论文链接:https://arxiv.org/abs/1506.01497
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
发布时间:
年
月发布,
年
月月最后修改
摘要
之前最先进的目标检测模型如Fast RCNN和SPPnet都受限于候选区域的计算,导致不能实现实时检测。在本论文中,作者引入了Region Proposal Network(RPN)模块,通过分享整张图片的卷积特征,从而基本不耗时间地提取候选区域。
RPN 网络是一个全卷积网络(FCN),其能够在每个位置同时预测对象边框以及给对象打分。训练RPN产生网络端对端的候选区域,用以提供给Fast RCNN检测。作者通过共享RPN模块和Fast RCNN模块的卷积特征来把它们结合成一个网络,就像最近很流行的神经网络术语“注意力机制”所说的那样,这个RPN模块将会告诉我们要“看”哪儿。
通过RPN,每张图片只需要 提供300个候选区域【对比Fast RCNN的每张图片2000张候选区域】。
引言
其他方法
区域候选(Region Proposal)方法通常是依赖于低级和浅层的特征的推理方案。
选择性搜索(Selective Search)方法是工程化低级特征的贪婪算法(超像素级,也就是像素的集合),其是基于CPU运算的,每张图片大概需要
时间。边缘箱(Edge boxes)是2014年(Locating object proposals from Edges)提出的方法,是候选区域质量和速度的折中,每张图片大概需要
时间。然而,这花费的时间也和网络检测的时间一样。
本文
RPNs是从数据中学习候选区域的,所以该网络模型可以提取深层的、“昂贵”的特征。
本论文提出了一种使用GPU运算的,基本不花费时间于候选区域的检测网络(大概每张图片 ):用一个深层卷积网络计算候选区域。也就是后面会提到的RPN网络,其与最先进的检测网络(Fast RCNN)共享卷积层。作者认为,基于区域的探测器(region-based detectors)【该探测器应该就是一般的卷积神经网络锁需要的卷积核】也可以用于生成候选区域【提取共性特征的卷积层得到的feather maps也可以用于RPN中】。在卷积特征之前添加一些额外的卷积层用于构建RPN,这些卷积层会同时在一些常规网格中进行边框回归和分类。
RPN用于预测候选区域,因此作者引入了一种anchor boxes的定义,该定义大概就是RPN预测出来的不同尺度和长宽比的区域边框。该方法的提出,可以避免使用不同尺度和长宽比的过滤器或枚举图片。
Faster RCNN
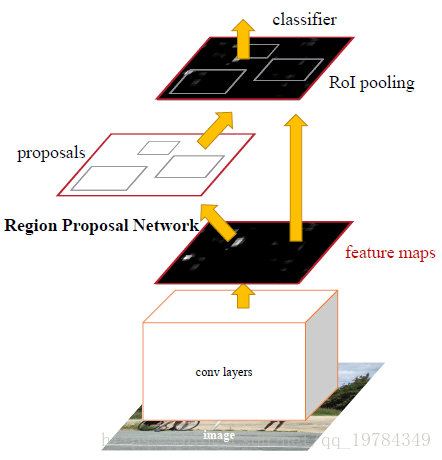
Faster RCNN结构图
Faster RCNN的结构如上图所示,其可以分成两个模块,四个层次:
两个模块:
- RPN模块:用于生成“预测区域”,同时对预测区域进行分类及粗略的边框回归【利用分类的分数(文中的结构图的分类结果为两类,即不关心类别,只区分前景和背景,目的是将前景区域用于回归和后续的Fast RCNN模块中)执行非最大值抑制(文中的IoU阈值为0.7)后,进行边框回归】,选择其中分数Top300的区域输出到后面
- Fast RCNN模块:用于将得到的区域分类和精确的边框回归【RoI池化层及之后的分类、回归层就和Fast一样了】;
四个层次:
- Conv layers:使用conv+relu+pooling的基础层提取任意大小图片的通用特征
- RPN:通过softmax判断anchor boxes属于前景还是背景,再利用bounding-box regression修正anchors为精确的proposals。【那么问题来了,为什么不可以把这个当做精确的结果?是因为之前别人做过的结果不太行?【反卷积可视化那篇】】
