分类:动作捕捉
github地址:https://github.com/MVIG-SJTU/AlphaPose
所需环境:Ubuntu18.04LTS,conda 22.9.0

环境配置
截止到2022年7月,Alphapose已经更新到0.6.0版本,也正是本次安装的版本。由于本机之前配置过CUDA环境3,这里就不多说了。
-
至于为什么没有在Windows平台上配置,是因为vs的编译器版本比较低难以构建halpecocotools(AlphaPose团队改造的pycocotools包)。 总是提示:c1: fatal error C1083: 无法打开源文件: “…/common/maskApi.c”: No such file or directory。尽管已经查了好多帖子,无论是离线安装还是升级vs,都没有成功。这个问题困扰了一天,最终还是选择了Ubuntu系统。
-
虽然之前已经写过在Ubuntu里安装成功AlphaPose5,但是由于是 在nvidia-docker里配置的,显存不够,无法推理视频。而在真机里安装刚好可以弥补这一点。但是遇到高分辨率或者高帧率的视频,还是会在推理一会后卡住。另一方面由于代码发生了变化,之前写的配置方法5现在已经无法复刻搭建成功环境了。
安装的过程及其简单4,但是按照官网给出的docs/install.md安装就会遇到各种问题。所以太感谢作者4了。
只需要依次执行以下conda命令即可:
# AlphaPose安装语句 适用于Ubuntu及2023年8月8日之前未改动的版本
# 创建py3.7环境
conda create -n alphapose python=3.7 -y
conda activate alphapose
# 安装pytorch全家桶
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
# 下载源码(可在其他终端进行)
git clone https://github.com/MVIG-SJTU/AlphaPose.git
cd AlphaPose
# 配置环境变量
export PATH=/usr/local/cuda/bin/:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:$LD_LIBRARY_PATH
