ByteTrack: Multi-Object Tracking by Associating Every Detection Box
引言
文献阅读笔记,有翻译错误欢迎指出,一起讨论!

多目标跟踪(MOT)旨在估计视频中目标的检测框和独一身份码(ID)。大多数方法通过关联得分高于阈值的检测框来获得独一ID。检测分数低的物体,例如被遮挡的物体,被简单地丢弃,这带来了不可忽视的真实物体丢失和轨迹的中断。为了解决这个问题,我们提出了一种简单、有效和通用的关联方法,通过关联几乎每个检测框来实现跟踪,而不仅仅是高分的检测框。对于低分检测框,我们利用它们与已有轨迹的相似性来恢复真实目标,并过滤掉背景检测。当应用于9种不同的跟踪器时,我们的方法在IDF1得分上取得了一致的改善,范围从1到10分。为了展示MOT的最新性能,我们设计了一个简单而强大的跟踪器ByteTrack。首次在单个V100 GPU上以30FPS速度运行,并在MOT17测试集上实现了80.3的MOTA、77.3的DF1和63.1的HOTA。ByteTrack还在MOT20、HiEve和BDD100K跟踪基准上实现了最先进的性能。源代码、带有部署版本的预先训练的模型以及应用于其他追踪器的教程都在https://github.com/ifzhang/ByteTrack.上发布。
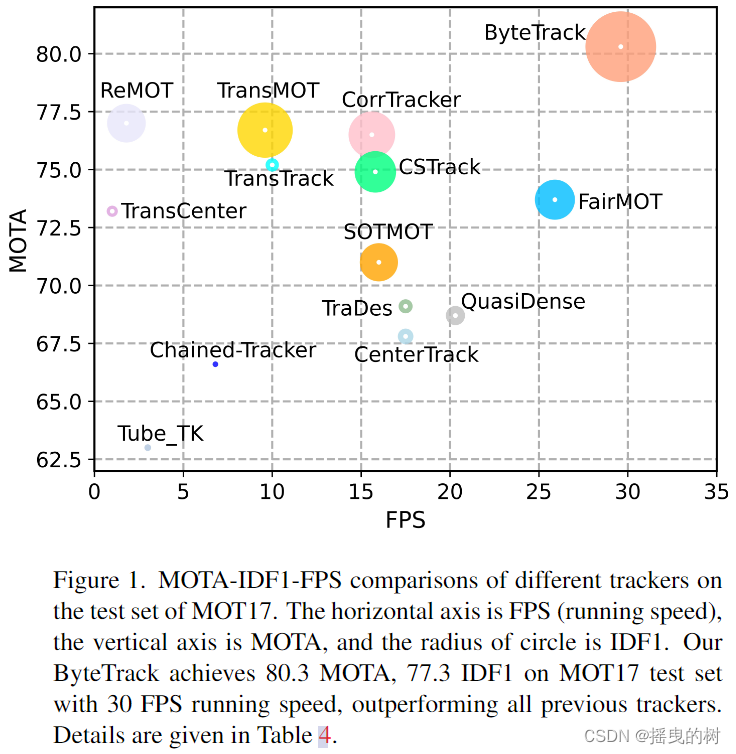
MOTA-IDF1-FPS在MOT17测试集上不同跟踪器的比较。横轴为FPS(运行速度),纵轴为MOTA,圆半径为IDF1。我们的ByteTrack在MOT17测试集上的MOTA达到80.3,IDF1达到77.3,运行速度为30 FPS,优于以往所有的跟踪器。具体情况见表4。
1 介绍

检测跟踪是目前最有效的多目标跟踪方法。由于视频场景复杂,检测器预测效果不佳。最先进的MOT方法[1-3,6,12,18,45,59,70,72,85]需要在检测框中处理真阳性和假阳性的权衡以消除低置信度检测框[4,40]。但是,消除所有低置信度检测框是正确的方法吗?我们的答案是否定的:正如黑格尔所说:“合理的就是真实的;真实的才是合理的。”低置信度检测框有时表示物体的存在,例如被遮挡的物体。过滤掉这些物体会导致MOT的不可逆误差,并带来不可忽略的漏检和中断轨迹。

图2。关联每个检测框的方法示例。(a)显示所有检测框及其评分。(b)显示了通过之前的方法获得的轨迹,该方法将得分高于阈值(即0.5)的检测框关联起来。相同的框颜色代表相同的身份。©为用我们的方法得到的轨迹。虚线框表示先前使用卡尔曼滤波的预测框。两个低分数检测框根据IoU正确匹配到前面的轨迹。
图2 (a)和(b)显示了这个问题。在t1帧中,我们初始化三个不同的轨迹,因为它们的分数都高于0.5。而在t2帧和t3帧发生遮挡时,红色轨迹对应的检测评分降低,分别从0.8到0.4,然后是从0.4到0.1。阈值机制消除了这些检测框,红色轨迹随之消失。然而,如果我们考虑到每一个检测框,更多的假阳性将被引入,例如:即图2 (a)中第t3帧的最右框。据我们所知,MOT中很少有方法[30,63]能够处理这种检测困境。
在本文中,我们发现在低分数检测框中,与轨迹的相似性为区分目标和背景提供了强大的线索。如图2 ©所示,通过运动模型的预测框,将两个低分检测框与轨迹进行匹配,从而正确地恢复目标。同时,背景框被移除,因为它没有匹配的轨迹。

为了充分利用匹配过程中从高分到低分的检测框,我们提出了一种简单有效的关联方法BYTE,以每一个检测框为轨迹的基本单位命名,如同字节在计算机程序中(角色),我们的跟踪方法对每一个的检测框进行赋值。我们首先根据运动相似度或外观相似度将高分检测框与轨迹进行匹配。与[6]相似,我们采用卡尔曼滤波[29]来预测轨迹在新帧中的位置。相似度可以通过预测框与检测框的IoU或Re-ID特征距离来计算。图2 (b)是第一次匹配后的结果。然后,我们对未匹配的轨迹进行第二次匹配,即红色方框中的轨迹与低分数检测方框使用相同的运动相似度。图2 ©显示了第二次匹配后的结果。检测分数低的被遮挡的人被正确地匹配到前面的轨迹,并且背景(在图像的右边部分)被移除。
为了推动MOT的最先进性能,我们提出了一个简单而强大的跟踪器,名为ByteTrack。我们采用最新的高性能检测器YOLOX[24]来获取检测盒,并将它们与我们提出的BYTE关联。在MOT挑战中,ByteTrack在MOT17[44]和MOT20[17]上都排名第一,在MOT17的V100 GPU上以30 FPS的运行速度实现了80.3 MOTA, 77.3 IDF1和63.1 HOTA,在更加复杂的MOT20上实现了77.8 MOTA, 75.2 IDF1和61.3 HOTA。ByteTrack还在HiEve[37]和BDD100K[79]跟踪基准上实现了最先进的性能。我们希望ByteTrack的高效和简单能使它更好地在实际中应用。
2 相关工作
2.1 多目标跟踪( MOT)中的目标检测

目标检测是计算机视觉中最活跃的话题之一,是多目标跟踪的基础。MOT17数据集[44]提供了DPM[22]、Faster R-CNN[50]和SDP等流行检测器的检测结果[77]。大量的方法[3,9,12,14,28,74,91]都是基于这些给定的检测结果来提高跟踪性能。
基于检测的跟踪:随着目标检测的快速发展[10,23,26,35,49,50,58,60],越来越多的方法开始利用更强大的检测器来获得更高的跟踪性能。单阶段目标检测器RetinaNet[35]开始被采用,如[39,48]。CenterNet[90]是大多数方法中最常用的检测器[63,65,67,71,85,87,89],其简单高效。YOLO系列探测器[8,49]也被大量采用[15,33,34,69],因为它在精度和速度上有很好的权衡。这些方法大多直接使用检测框对单幅图像进行跟踪。
然而,视频目标检测方法[41,62]指出,当视频序列中出现遮挡或运动模糊时,漏检和评分极低的检测数量开始增加。因此,通常利用前一帧的信息来提高视频检测性能。