- RoI pooling:该层综合proposals和feature maps的信息,送入后续的全连接层,目的是处理不同大小的proposals feather maps。
- Classification:利用proposals feather maps对proposal进行分类,并再次使用bounding-box 回归计算精确的边框
可以看出,Faster RCNN和Fast RCNN的区别仅在于提取候选区域的方式不同而已。
Region Proposal Network
RPN是一个全卷积神经网络,所以可以接收任何大小的输入,其输出是一系列矩形的区域建议,并且每一个区域都有一个对象分数。
需要注意的是,RPN的输入是和Fast RCNN共享的卷积层,文中用了两种网络(ZF,VGG-16)作为Fast RCNN的基础,在经过通用的卷积层提取特征后,这两种网络的feature maps的channel的维度分别为 ,feature maps的每一个“网格点”的感受野大小分别为 。
如下图所示,RPN先用
的卷积核处理输入的层,以提取区域建议的信息;再分别用
【文中的k设置为9】和
的卷积核计算每个“网格点”的anchor分类和anchor回归。【每个“网格点”都有不小的感受野,换句话说就是拥有原图一定大小的信息,不同channels的网格点是不同特征信息,但对应的是同一个区域。这个
的卷积核用于区分前背景,只是前序步骤,后面还有计算概率的步骤;回归步骤是计算anchor(实现定义的不同大小的,但中心点一样的方框)的回归;计算分类和回归是为了提取不同大小的proposals】【至于如何从概率和回归提取proposals,而且不经过映射计算的(文中说用GPU提取的),我也不太清楚,后面撸源码回来解决】
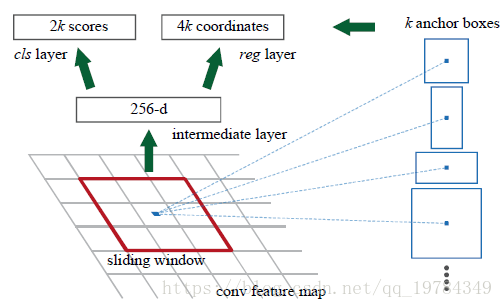
RPN流程图
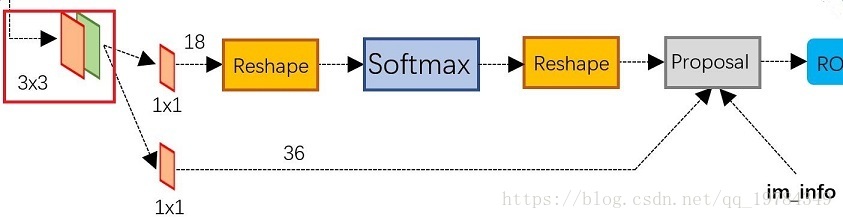
RPN结构图
RPN的具体结构图如上图所示,其分类两条路径:⑴ 分类;⑵ 回归。
假设使用的是ZF网络,其第五层卷积层(最后一层)的输出为 ,则输入 RPN中经过 的卷积核【 这个 】,输出为 。分类层,经过18个 卷积核,输出为 。经过 操作是因为,我们需要将输出变为 的形式,我们要对9( k)个 anchor进行前背景分类【 因为作者是用caffe写的,caffe保存数据的形式是[batch_size, channel, height, width],即他需要变换的形式为[1,2,9*H,W]】。这2个channe分出来就是用于分类的,经过softmax层之后,再恢复原来形状( [1,18,H,W])。至于回归层就通过36个 的卷积核,得到 个 anchor的回归信息。之后在整合分类和回归信息,整理出合适个数的 进入RoI层。
Anchors
卷积核遍历的每个位置都是同时预测了多个区域提议,这个区域提议的最大个数设置为 。因此回归层有与 个边框相对应的 个输出,分类层有预测前景和背景的 个输出,这k个推测边框我们叫做anchors。anchor在每个滑动区域的中心,每个anchor的尺寸和长宽比都不同。(文中默认 个尺寸, 个长宽比,因此每个位置有 个anchor)。对于尺寸为 的feature maps(一般约 ),有 个anchor。
Loss Function