# 安装依赖
pip install cython==0.27.3
pip install ninja
pip install easydict halpecocotools munkres natsort opencv-python pyyaml scipy tensorboardx terminaltables timm==0.1.20 tqdm visdom jinja2 typeguard
# 安装linux的yaml库
sudo apt-get install libyaml-dev
# 安装pycocotools
pip install pycocotools
# 构建AlphaPose
python setup.py build develop
# 安装pytorch3D(可选项)
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
conda install -c bottler nvidiacub
pip install pytorch3d
conda list
# packages in environment at /home/xxx/anaconda3/envs/alphapose:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
alphapose 0.5.0+c60106d dev_0 <develop>
blas 1.0 mkl
brotlipy 0.7.0 py37h27cfd23_1003
bzip2 1.0.8 h7b6447c_0
ca-certificates 2023.7.22 hbcca054_0 conda-forge
certifi 2023.7.22 pyhd8ed1ab_0 conda-forge
cffi 1.15.1 py37h5eee18b_3
charset-normalizer 2.0.4 pyhd3eb1b0_0
colorama 0.4.6 pyhd8ed1ab_0 conda-forge
cryptography 39.0.1 py37h9ce1e76_0
cudatoolkit 11.3.1 h2bc3f7f_2
cycler 0.11.0 pypi_0 pypi
cython 0.27.3 pypi_0 pypi
cython-bbox 0.1.3 pypi_0 pypi
easydict 1.10 pypi_0 pypi
ffmpeg 4.3 hf484d3e_0 pytorch
fonttools 4.38.0 pypi_0 pypi
freetype 2.12.1 h4a9f257_0
fvcore 0.1.5.post20210915 py37 fvcore
giflib 5.2.1 h5eee18b_3
gmp 6.2.1 h295c915_3
gnutls 3.6.15 he1e5248_0
halpecocotools 0.0.0 pypi_0 pypi
idna 3.4 py37h06a4308_0
importlib-metadata 6.7.0 pypi_0 pypi
intel-openmp 2021.4.0 h06a4308_3561
iopath 0.1.9 py37 iopath
jinja2 3.1.2 pypi_0 pypi
jpeg 9e h5eee18b_1
jsonpatch 1.33 pypi_0 pypi
jsonpointer 2.4 pypi_0 pypi
kiwisolver 1.4.4 pypi_0 pypi
lame 3.100 h7b6447c_0
lcms2 2.12 h3be6417_0
ld_impl_linux-64 2.38 h1181459_1
lerc 3.0 h295c915_0
libdeflate 1.17 h5eee18b_0
libffi 3.4.4 h6a678d5_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libiconv 1.16 h7f8727e_2
libidn2 2.3.4 h5eee18b_0
libpng 1.6.39 h5eee18b_0
libstdcxx-ng 11.2.0 h1234567_1
libtasn1 4.19.0 h5eee18b_0
libtiff 4.5.0 h6a678d5_2