基于跟踪的检测。也可以采用跟踪的方式来获得更精确的检测框。一些方法[12-15,53,91]利用单目标跟踪(SOT)[5]或卡尔曼滤波[29]预测下一帧中轨迹的位置,并将预测框与检测框融合,以增强检测结果。其他方法[34,86]利用前一帧中的跟踪框来增强下一帧的特征表示。最近,基于转换器的[20,38,64,66]检测器[11,92]因其在帧间传播框的能力强而被多种方法采用[42,59,80]。该方法还利用了与轨迹的相似性,增强了检测框的可靠性。
大多数MOT方法[33,39,47,59,69,71,85]在获得各种检测器的检测框后,只对高分检测框保留一个阈值,即0.5,并将高分检测框作为数据关联的输入。这是因为得分较低的检测框中包含了较多的背景,从而影响了跟踪性能。然而,我们观察到许多被遮挡的物体可以被正确地检测出来,但得分很低。为了减少漏检和保持轨迹的持续性,我们保留了所有的检测框,并在每个检测框之间进行关联。
2.2 数据关联

数据关联是多目标跟踪的核心,它首先计算轨迹与检测框之间的相似度,根据相似度利用不同的策略进行匹配。
相似性矩阵。位置、运动和外表都是关联的有用线索。SORT[6]以非常简单的方式组合了位置和运动预测。该算法首先采用卡尔曼滤波[29]来预测轨迹的位置帧,然后计算检测框与预测框之间的IoU作为相似度。最近的一些方法[59,71,89]设计了网络来学习物体运动,并在大摄像机运动或低帧率的情况下获得更鲁棒的结果。在近距离匹配中,位置和运动相似度是准确的。外观相似性有助于进行远距离匹配。物体在被遮挡较长时间后,可以通过外观相似性进行重新识别。外观相似度可以通过Re-ID特征的余弦相似度来衡量。DeepSORT[70]采用独立的Re-ID模型从检测框中提取外观特征。近年来,联合检测和Re-ID模型[33,39,47,69,84,85]因其简单高效而越来越受欢迎。
匹配策略。通过相似度计算,匹配策略为目标分配身份ID。这可以通过匈牙利算法[31]或贪婪分配[89]来实现。SORT[6]通过一次匹配将检测框匹配到轨迹。DeepSORT[70]提出了一种级联匹配策略,首先将检测框与最近的轨迹匹配,然后将检测框与失配的轨迹匹配。MOTDT[12]首先利用外观相似度进行匹配,然后利用IoU相似度对未匹配的轨迹进行匹配。QDTrack[47]通过双向softmax运算将外观相似度转化为概率,采用最近邻搜索完成匹配。注意机制[64]可以直接在帧之间传播框并进行隐式关联。最近的方法,如[42,80]提出了跟踪查询,以查找跟踪对象在以下帧中的位置。在注意交互过程中隐式进行匹配,不使用匈牙利算法。
所有这些方法都着重于如何设计出更好的关联方法。但是,我们认为检测框的使用方式决定了数据关联的上界,我们关注的是在匹配过程中如何从高分到低分充分利用检测框。
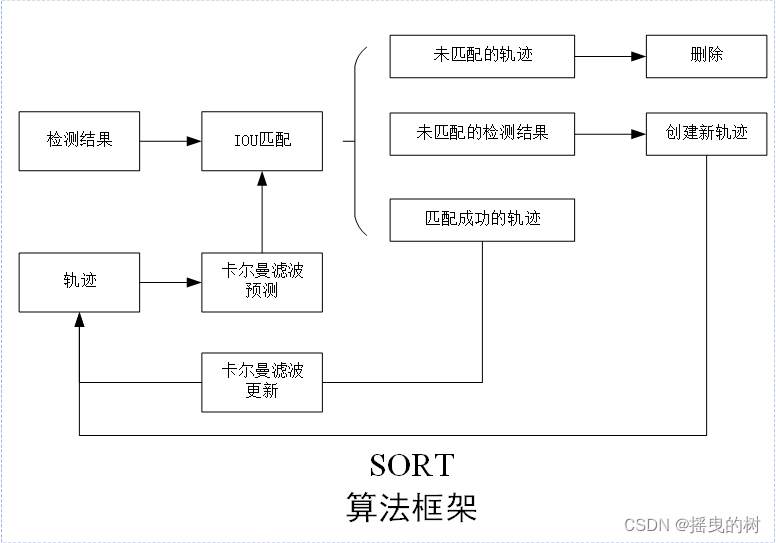
SORT算法框架如下图所示:
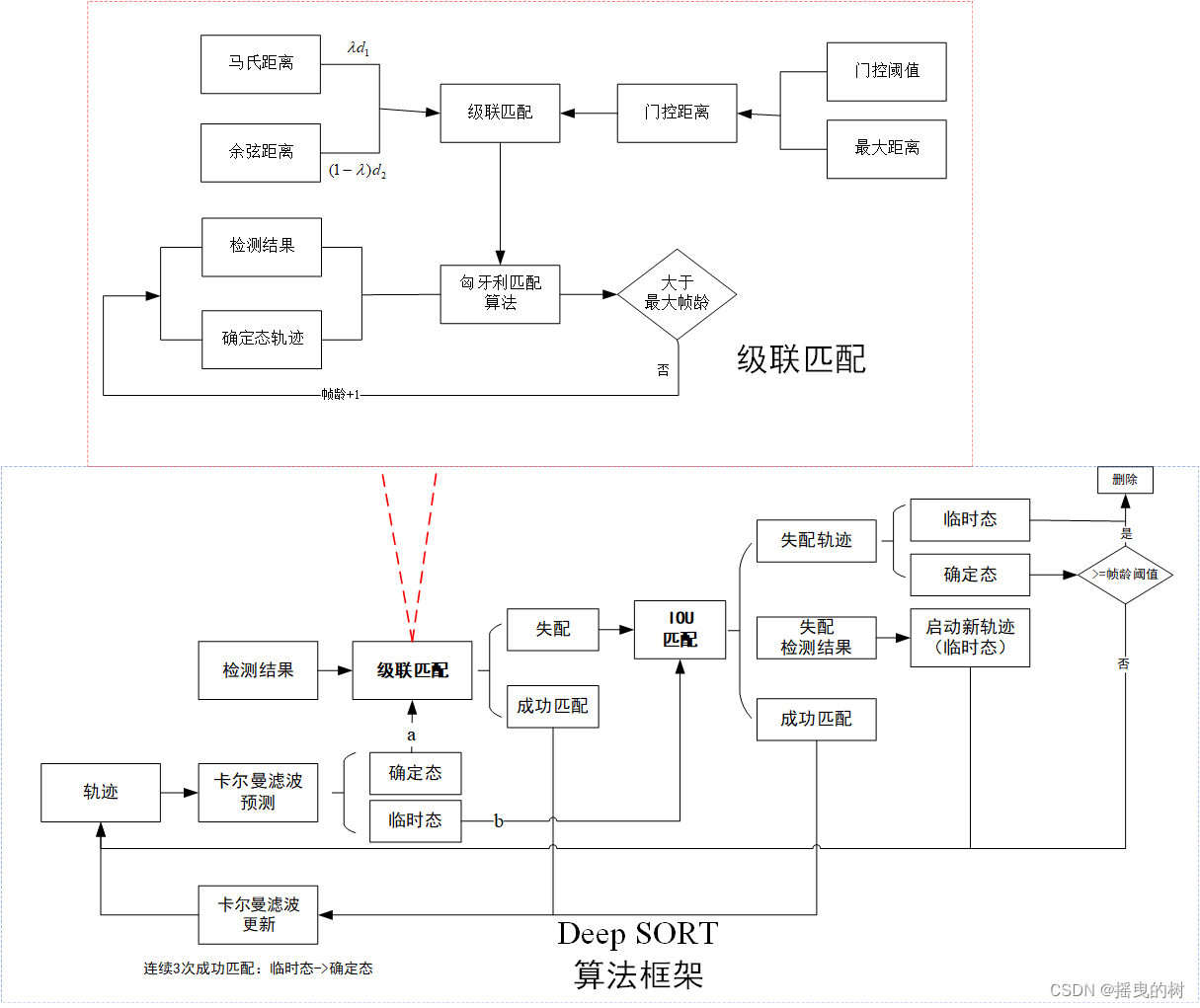
Deep SORT算法框架如下图所示:
3 BYTE

