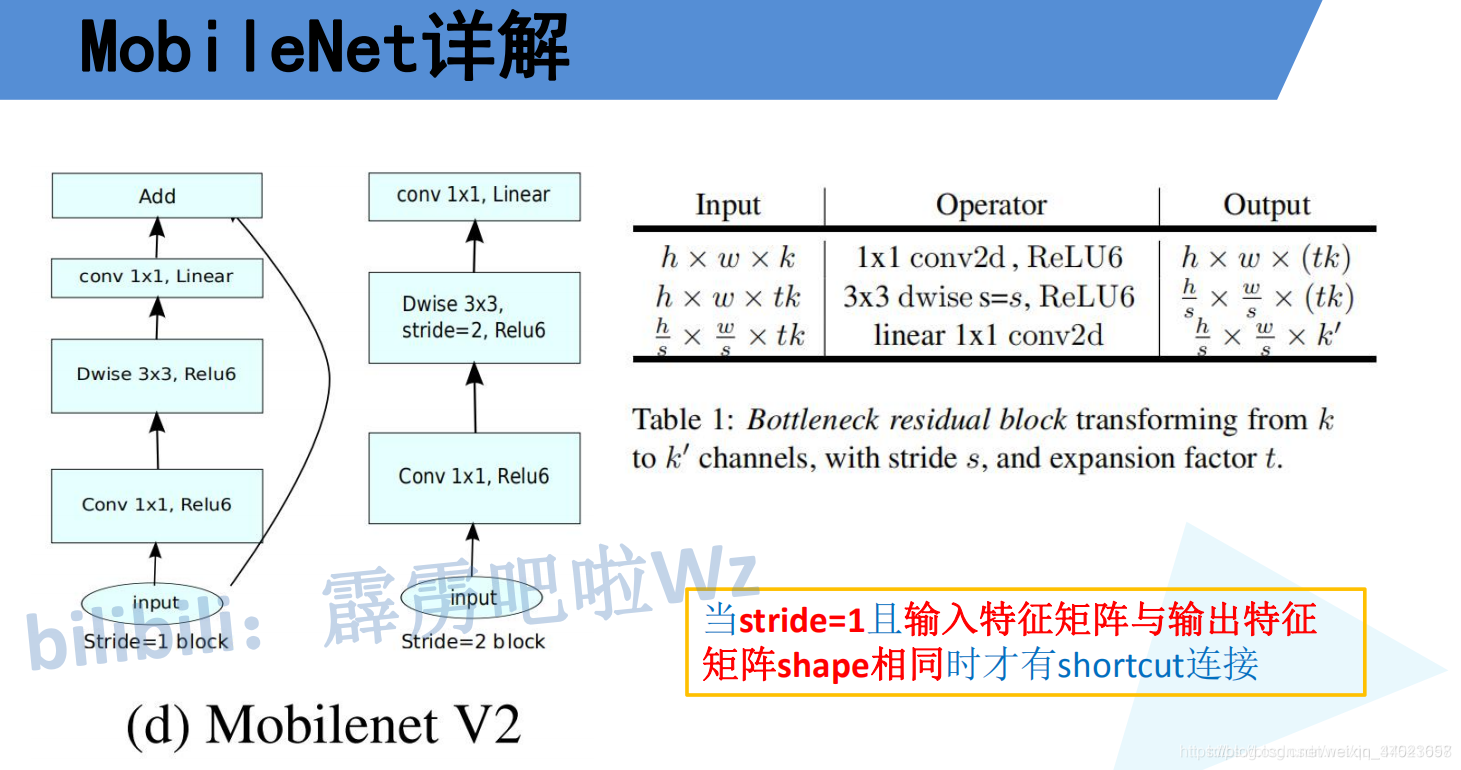
下图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。
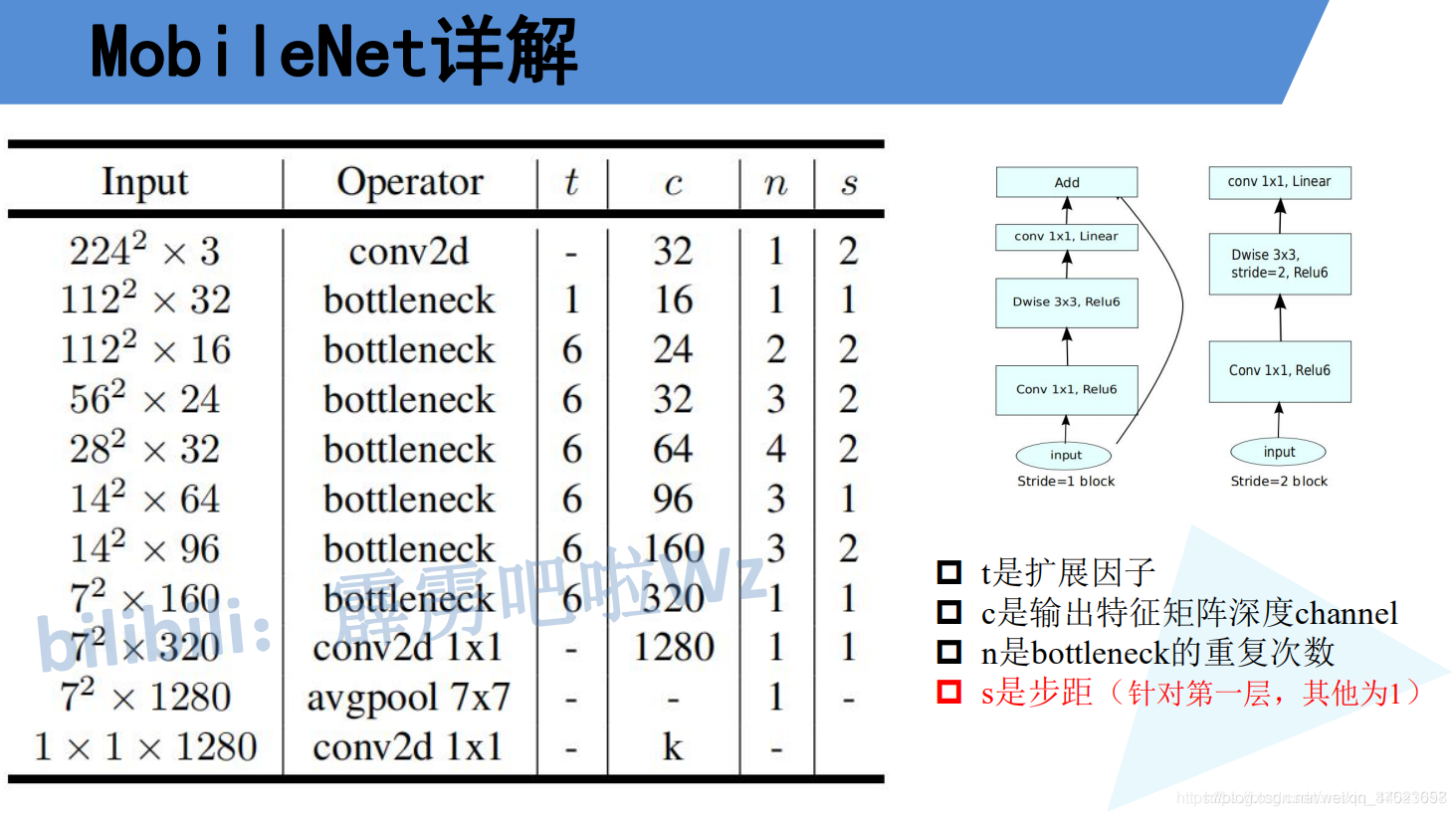
一些问题
- MobileNet V2中的bottleneck为什么先扩张通道数在压缩通道数呢?
因为MobileNet 网络结构的核心就是Depth-wise,此卷积方式可以减少计算量和参数量。而为了引入shortcut结构,若参照Resnet中先压缩特征图的方式,将使输入给Depth-wise的特征图大小太小,接下来可提取的特征信息少,所以在MobileNet V2中采用先扩张后压缩的策略。
- MobileNet V2中的bottleneck为什么在1*1卷积之后使用Linear激活函数?
因为在激活函数之前,已经使用1*1卷积对特征图进行了压缩,而ReLu激活函数对于负的输入值,输出为0,会进一步造成信息的损失,所以使用Linear激活函数。
3. 总结
在这篇文章中,我们介绍了两个版本的MobileNet,它们和传统卷积的对比如下。
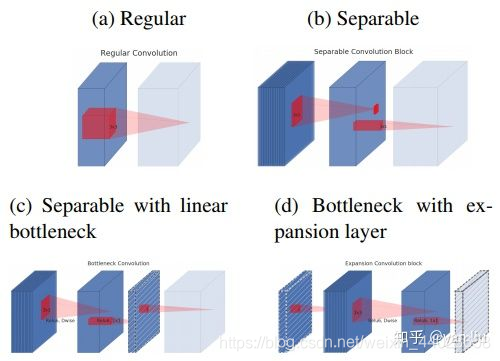
如图(b)所示,MobileNet v1最主要的贡献是使用了Depthwise Separable Convolution,它又可以拆分成Depthwise卷积和Pointwise卷积。MobileNet v2主要是将残差网络和Depthwise Separable卷积进行了结合。通过分析单通道的流形特征对残差块进行了改进,包括对中间层的扩展(d)以及bottleneck层的线性激活©。Depthwise Separable Convolution的分离式设计直接将模型压缩了8倍左右,但是精度并没有损失非常严重,这一点还是非常震撼的。
Depthwise Separable卷积的设计非常精彩但遗憾的是目前cudnn对其的支持并不好,导致在使用GPU训练网络过程中我们无法从算法中获益,但是使用串行CPU并没有这个问题,这也就给了MobileNet很大的市场空间,尤其是在嵌入式平台。
最后,不得不承认v2的论文的一系列证明非常精彩,虽然没有这些证明我们也能明白v2的工作原理,但是这些证明过程还是非常值得仔细品鉴的,尤其是对于从事科研方向的工作人员。
代码
注:
- 本次训练集下载在AlexNet博客有详细解说:https://blog.csdn.net/weixin_44023658/article/details/105798326
- 使用迁移学习方法实现收录在我的这篇blog中: 迁移学习 TransferLearning—通俗易懂地介绍(pytorch实例)
#model.py
from torch import nn
import torch
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):#groups=1普通卷积
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
#到残差结构
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):#expand_ratio扩展因子
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):#alpha超参数
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
#train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import os
import torch.optim as optim
from model import MobileNetV2
import torchvision.models.mobilenet
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../../..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path+"train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
net = MobileNetV2(num_classes=5)
# load pretrain weights
model_weight_path = "./mobilenet_v2.pth"
pre_weights = torch.load(model_weight_path)
# delete classifier weights
pre_dict = {k: v for k, v in pre_weights.items() if "classifier" not in k}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './MobileNetV2.pth'
for epoch in range(5):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')

#pridict.py
import torch
from model import MobileNetV2
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img = Image.open("sunflower.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = MobileNetV2(num_classes=5)
# load model weights
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.show()