libunistring 0.9.10 h27cfd23_0
libwebp 1.2.4 h11a3e52_1
libwebp-base 1.2.4 h5eee18b_1
lz4-c 1.9.4 h6a678d5_0
markupsafe 2.1.3 pypi_0 pypi
matplotlib 3.5.3 pypi_0 pypi
mkl 2021.4.0 h06a4308_640
mkl-service 2.4.0 py37h7f8727e_0
mkl_fft 1.3.1 py37hd3c417c_0
mkl_random 1.2.2 py37h51133e4_0
munkres 1.1.4 pypi_0 pypi
natsort 8.4.0 pypi_0 pypi
ncurses 6.4 h6a678d5_0
nettle 3.7.3 hbbd107a_1
networkx 2.6.3 pypi_0 pypi
ninja 1.11.1 pypi_0 pypi
numpy 1.21.5 py37h6c91a56_3
numpy-base 1.21.5 py37ha15fc14_3
nvidiacub 1.10.0 0 bottler
opencv-python 4.8.0.74 pypi_0 pypi
openh264 2.1.1 h4ff587b_0
openssl 1.1.1v h7f8727e_0
packaging 23.1 pypi_0 pypi
pillow 9.4.0 py37h6a678d5_0
pip 22.3.1 py37h06a4308_0
portalocker 1.4.0 py_0 conda-forge
protobuf 4.23.4 pypi_0 pypi
pycocotools 2.0.6 pypi_0 pypi
pycparser 2.21 pyhd3eb1b0_0
pyopenssl 23.0.0 py37h06a4308_0
pyparsing 3.1.1 pypi_0 pypi
pysocks 1.7.1 py37_1
python 3.7.16 h7a1cb2a_0
python-dateutil 2.8.2 pypi_0 pypi
python_abi 3.7 2_cp37m conda-forge