我们提出了一种简单、有效、通用的数据关联方法BYTE。与以往的方法[33,47,69,85]只保留高分检测框不同,我们几乎保留了所有的检测框,并将其分为高分检测框和低分检测框。我们首先将高分检测框与轨迹函数相关联。有些轨迹不匹配是因为它们没有匹配到合适的高分检测框,这通常发生在遮挡、运动模糊或大小变化发生时。然后,我们将低分检测框和这些不匹配的轨迹关联起来,以恢复低分检测框中的对象并同时过滤掉背景。BYTE的伪代码如算法1所示
BYTE的输入是一个视频序列 V V V,以及一个物体检测器 D e t Det Det。我们还设置了一个检测分数阈值 τ τ τ。BYTE的输出是视频的轨迹集合 T T T,每一个轨迹都包含每一帧中物体的边界框和独一标识符ID。
对于视频中的每一帧,我们使用检测器 D e t Det Det预测检测盒和分数。我们根据检测分数阈值 τ τ τ将所有检测盒分为 D h i g h D_{high} Dhigh和 D l o w D_{low} Dlow两个部分。对于分数高于 τ τ τ的检测框,我们将其放入高分检测框 D h i g h D_{high} Dhigh中。对于分数低于 τ τ τ的检测框,我们将它们放入低分数检测框 D l o w D_{low} Dlow(算法1中的第3到13行)。

将低分检测框和高分检测框分离后,采用卡尔曼滤波对当前帧内轨迹集合 T T T中的每条轨迹的新位置进行预测(算法1中的第14 - 16行)。
第一个关联是在高分检测框 D h i g h D_{high} Dhigh和所有轨迹 T T T(包括丢失的轨迹 T l o s t T_{lost} Tlost,这里笔者认为是初始帧中的所有检测结果都初始化为轨迹)之间进行的。第一次相似度关联可以通过IoU或者通过检测框 D h i g h D_{high} Dhigh和轨迹T预测框的Re-ID特征距离来计算。然后,采用匈牙利算法[31]根据相似性完成匹配。我们在 D r e m a i n D_{remain} Dremain中保留未匹配的检测,在 T r e m a i n T_{remain} Tremain中保留未匹配的轨迹(算法1中的第17 - 19行)。
BYTE具有高度的灵活性,可以兼容其他不同的关联方法。例如BYTE与FairMOT[85]结合时,在算法1的* first association *中加入了Re-ID特性,其他均相同。在实验中,我们将BYTE应用于9种不同的最先进的跟踪器,并在几乎所有指标上都取得了显著的改进。
第二次关联在低分检测框 D l o w D_{low} Dlow和第一次关联后剩下的轨迹 T r e m a i n T_{remain} Tremain之间执行。我们保留 T r e − r e m a i n T{re−remain} Tre−remain中未匹配的轨迹,只删除所有未匹配的低分数检测框,因为我们将它们视为背景。(算法1中的第20到21行)。我们发现在第二种关联中单独使用IoU作为第二次相似性关联是很重要的,因为低分检测框通常包含严重的遮挡或运动模糊,外观特征不可靠。因此,当将BYTE应用到其他基于Re-ID的跟踪器[47,69,85]时,我们在第二个关联中不采用外观相似性。
关联之后,不匹配的轨迹将从轨迹集合中删除。为了简单起见,我们在算法1中没有列出轨迹再生的过程[12,70,89]。实际上,为了保持轨迹的同一性,远程关联是必要的。对于第二次关联后的不匹配的轨迹,我们把它们归入失联。对于 T l o s t T_{lost} Tlost中的每个轨迹,只有当它存在的帧数超过一定数量时,即30,我们才从轨迹集合 T T T中删除它。否则,我们保留轨迹集合 T T T中的失联的轨迹 T l o s t T_{lost} Tlost(算法1中的第22行)。最后,在第一次关联之后,我们从不匹配的高分检测框 D r e m a i n D_{remain} Dremain初始化新的轨迹。(算法1中的第23 - 27行)。每一帧的输出是当前帧中轨迹集合 T T T的边界框和独一标识符ID。注意,我们不输出失配轨迹 T l o s t T_{lost} Tlost的框和ID。
为了实现MOT最先进的性能,我们设计了一个简单而强大的跟踪器ByteTrack,通过将我们的关联方法BYTE安装在高性能检测器YOLOX[24]上。

为了简单,算法中没有显示轨迹重生[70,89]。绿色的是方法的关键。
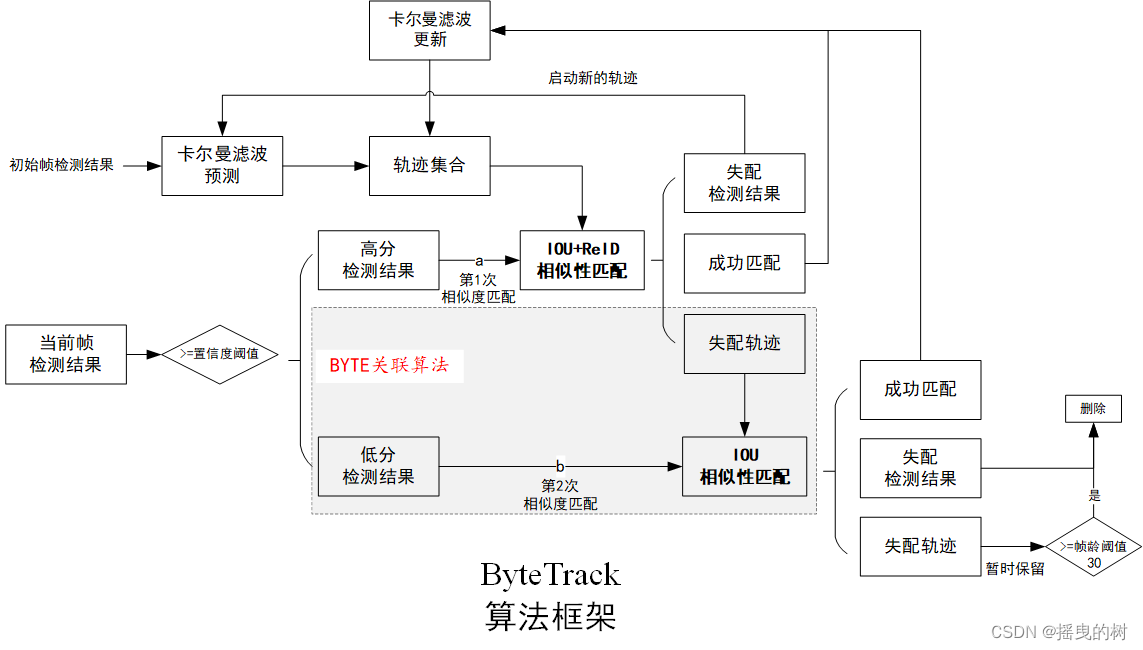
笔者将算法可视化如下图所示:
4 实验
4.1 实验设置