对于每一个anchor,RPN都给他标记( 正类是有对象,负类是没有对象)。这里设定两种类为正类:⑴ 与其中一个ground-truth box有最高IoU的anchor(s)。⑵ 和任意ground-truth box有高于0.7IoU的anchor(s)【 一般来说第二点就够了,但为了防止有的区域在第二点面前不能标记为正类,比如所有anchor和ground-truth都小于 】。作者将和所有ground-truth boxes都IoU低于0.3的样本标记为负样本,只有正、负样本才对训练起作用。【 就是使用硬负样本,大概意思就是使用质量更好的样本】
至于代价函数,其定义与Fast RCNN的多任务损失函数基本一样,只不过多尝试了些系数以正规化比例,但影响并不大( 就是基本不需要,可以简化成Fast RCNN的公式)。
在SPPnet和Fast RCNN中的边框回归都是用于任意尺寸的proposal上的,而回归的权重对于所有尺寸都是共享的【 不同尺寸的proposal通过RoI池化层后有相同大小的特征向量】,只是对不同分类进行单独的边框回归。而在RPN中的边框回归是作用于相同尺寸的区域( 有 种固定的,实现设计好尺寸和长宽比的anchor作用于原图,即有 种固定大小的区域(anchor随着卷积层操作后的映射)作用于特征图),因此对于每一种尺寸和长宽比的边框都进行一种边框回归。这 种回归并不共享参数,因而实现固定好大小和比例的anchor也能预测不同大小的proposal【经过RPN网络的边框回归能产生不同大小和比例的proposal,然后输入RoI层,进入正常的Fast RCNN操作】。
训练RPNs
RPN可以使用SGD优化算法反向传播端对端训练。每个mini-batch提取的区域都来自同一张图片,其中有很多anchor样本。训练的时候当然可以使用全部anchor样本,但这样会导致模型偏向负样本,因为负样本占绝大数。所以提取样本的策略为从一张图片随机选取256个样本,其中正负样本个数都为128。(如果正样本数不足128,则用负样本补充)
在RPN的“新层”中的初始化使用 均值 、 标准差的高斯分布中抽取参数;在其他层(就是原本Fast RCNN的那些层,比如和RPN共享的卷积层即之后的全连接层)使用ImageNet分类的预训练模型(如ZFnet和VGGnet)。前 的 的模型学习率为 ,接下来的 的 的模型学习率为 【训练的数据集为PASCAL VOC】。模型的优化算法为动量梯度下降,其动量为 ,权重衰减为 。
RPN和Fast RCNN的共享特征
我们的模型是将RPN和Fast RCNN结合起来形成的统一模型,所以我们需要一个学习算法来学习这个统一的网络。我们有三种学习统一模型共享特征的方式:
- 交替训练:先训练RPN,然后将生成的proposals保存下来用于训练Fast RCNN,将Fast RCNN训练的卷积层用于初始化RPN。然后再训练RPN,如此交替。【一开始的共享卷积层是用同一个模型预训练的】【本文的实验训练方法就是使用的这个方法】
- 近似联合训练:这里是直接运行整个统一模型,但将RPN生成的proposals作为一个固定的输入作为后续RoI层的输入,用RPN和Fast RCNN各自的损失函数组合成多任务损失函数。【这种问题存在的一个问题是:无法对proposals的边框(bbox)反向传播(因为固定作为输入了,也就是RoI的误差无法反向传播进RPN网络中),因此只能称为近似联合训练】
非近似联合训练:即联合训练,和上面的近似联合训练不同的是,该方法不将proposal作为固定的输入,而是将其作为原始输入的函数,使得RoI的误差可以通过proposal的bbox信息完成反向传播。【该方法可以在论文(Instance-aware semantic segmentation via multi-task network cascades)中学习】