pytorch 1.12.1 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
pytorch-mutex 1.0 cuda pytorch
pytorch3d 0.3.0 pypi_0 pypi
pyyaml 6.0.1 pypi_0 pypi
readline 8.2 h5eee18b_0
requests 2.28.1 py37h06a4308_0
scipy 1.7.3 pypi_0 pypi
setuptools 65.6.3 py37h06a4308_0
six 1.16.0 pyhd3eb1b0_1
sqlite 3.41.2 h5eee18b_0
tabulate 0.9.0 pyhd8ed1ab_1 conda-forge
tensorboardx 2.6.2 pypi_0 pypi
termcolor 2.3.0 pyhd8ed1ab_0 conda-forge
terminaltables 3.1.10 pypi_0 pypi
timm 0.1.20 pypi_0 pypi
tk 8.6.12 h1ccaba5_0
torchaudio 0.12.1 py37_cu113 pytorch
torchvision 0.13.1 py37_cu113 pytorch
tornado 6.2 pypi_0 pypi
tqdm 4.65.0 pyhd8ed1ab_1 conda-forge
typeguard 4.1.0 pypi_0 pypi
typing-extensions 4.7.1 pypi_0 pypi
urllib3 1.26.14 py37h06a4308_0
visdom 0.2.4 pypi_0 pypi
websocket-client 1.6.1 pypi_0 pypi
wheel 0.38.4 py37h06a4308_0
xz 5.4.2 h5eee18b_0
yacs 0.1.8 pyhd8ed1ab_0 conda-forge
yaml 0.2.5 h7f98852_2 conda-forge
zipp 3.15.0 pypi_0 pypi
zlib 1.2.13 h5eee18b_0
zstd 1.5.5 hc292b87_0