数据集:我们在“自定义检测”协议下评估MOT17[44]和MOT20[17]数据集上的BYTE和ByteTrack。两个数据集都包含训练集和测试集,但没有验证集。对于消融实验,我们使用MOT17训练集中每个视频的前半部分进行训练,后半部分进行验证[89]。我们在组合CrowdHuman数据集[55]和一半的MOT17训练集上进行训练[59,71,80,89]。在MOT17的测试集上进行测试时,我们添加了Cityperson[82]和ETHZ[21]用于[33,69,85]后续的训练。我们还在HiEve[37]和BDD100K[79]数据集上测试了ByteTrack。HiEve是一个以人为中心的大型数据集,专注于拥挤和复杂的事件。BDD100K是最大的驾驶视频数据集,MOT任务的数据集分割为1400个训练视频、200个验证视频和400个测试视频。它需要跟踪8类对象,并包含大型相机运动的情况。
指标:我们使用CLEAR指标[4],包括MOTA, FP, FN,ID等,IDF1[51]和HOTA[40]来评估跟踪性能的不同方面。MOTA是根据FP、FN和ID计算的。考虑到FP和FN的数量大于ID, MOTA更关注检测性能。IDF1评估身份保持能力,更关注关联性能。HOTA是最近提出的一个指标,它明确地平衡了执行精确检测、关联和定位的效果。对于BDD100K数据集,有一些多类指标如mMOTA和mIDF1。mMOTA / mIDF1是通过所有类的MOTA / IDF1的平均值来计算的。
实现细节:对于BYTE,检测评分阈值 τ τ τ默认为0.6,除非另有指定。对于MOT17、MOT20和HiEve的基准评价,我们只使用IoU作为相似度指标。在线性分配步骤中,如果检测框和轨迹框之间的IoU小于0.2,则拒绝匹配。对于失配的轨迹(即未成功匹配的轨迹),我们保留30帧以防它再次出现。对于BDD100K,我们使用UniTrack[68]作为Re-ID模型。在消融研究中,我们使用FastReID[27]提取MOT17的Re-ID特征。
对于ByteTrack,检测器是YOLOX [24], YOLOX - X作为骨干,COCO预训练的模型[36]作为初始权值。对于MOT17,训练策略是在MOT17、CrowdHuman、Cityperson和ETHZ的组合数据集上的80类别。对于MOT20和HiEve,我们只添加了CrowdHuman作为额外的训练数据。对于BDD100K,我们不使用额外的训练数据,只训练50个epoch。输入图像大小为1440×800,多尺度训练时最短边为576到1024。数据增强包括Mosaic[8]和Mixup[81]。模型在8个NVIDIA Tesla V100 GPU上训练,批处理大小为48个。优化器为SGD,权值衰减为 5 × 1 0 − 4 5 × 10^−4 5×10−4,动量为0.9。初始学习率为 1 0 − 3 10^−3 10−3,1个epoch执行模型预热和余弦退火策略。训练总时间约为12小时。在[24]之后,FPS是在单个GPU上用FP16-精度[43]和批量大小为1计算得到。
4.2 BYTE消融实验

相似性分析。我们为BYTE的第一个关联和第二个关联选择不同类型的相似度。结果如表1所示。在MOT17数据集上IoU或Re-ID都是相似度#1的较佳选择。IoU获得更好的MOTA和ID,而Re-ID获得更高的IDF1。在BDD100K上,Re-ID在第一次关联时取得了比IoU更好的结果。这是因为BDD100K包含较大的摄像机运动,注释帧率低,导致运动提示失败。重要的是在两个数据集的第二次关联中利用IoU作为相似度#2,因为低分检测框通常包含严重的遮挡或运动模糊,因此Re-ID特征是不可靠的。从表1中我们可以发现,使用IoU作为相似度#2比Re-ID增加了约1.0 MOTA,这说明低分检测箱的Re-ID特征并不可靠。
与其他关联方法的比较。我们将BYTE与其他流行的关联方法进行了比较,包括SORT[6]、DeepSORT[70]和MOTDT[12]在MOT17和BDD100K的验证集上。结果如表2所示。
SORT可以看作是我们的基线方法,因为这两种方法都只采用卡尔曼滤波来预测物体运动。我们可以发现BYTE将SORT的MOTA度量从74.6提高到76.6,将IDF1从76.9提高到79.3,将ID转换从291降低到159。这突出了低分检测框的重要性,并证明了BYTE从低分中恢复对象框的能力。
DeepSORT利用额外的Re-ID模型来增强远程关联。我们惊奇地发现,与DeepSORT相比,BYTE还有额外的增益。这表明,在检测框足够精确的情况下,简单的卡尔曼滤波器可以进行远程关联,并获得较好的IDF1和ID转换。我们注意到,在严重遮挡的情况下,Re-ID特征是不稳定的,可能导致身份切换,相反,运动模型行为更可靠。
MOTDT将运动引导的框传播结果与检测结果集成在一起,将不可靠的检测结果与轨迹相关联。虽然共享相似性动机,MOTDT大大落后于BYTE。我们解释了MOTDT使用传播框作为轨迹盒,这可能导致在跟踪中定位漂移。相反,BYTE使用低分检测框重新关联那些不匹配的轨迹,因此,轨迹框更准确。
表2还显示了BDD100K数据集上的结果。BYTE的性能也大大优于其他关联方法。卡尔曼滤波在自动驾驶场景中失效是导致SORT、DeepSORT和modt性能低下的主要原因。因此,我们在BDD100K上不使用卡尔曼滤波。其他现成的ReID模型大大提高了BDD100K上BYTE的性能。
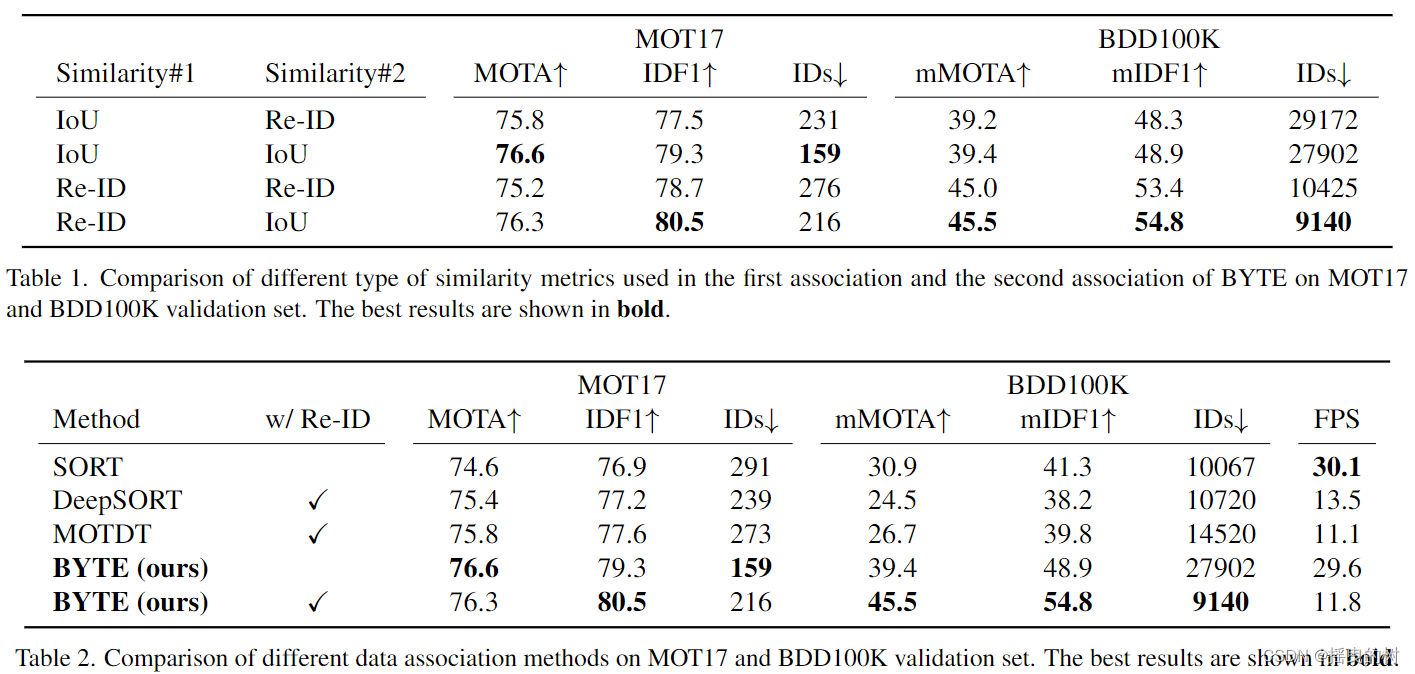
表1:比较在MOT17和BDD100K验证集上BYTE的第一次关联和第二次关联中使用的不同类型的相似度量。最好的结果以粗体显示。
表2:不同数据关联方法在MOT17和BDD100K验证集上的比较。最好的结果以粗体显示。