最终,网络的训练方法可以被称为 步训练方法(使用交替方法来学习共享特征)。学习RPN,作为学习区域提取任务的端对端模型训练。训练完后,提取proposal并存储起来(该网络像之前说的那样用ImageNet预训练网络初始化)
- 学习Fast RCNN,使用步骤 生产的proposals来单独训练Fast RCNN(这时的两个网络并没有共享卷积层,Fast RCNN也是预训练网络初始化的。)【这个proposal输入是放在RoI前的,也就是代替了统一模型中RPN网络的位置(前面展示的检测时的统一模型),也就是说原始数据仍要输入,仍要经历卷积层】【文中明确说明这个地方是不共享卷积层的,也就是最后统一模型的共享卷积层会稍微偏向Fast CNN,因为后面就固定住共享卷积层,只更新各自独特的层】
- 学习RPN,这是的网络的“共享卷积层”的参数使用步骤 学习到的参数,即模型在这里开始共享卷积层,然后单独训练学习RPN独特的层。(也就是说,从这里开始,模型是统一的,共享卷积层的学习率为 )
- 学习Fast RCNN,将步骤 生成的proposals输入到Fast RCNN中,训练其单独的层。
之所以说四步训练,是因为文中表示该模型只需要迭代这么四步(两次分别训练),再往后的迭代带来的改进基本可以忽略了。
训练细节
输入预处理,将输入统一缩放成 大小。(多尺度特征提取可能可以提到准确率,但不能很好地折中速度和准确率)。文中使用的模型(ZFnet,VGGnet)的共享卷积之后,感受野(也就是stride的乘积)为 ,也就是说对于 的图像在经过卷积层后,其每个像素点代表之前 个像素点的信息,这对于PASCAL VOC的图像(一般约 大小)对应的就是原图像的 个像素点( )。【步幅乘积这么大都能提供好的结果,使用更小的步幅可能能得到更好的结果,但不是本文要讨论的内容】
anchors选择,选定anchors为三个尺度 和三个长宽比 的卷积,共九个。(这些anchors没有特意为了某数据集精心设计,按照结果来说,应该是没有必要调整,其三个边框的大小基本可以覆盖了整张图片)。
anchors筛选,⑴ 在训练时,作者把所有越过“边界”的anchors都忽略了(对于 的图片,其大概有 个anchors 。删去越过边界的,大概还剩下 个。)。若不删掉这些过界的anchors,那么RPN将会推荐较大的,相对比较错误的区域,同时训练也不会收敛。⑵ 在测试时,作者却留下这些过界的anchors,在整张图片上卷积,只需要将其产生的越过边界的proposals裁剪成符合图片边界的区域。
proposals筛选,经过RPN提取的proposals有很高的重叠率,对其进行非最大值抑制以删除重叠率较高的框。本文设置NMS的IoU为
。经过非最大值抑制后,每张图片大概能剩下2000个区域。然后选取Top-N的区域用于检测。在训练的时候,选取
个区域;但在测试时,区域选取的数目又不同。
细节问题
为什么不直接使用RPN输出的bbox呢?
RPN的回归是对anchors提取的proposals的回归,是作用于固定尺度,且anchor之间相对变化较小的。而后面Fast RCNN的回归则是对对象的回归。这两个回归的分工不同,所以RPN回归的输出是anchor的个数,Fast RCNN回归的输出是class的个数。
anchors是在feature maps上还是在data_input上?
在RPN分类和回归层之前的卷积层,其上每一点都是
卷积核中心点的直接对应,而
卷积核中心点对应输入图像(经过re-scale后的图片,
)上的位置(点)就是我们所说的anchors的中心点。【所以在判断类别的时候,会需要输入一个im_info信息,提供的是步长的积,这里是
】