演示
演示结果与之前的演示方法5一致,不过这次视频也可以推理了。
目标检测模型配置
1.下载yolov3-spp.weights和 yolox-l。分别拷贝到detector/yolo/data和detector/yolox/data(需要自己创建一个data文件夹)
原始数据



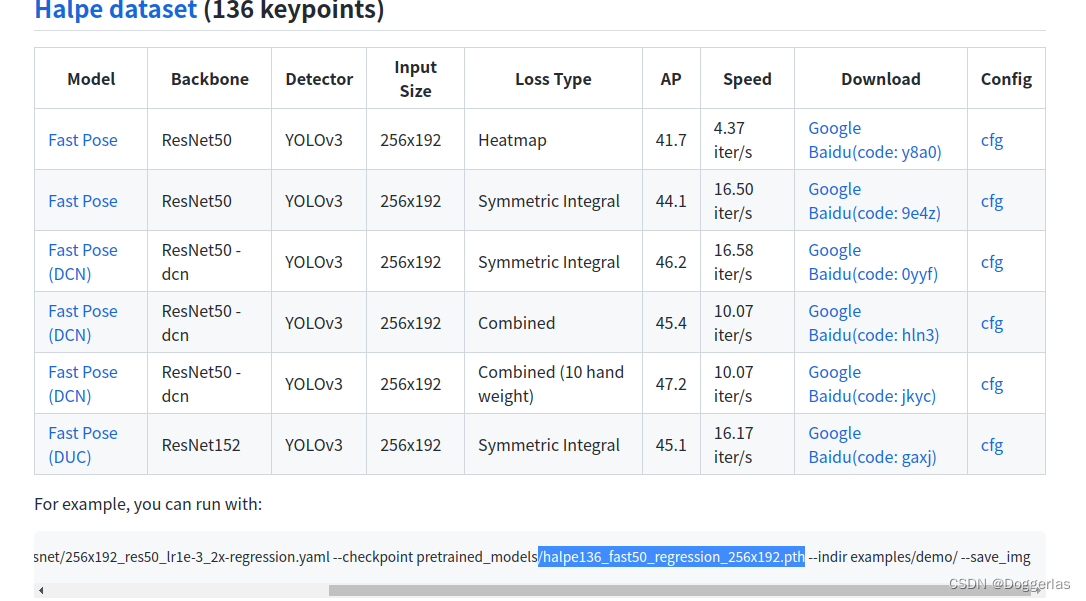
2.下载这个模型halpe26_fast_res50_256x192.pth并放到/pretrained_models下(2 3 4的模型都放到/pretrained_models下)

启动测试脚本
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --indir examples/demo/ --save_img
想用yolox-l做检测器,请在上述指令加上此参数:--detector yolox-x
直接跑通
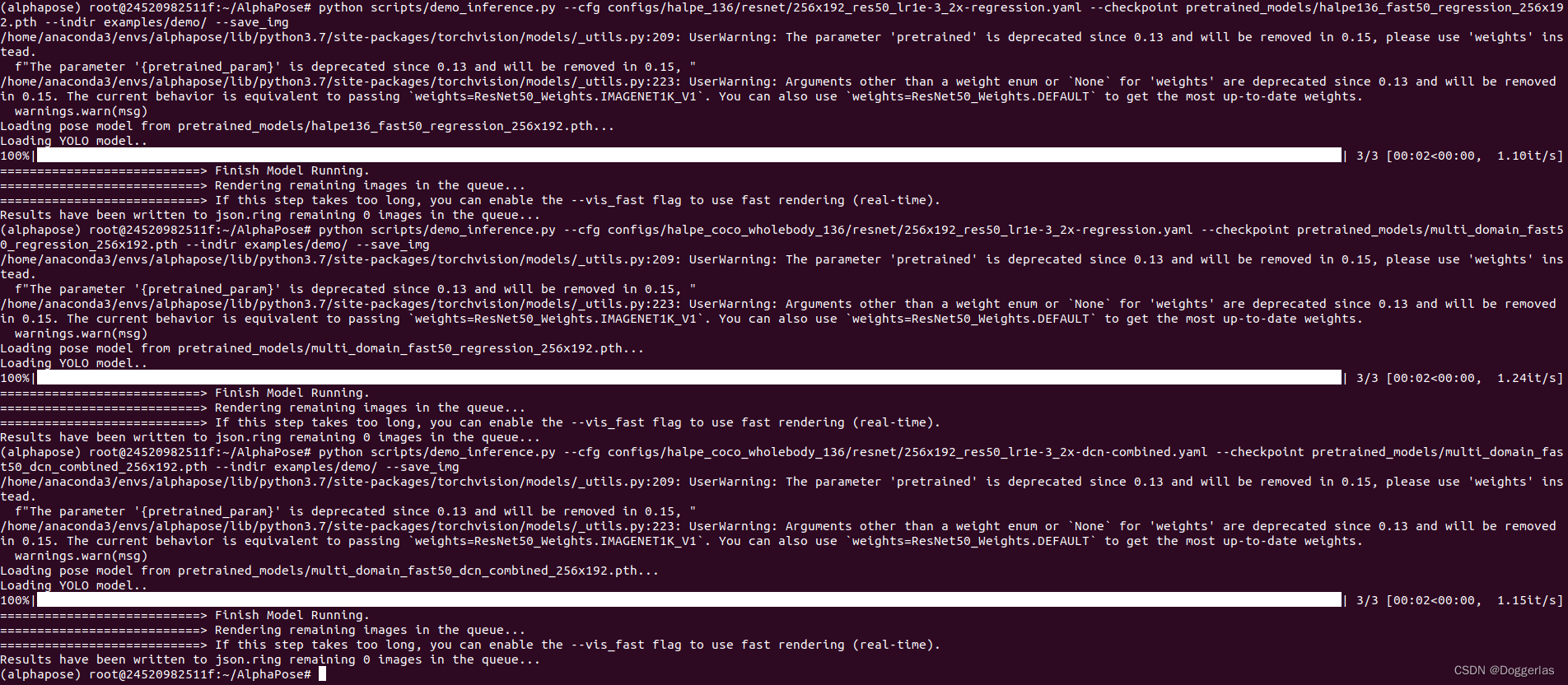
进入/examples/res/vis /查看结果:


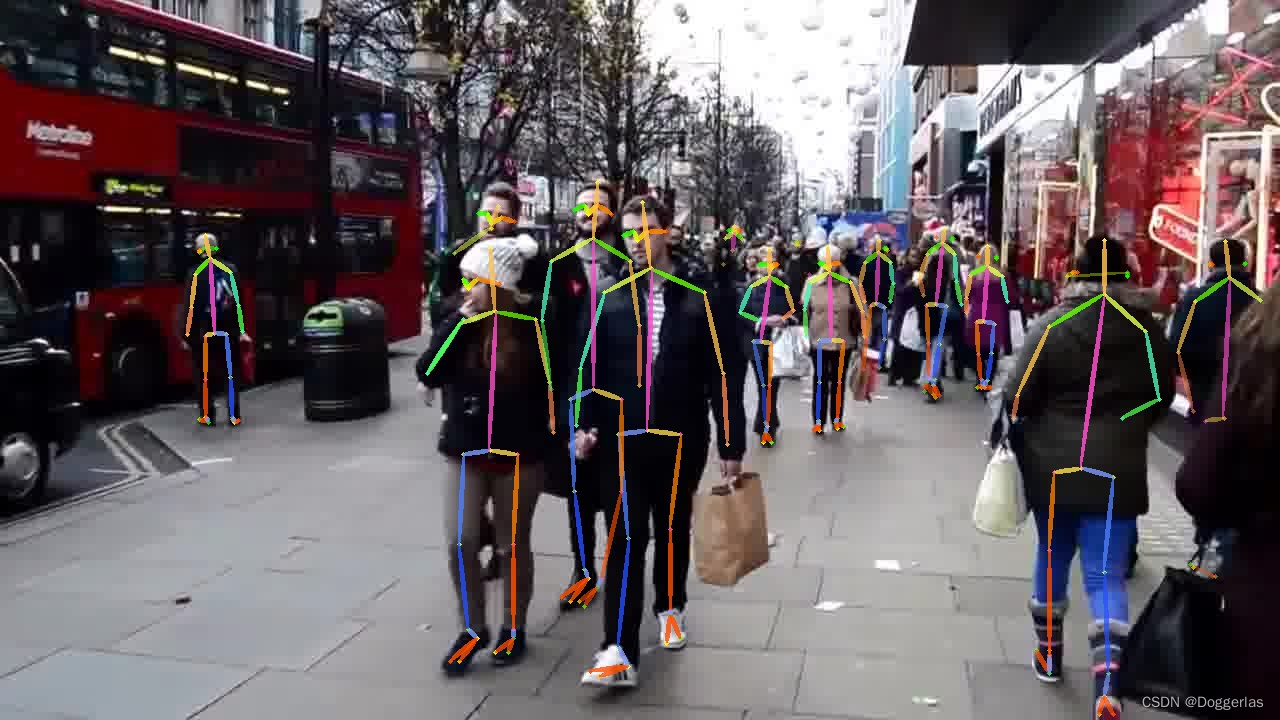
3.下载第二个模型halpe136_fast50_regression_256x192.pth并放到/pretrained_models下
启动测试脚本
python scripts/demo_inference.py --cfg configs/halpe_136/resnet/256x192_res50_lr1e-3_2x-regression.yaml --checkpoint pretrained_models/halpe136_fast50_regression_256x192.pth --indir examples/demo/ --save_img
查看结果


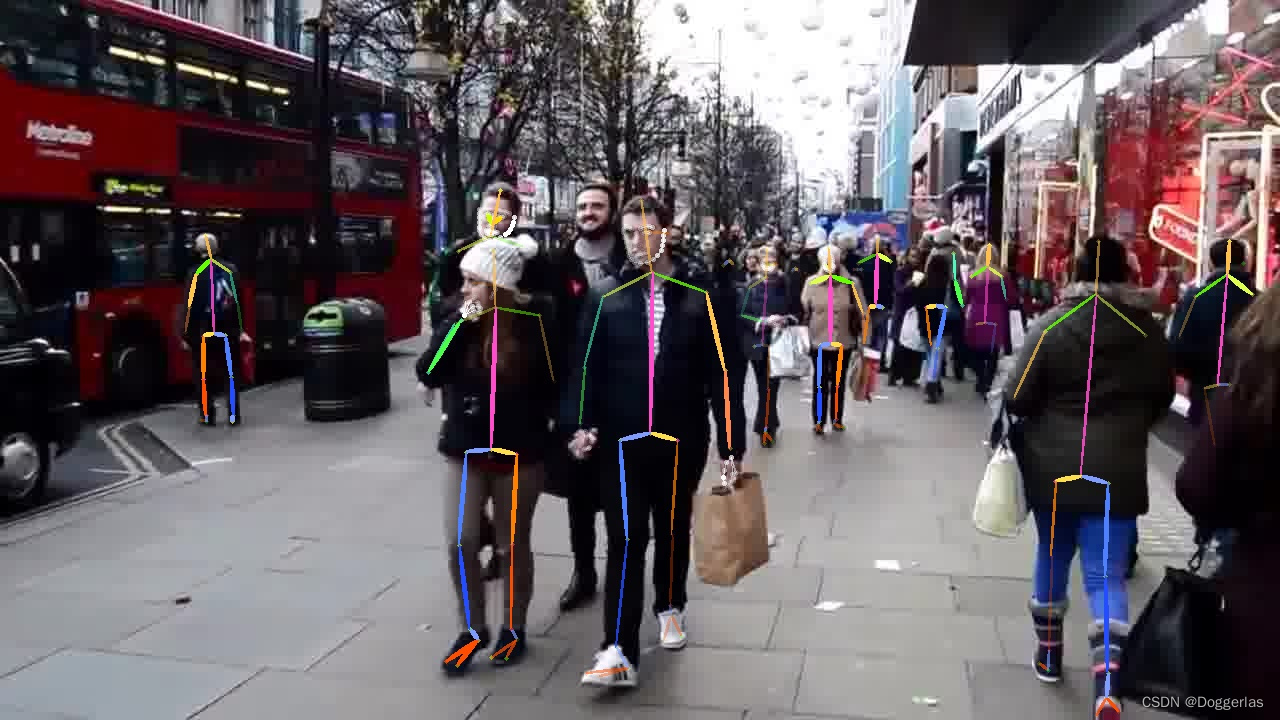
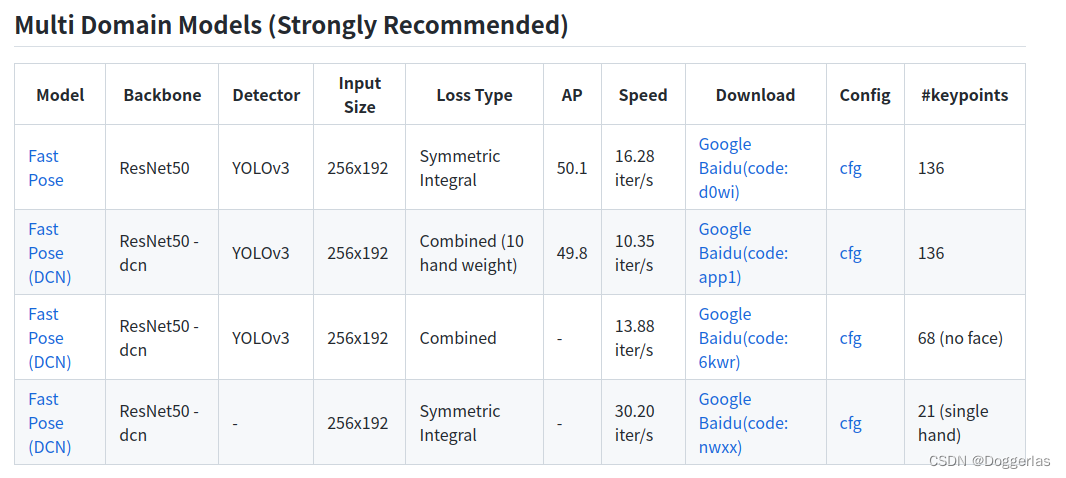
4.下载前两个multi_domain_fast50_dcn_combined_256x192.pt和 multi_domain_fast50_regression_256x192.pth