对检测评分阈值的鲁棒性。检测评分阈值 τ h i g h τ_{high} τhigh是一个敏感的超参数,在多目标跟踪任务中需要谨慎调整。我们将其从0.2改为0.8,并比较MOTA中的BYTE和SORT的IDF1评分。结果如图3所示。从结果可以看出,BYTE比SORT对检测评分阈值的鲁棒性更强。这是因为BYTE中的第二个关联恢复了得分低于 τ h i g h τ_{high} τhigh的对象,因此几乎考虑了所有的检测框,而不考虑 τ h i g h τ_{high} τhigh的变化。
低分检测框分析。为了证明BYTE的有效性,我们收集了BYTE获得的低分框中的TPs和FPs的数量。我们使用MOT17和CrowdHuman的半训练集进行训练,并在MOT17的半验证集上进行评估。首先,我们保留所有在 τ l o w τ h i g h τ_{low} ~ τ_{high} τlow τhigh范围内的低分检测盒,并使用地面真相注释对TPs和FPs进行分类。然后,我们从低分数检测框中选择BYTE获得的跟踪结果。每个序列的结果如图4所示。我们可以看到,BYTE获得的TPs明显多于FPs即使一些序列(如MOT17 -02)在所有的检测框中有更多的FPs,但评分较低的检测框。得到的FPs显著增加MOTA从74.6到76.6,如表2所示。
应用于其他跟踪器。我们将BYTE应用于9种不同的先进跟踪器,包括JDE [69], CSTrack [33], FairMOT [85], TraDes [71], QDTrack [47], CenterTrack [89], Chained-Tracker [48], TransTrack[59]和MOTR[80]。在这些跟踪器中,JDE、CSTrack、FairMOT、TraDes采用了运动相似度和ReID相似度的结合。QDTrack单独采用Re-ID相似度。CenterTrack和TraDes利用学习到的网络预测运动相似度。Chained-Tracker采用链式结构,同时输出两个连续帧的结果,并通过IoU将结果关联到同一帧。TransTrack和MOTR采用注意机制在帧之间传播框。它们的结果显示在表3中每个跟踪器的第一行中。为了评估BYTE的有效性,我们设计了两种不同的模式来将BYTE应用于这些跟踪器。
(1)第一种模式是在不同跟踪器的原始关联方法中插入BYTE,如表3中各跟踪器结果的第二行所示。以FairMOT[85]为例,在初始关联完成后,我们选择所有不匹配的轨迹,并将其与算法1中第二个关联之后的低分检测框进行关联。注意,对于低分对象,Re-ID特征不可靠,因此我们只采用运动预测后的检测盒和轨迹盒之间的IoU作为相似度。我们不将BYTE的第一模式应用于Chained-Tracker,因为我们发现它很难在链结构中实现。
(2)第二种方式是直接使用这些跟踪器的检测框,使用算法1中的整个过程进行关联,如表3中每个跟踪器结果的第三行所示。
我们可以看到,在这两种模式下,BYTE几乎可以在所有指标(包括MOTA、IDF1和IDs)上带来稳定的改进。例如,BYTE使CenterTrack增加1.3 MOTA和9.8 IDF1, Chained-Tracker增加1.9 MOTA和5.8 IDF1, TransTrack增加1.2 MOTA和4.1 IDF1。表3的结果表明,BYTE具有很强的泛化能力,可以很容易地应用到现有的跟踪器上,从而获得性能增益。
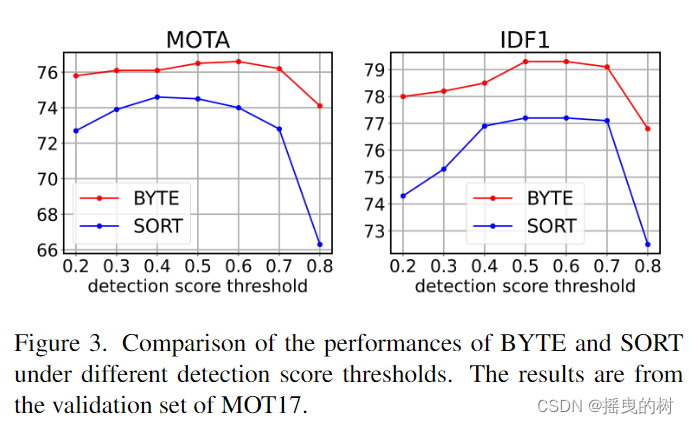
图3:不同检测评分阈值下BYTE和SORT的性能比较。结果来自于MOT17的验证集。
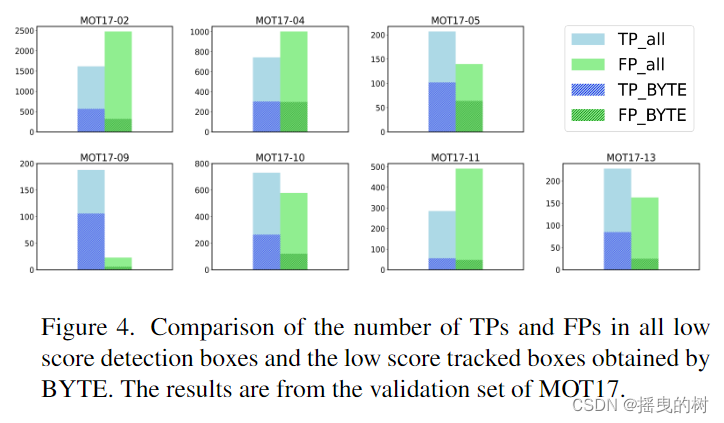
图4:比较所有低分检测框和BYTE获得的低分跟踪框中TPs和FPs的数量。结果来自于MOT17的验证集。
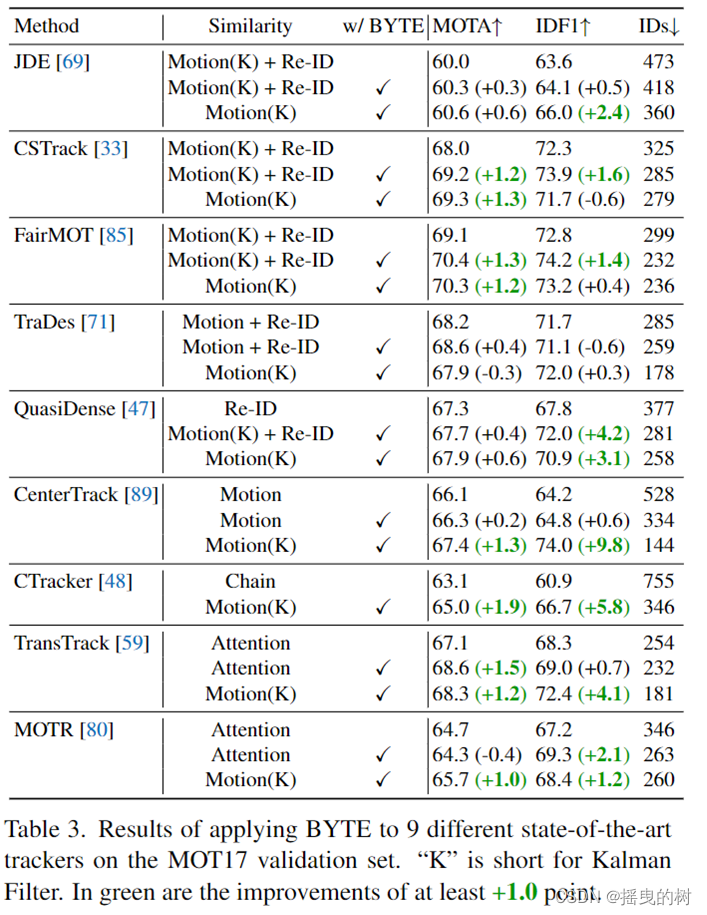
表3:将BYTE应用于MOT17验证集上9个不同的最先进跟踪器的结果。“K”是卡尔曼滤波的缩写。绿色的是至少+1.0点的改进。
4.3 基准评价

分别在表4、表5和表6所示的自定义检测协议下,我们比较了ByteTrack与MOT17、MOT20和HiEve测试集上最先进的跟踪器。所有的结果都直接从官方MOT挑战评估服务器和Human in Events服务器中获得。
MOT17数据集。ByteTrack在MOT17排行榜上的所有追踪器中排名第一。它不仅实现了最好的精度(即80.3 MOTA, 77.3 IDF1和63.1 HOTA),而且运行速度最高(30 FPS)。它的性能大大优于第二性能跟踪器[76](即+3.3 MOTA, +5.3 IDF1和+3.4 HOTA)。此外,我们使用的训练数据比许多高性能方法(如[33,34,54,65,85])使用的更少(29K图像vs73K图像)。值得注意的是,与其他方法[33,47,59,67,80,85]相比,我们只在关联步骤中使用了最简单的相似度计算方法卡尔曼滤波(Kalman filter),其他方法也采用了Re-ID相似度或注意机制。所有这些都表明ByteTrack是一个简单而强大的跟踪器。
MOT20数据集。与MOT17相比,MOT20的拥挤场景和遮挡情况要多得多。在MOT20的测试集中,图像中行人的平均数量为170。ByteTrack也在所有追踪器中排名第一在MOT20的排行榜上,它几乎在所有指标上都超过了其他追踪者。例如MOTA从68.6增加到77.8,IDF1从71.4增加到75.2,IDs从4209减少到1223,减少了71%。值得注意的是,ByteTrack实现了极低的ID标识转换,这进一步说明,在遮挡情况下,关联每个检测框是非常有效的。
Human in Events数据集。与MOT17和MOT20相比,HiEve包含了更复杂的事件和更多样化的镜头视角。我们在CrowdHuman数据集和HiEve训练集上训练ByteTrack。ByteTrack也在HiEve的所有追踪器排行榜上排名第一,并在很大程度上超越了其他最先进的追踪器。例如,MOTA从40.9增加到61.3,IDF1从45.1增加到62.9。结果表明,ByteTrack对复杂场景具有较强的鲁棒性。
BDD100K数据集。BDD100K是自动驾驶场景下的多类别跟踪数据集。挑战包括低帧率和大的相机运动。我们利用来自UniTrack[68]的简单ResNet-50 ImageNet分类模型提取Re-ID特征并计算外观相似性。ByteTrack在BDD100K排行榜上排名第一。它将验证集的mMOTA从36.6提高到45.5,将测试集的mMOTA从35.5提高到40.1,这表明ByteTrack也可以应对自动驾驶场景中的挑战。
5 结论

针对多目标跟踪,提出了一种简单有效的数据关联方法BYTE。BYTE可以很容易地应用于现有的跟踪器,并实现一致的改进。我们还提出了一个强大的跟踪器ByteTrack,在MOT17测试集上实现了80.3 MOTA, 77.3 IDF1和63.1 HOTA,帧数为30帧,在所有跟踪器排行榜上排名第一。ByteTrack对遮挡的鲁棒性很强,它具有准确的检测性能和关联低分检测框的帮助。同时也说明了如何更好地利用检测结果来增强多目标跟踪。我们希望ByteTrack的高精度、快速性和简洁性能使其在实际应用中具有吸引力。

A边界框标注:我们注意到MOT17[44]要求边界框[89]覆盖整体,即使对象被遮挡或部分脱离图像。但是,YOLOX的默认实现将检测框修剪在图像区域内。为了避免图像边界附近的错误检测结果,我们在数据预处理和标签分配方面对YOLOX进行了修改。在数据预处理和数据增强过程中,我们不裁剪图像内部的边界框。在数据增强后,我们只删除完全在图像外部的方框。在SimOTA标签分配策略中,正样本需要在物体的中心附近,而整个检测框的中心可能在图像之外,所以我们将物体的中心剪辑在图像内部。MOT20 [17], HiEve[37]和BDD100K将图像内部的边框注释修剪,因此我们只使用YOLOX的原始设置。
B.轻模型跟踪性能:我们使用轻量型检测模型比较BYTE和DeepSORT[70]。我们使用具有不同主干的YOLOX[24]作为我们的检测器。所有模型在CrowdHuman和MOT17的半训练集上进行训练。多尺度训练时,输入图像尺寸为1088 × 608,最短边长为384 ~ 832。结果如表8所示。我们可以看到,与DeepSORT相比,BYTE在MOTA和IDF1上带来了稳定的改进,这表明BYTE在检测性能上是稳健的。值得注意的是,当使用YOLOX-Nano作为骨干时,BYTE带来的MOTA比DeepSORT高3点,这使得它在实际应用中更具吸引力。
C. ByteTrack的消融研究:速度和准确性。在推理过程中,我们使用不同大小的输入图像来评估ByteTrack的速度和准确性。所有实验都使用相同的多尺度训练。结果如表9所示。推理时的输入大小为512 × 928 ~ 800 × 1440。检测器的运行时间介于17.9 ms ~ 30.0 ms,关联时间均在4.0 ms左右。ByteTrack可以实现75.0 MOTA和45.7 FPS运行速度,76.6 MOTA和29.6 FPS运行速度,在实际应用中具有优势。
训练数据。我们使用不同的训练数据组合在MOT17一半的验证集上评估ByteTrack。结果如表10所示。仅使用MOT17的一半训练集,性能达到75.8 MOTA,优于大多数方法。这是因为我们使用了Mosaic[8]和Mixup[81]等强增强功能。当进一步增加CrowdHuman, Cityperson and ETHZ数据集用于训练,MOTA和IDF1分别达到76.7和79.7。IDF1的最大改进在于,CrowdHuman数据集可以提高检测器对被遮挡者的识别能力,从而使卡尔曼滤波产生更平滑的预测,增强了跟踪器的关联能力。对训练数据的实验表明,ByteTrack并不需要大量的数据。对于实际应用来说,这是一个很大的优势,与之前的方法[33,34,65,85]相比,需要超过7个数据源[19,21,44,55,73,82,88]才能实现高性能。
D . 轨迹插值:我们注意到在MOT17中有一些完全遮挡的行人,在ground truth注释中可见比为0。由于几乎不可能通过视觉线索检测到它们,我们通过轨迹插值得到这些对象。
假设我们有一个轨迹T,它的小轨盒由于从帧 t 1 t_1 t1到帧 t 2 t_2 t2的遮挡而丢失。T在坐标系 t 1 t_1 t1处的轨迹盒为 B t 1 ∈ R 4 B_{t1}∈R^4 Bt1∈R4,其中包含边界盒的左上坐标和右下坐标。设 B t 2 B_{t2} Bt2表示T在帧t 2 _2 2处的轨迹小盒。我们设置了一个超参数σ,表示我们执行轨迹插值的最大时间间隔,这意味着当 t 2 − t 1 ≤ σ t_2−t_1≤σ t2−t1≤σ时执行轨迹插值。轨迹T在帧t处的插值框可计算如下: B t = B t 1 + ( B t 2 − B t 1 ) t − t 1 t 2 − t 1 B_t=B_{t1}+(B_{t2}-B_{t1})\frac{t-t_1}{t_2-t_1} Bt=Bt1+(Bt2−Bt1)t2−t1t−t1,其中 t 1 < t < t 2 t_1<t<t_2 t1<t<t2。
如表11所示,当σ为20时,轨迹小波插值可使MOTA从76.6提高到78.3,IDF1从79.3提高到80.2。轨迹小波插值是一种有效的后处理方法,可以获得完全遮挡物体的框。我们在私有检测协议下的MOT17 [44], MOT20[17]和HiEve[37]测试集中使用了轨迹插值。