执行测试脚本
python scripts/demo_inference.py --cfg configs/halpe_coco_wholebody_136/resnet/256x192_res50_lr1e-3_2x-regression.yaml --checkpoint pretrained_models/multi_domain_fast50_regression_256x192.pth --indir examples/demo/ --save_img
python scripts/demo_inference.py --cfg configs/halpe_coco_wholebody_136/resnet/256x192_res50_lr1e-3_2x-dcn-combined.yaml --checkpoint pretrained_models/multi_domain_fast50_dcn_combined_256x192.pth --indir examples/demo/ --save_img


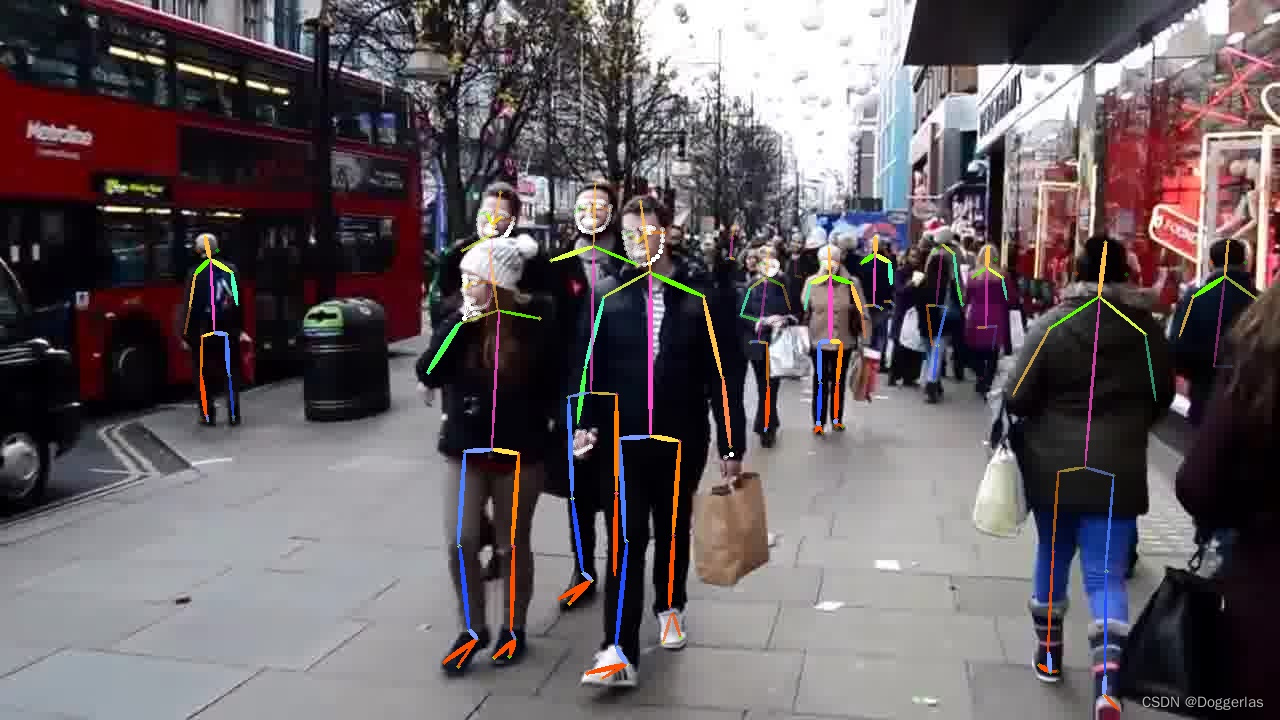


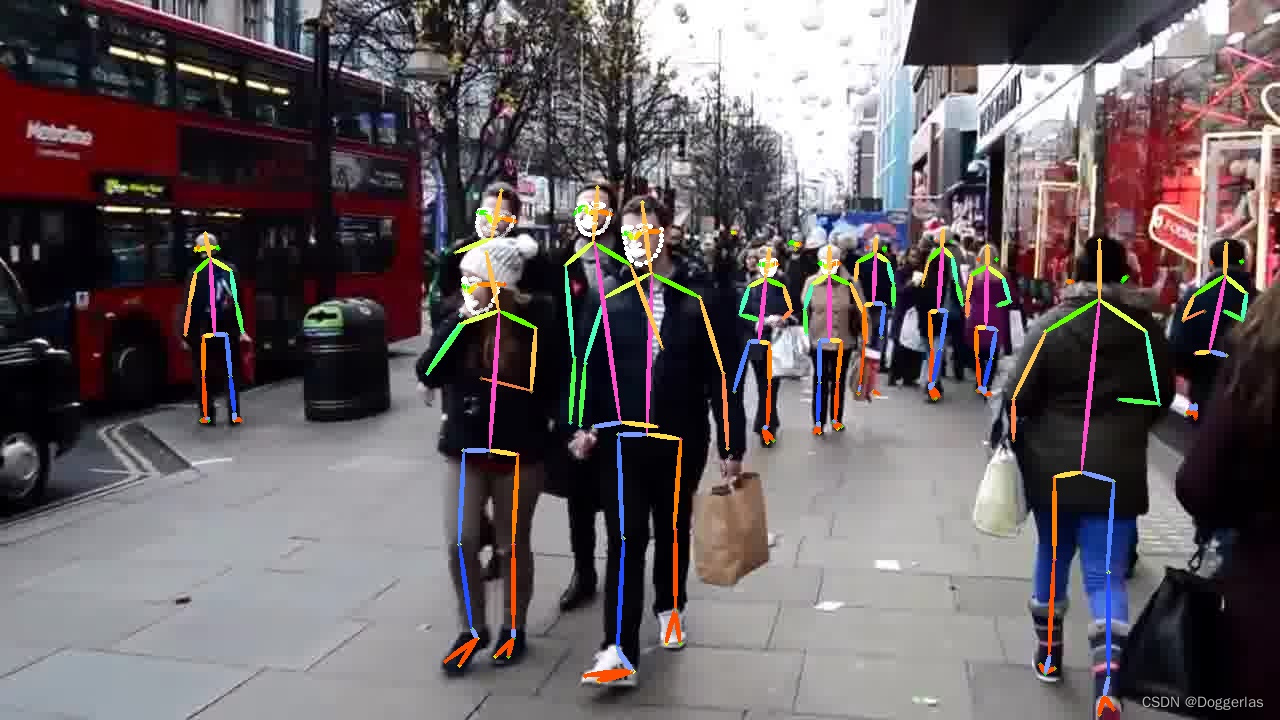
姿态追踪模型配置
1.首先尝试第一个模型 下载这个
模型移动到/trackers/weights(自己创建weights目录)
视频移动到 /examples/video_demo
(另外,可以更改/trackers/tracker_cfg.py中的cfg.arch和cfg.loadmodel来更改模型)
执行测试脚本
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --video examples/video_demo/dance.mp4 --outdir examples/res/vis_video --save_video --pose_track
原始视频(多人)

测试结果

原始视频(单人)

测试结果

原始视频(自己找的素材 多人)