E. MOT挑战赛的公开检测结果:我们在公共检测协议下对MOT17[44]和MOT20[17]测试集上的ByteTrack进行了评估。遵循Tracktor[3]和CenterTrack [89]中的公共检测过滤策略,只有当一个新轨迹的IoU与公共预测框大于0.8时,我们才初始化它。在公共检测协议下,我们不使用轨迹插值。如表12所示,ByteTrack在MOT17上的性能大大优于其他方法。例如,它在MOTA上的表现比SiamMOT高出1.5分,在IDF1上高出6.7分。表13显示了在MOT20上的结果。ByteTrack的性能也大大超过了现有的结果。例如,它在MOTA上比TMOH[57]高出6.9分,在IDF1上高出9.0分,在HOTA上高出7.5分,并且减少了四分之三的标识开关。在公共检测协议下的结果进一步证明了我们的关联方法BYTE的有效性。
F.可视化结果:我们在图5中展示了ByteTrack能够处理的一些困难情况的可视化结果。困难的情况包括遮挡(即MOT17 -02, MOT1704, MOT17 -05, MOT17 -09, MOT17 -13),运动模糊(即MOT17 -10, MOT17 -13)和小物体(即MOT17-13)。中间帧中红色三角形的行人检测得分较低,通过我们的关联方法BYTE获得。低分框不仅减少了漏检次数,而且对远程关联起着重要作用。从所有这些困难的情况中我们可以看到,ByteTrack没有带来任何身份切换,也没有有效地保存身份。
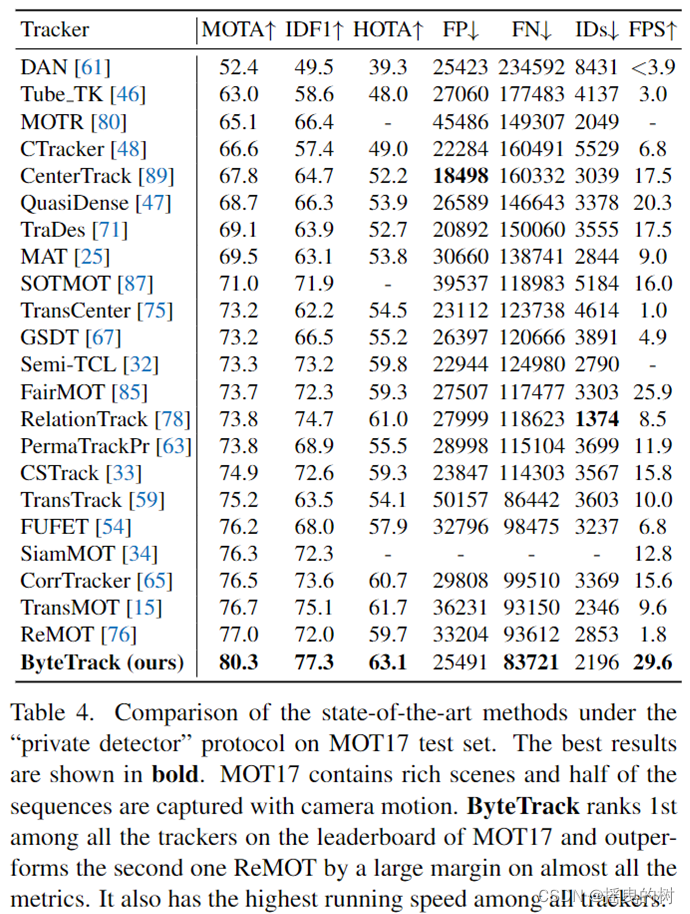
MOT17测试集“专用探测器”协议下最先进方法的比较。最好的结果以粗体显示。MOT17包含丰富的场景,一半的序列是通过相机运动捕捉到的。ByteTrack在MOT17的排行榜上排名第一,几乎在所有的指标上都远远超过第二名ReMOT。它的运行速度也是所有追踪器中最高的。
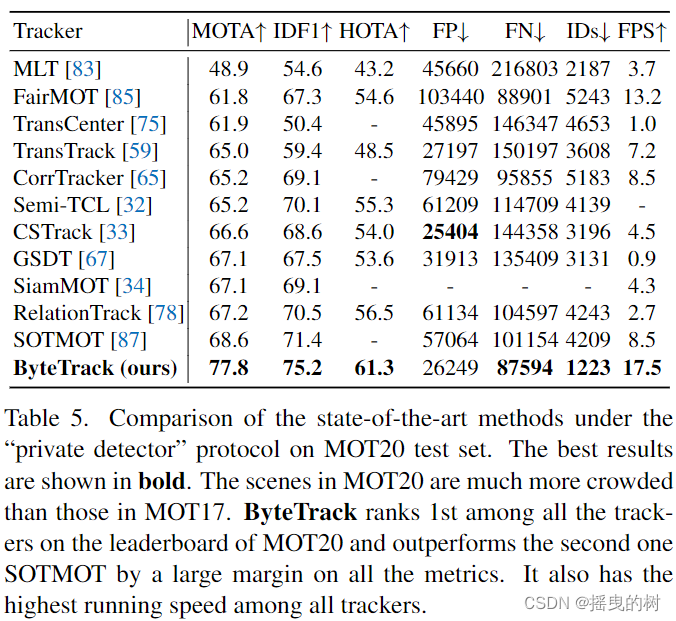
表5:MOT20测试集上“专用探测器”协议下最先进方法的比较。最好的结果以粗体显示。MOT20的场景比MOT17要拥挤得多。ByteTrack在MOT20排行榜上的所有追踪器中排名第一,在所有指标上都比排名第二的SOTMOT有很大的优势。它的跑步速度也是所有追踪器中最高的。
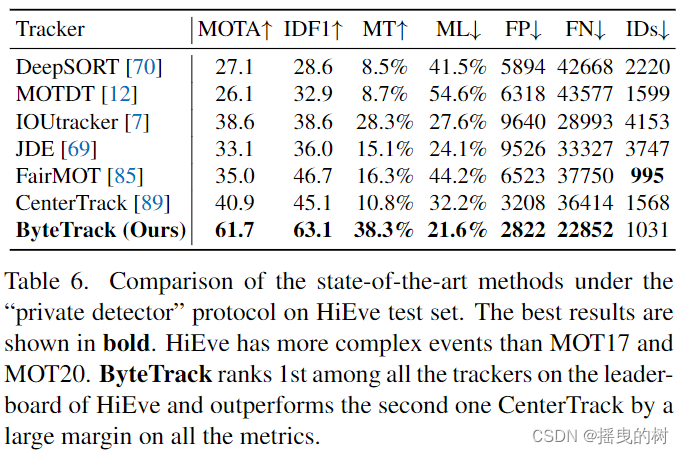
表6:在HiEve测试集上“私有检测器”协议下的最先进方法的比较。最好的结果以粗体显示。HiEve有比MOT17和MOT20更复杂的情况。ByteTrack在HiEve的排行榜上排名第一,在所有指标上都比第二名CenterTrack有很大的优势。
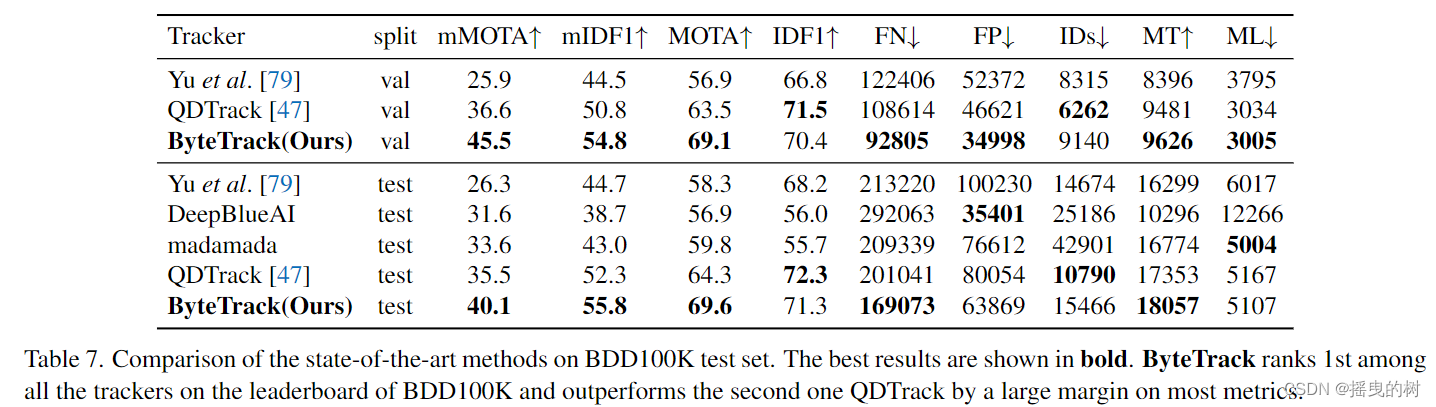
表7:BDD100K测试集上先进方法的比较。最好的结果以粗体显示。ByteTrack在BDD100K的排行榜上排名第一,在大多数指标上都远远超过第二名QDTrack。
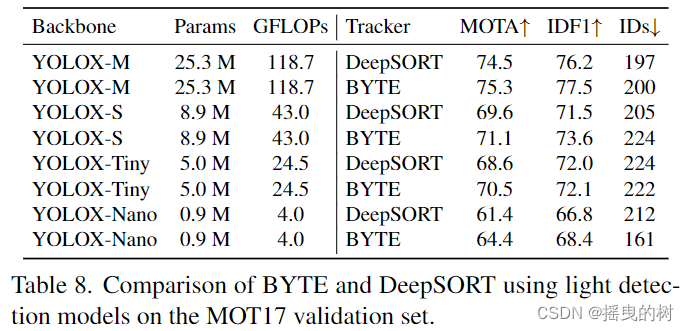
表8:在MOT17验证集上使用光检测模型比较BYTE和DeepSORT。
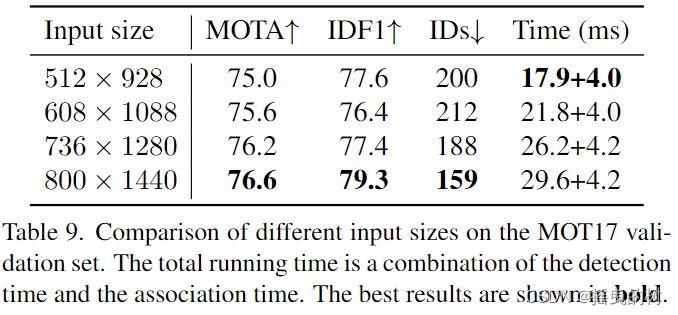
表9:不同输入尺寸在MOT17验证集上的比较。总运行时间是检测时间和关联时间的组合。最好的结果以粗体显示。
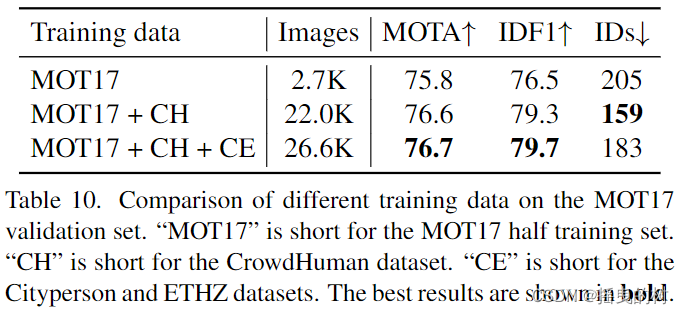
表10:不同训练数据在MOT17验证集上的比较。“MOT17”是MOT17半训练集的简称。“CH”是CrowdHuman数据集的缩写。“CE”是Cityperson和ETHZ数据集的缩写。最好的结果以粗体显示。
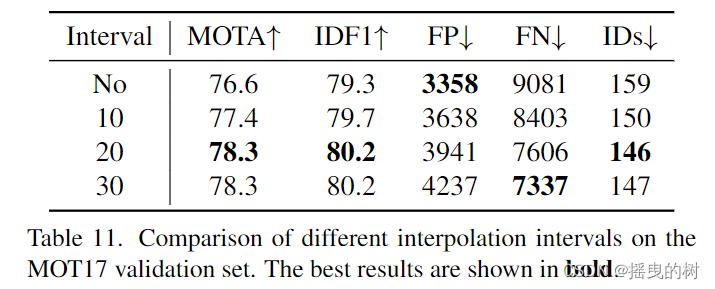
表11:不同插补间隔在MOT17验证集上的比较。最好的结果以粗体显示。
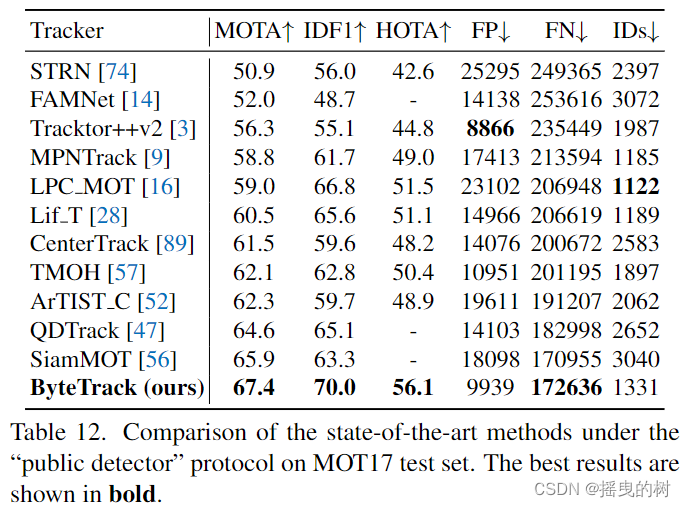
表12:MOT17测试装置上“公共探测器”协议下的最先进方法的比较。最好的结果以粗体显示。
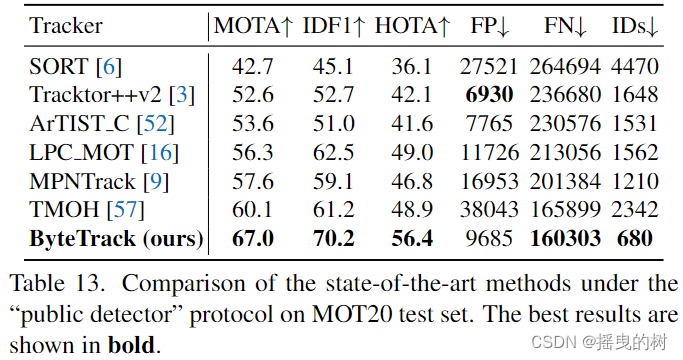
表13:MOT20测试装置上“公共探测器”协议下的最先进方法的比较。最好的结果以粗体显示。

图5:ByteTrack可视化结果。我们从MOT17的验证集中选择了6个序列,展示了ByteTrack处理遮挡和运动模糊等困难情况的有效性。黄色三角形代表高分框,红色三角形代表低分框。相同的盒子颜色代表相同的身份。