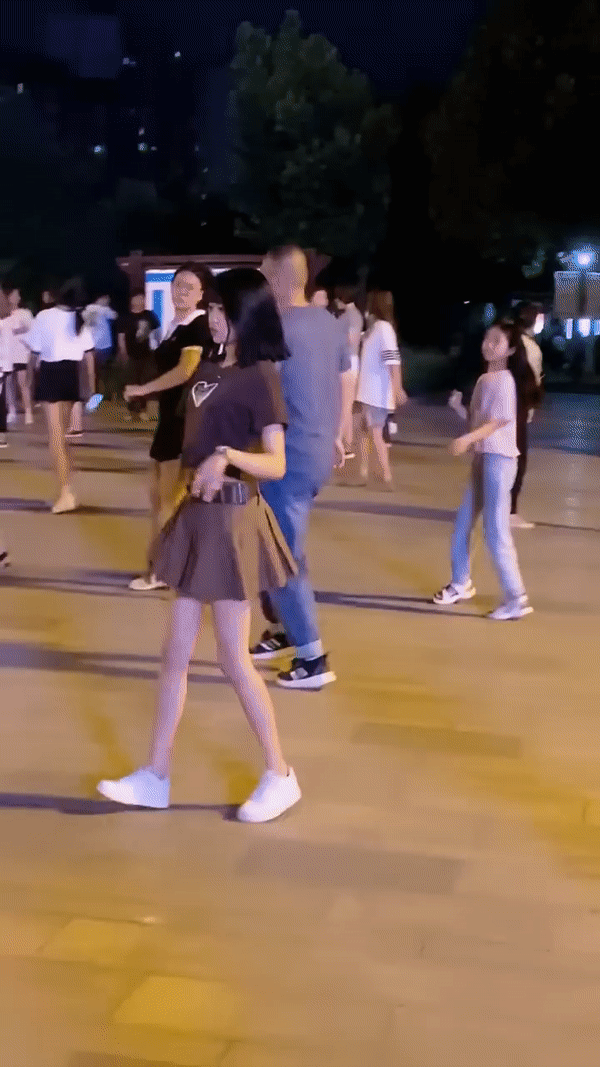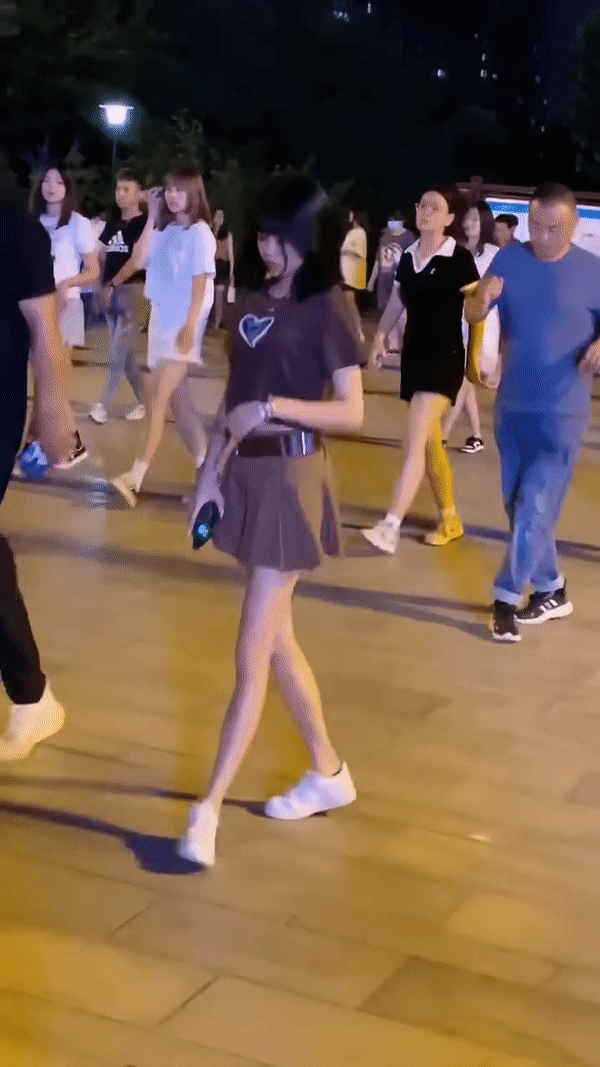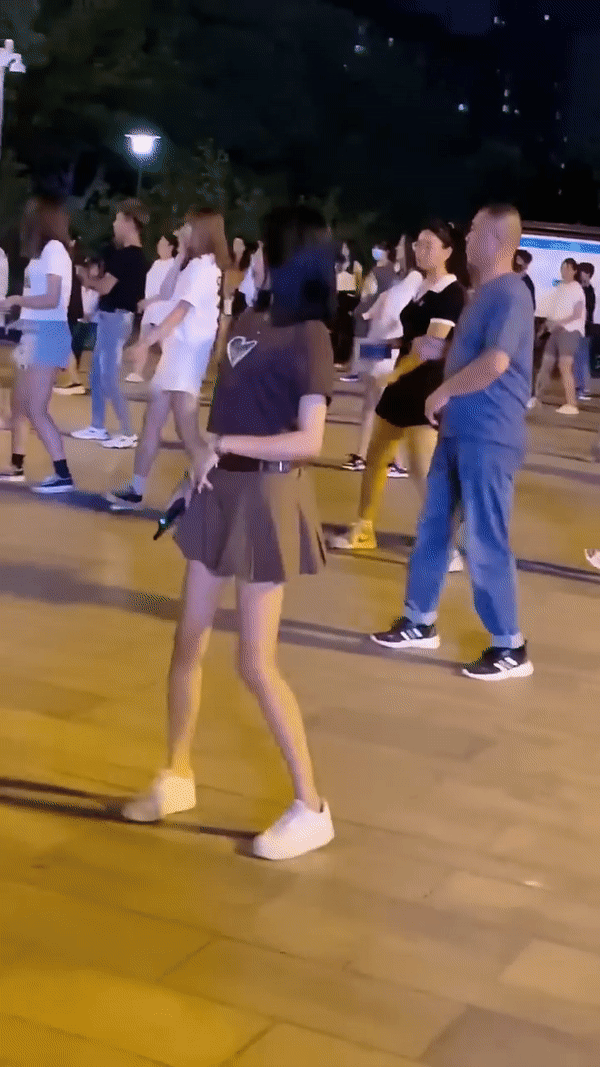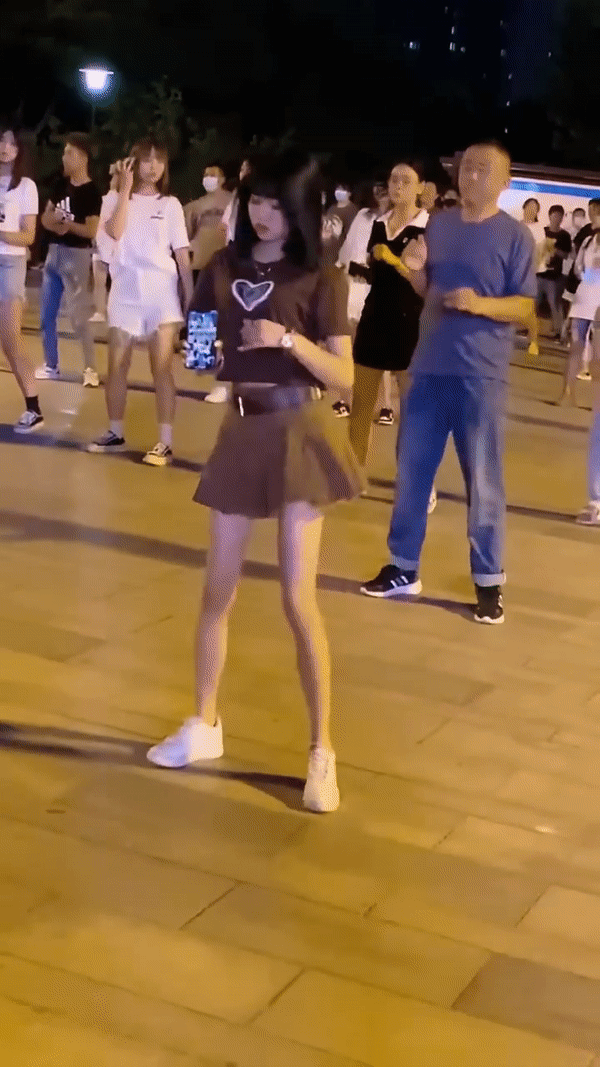
测试结果
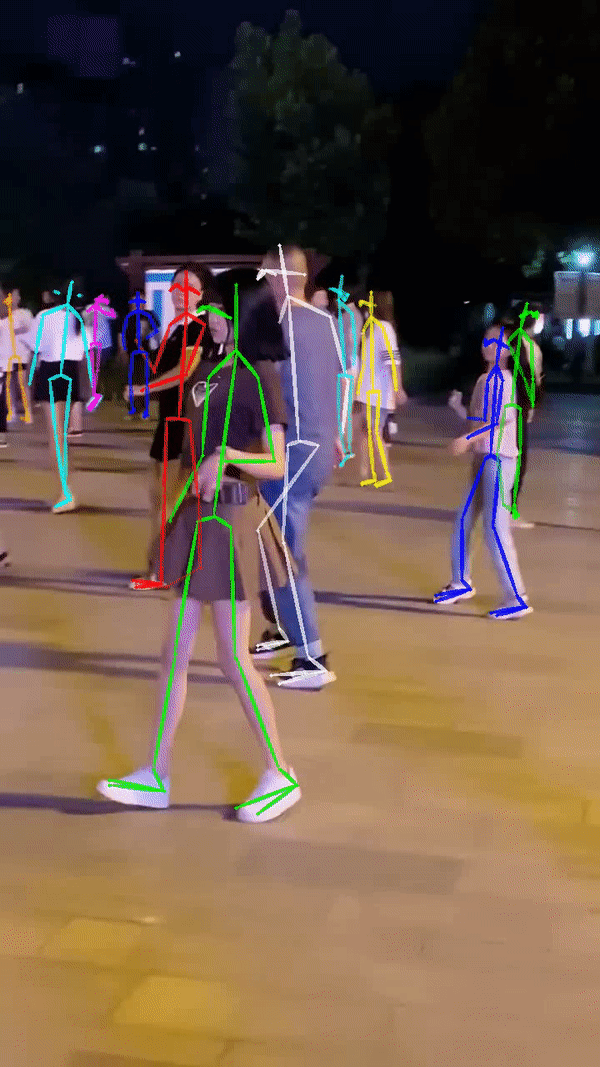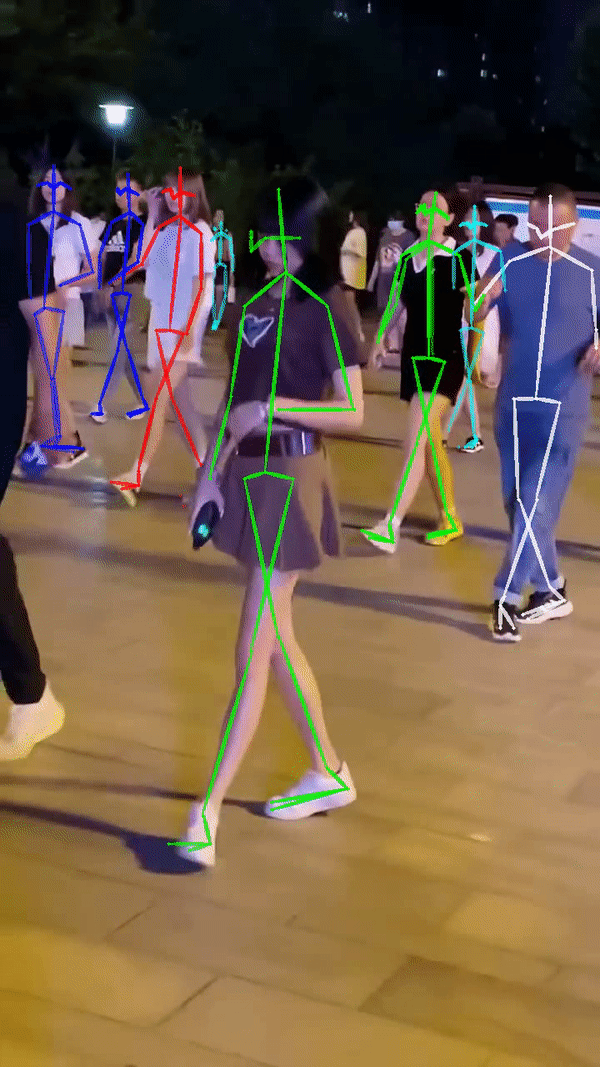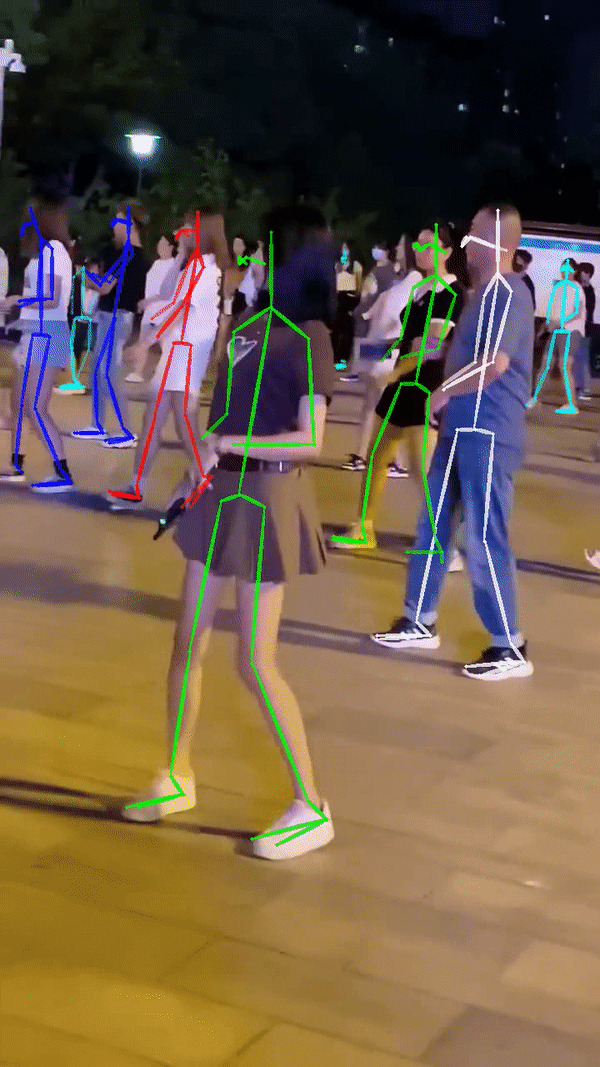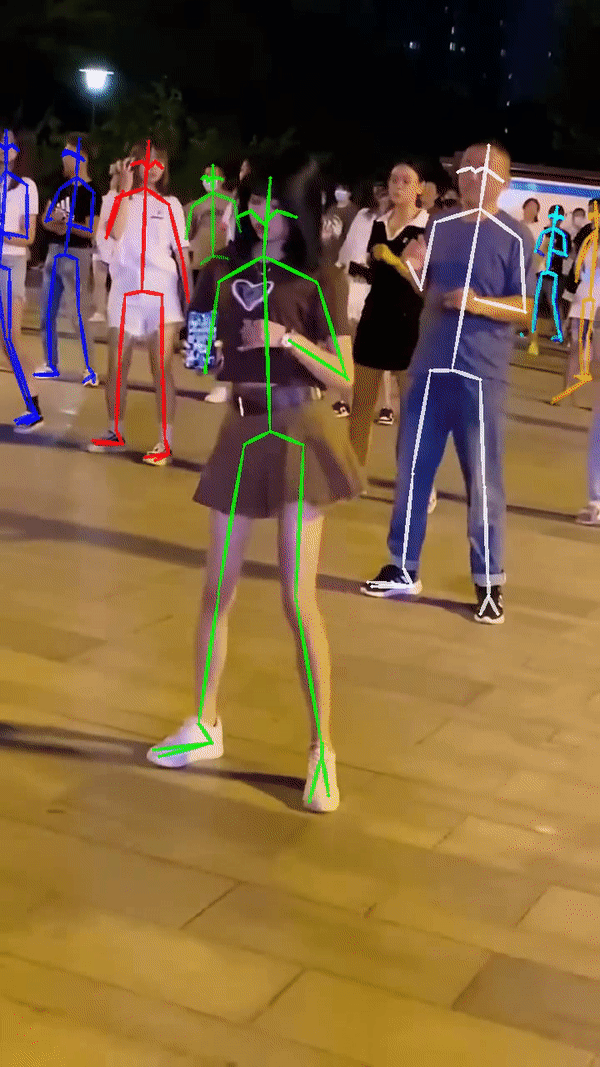
请注意:画面中人数较多,或者视频帧数多,推理时间会很长,很大概率显示CUDA显存不足并中途卡死。此时需要手动ctrl+z停止运行。但是进程并不会自动退出。请手动kill掉python进程重新运行测试脚本。如下图PID分别为3053和22703的程序占用很大显存(6641/7973),可执行以下指令手动杀死进程:
kill -9 3053
kill -9 22703

从而释放显存

2.尝试第二个模型 下载第一个
模型移动到/detector/tracker/data(需要自己创建data)
执行测试脚本(运行失败 CUDA显存不足)
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --video examples/video_demo/dance.mp4 --outdir examples/res/vis_video --save_video --detector tracker
调用摄像头实时推理
调用摄像头进行实时推理指令如下6,使用ctrl+C结束录制。视频会存储到examples/res/vis_video/AlphaPose_webcam0.mp4中。不想存储视频不加outdir和savevideo参数即可。
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --webcam 0 --vis --outdir examples/res/vis_video --save_video --pose_track

3d推理遇到的问题
在运行视频3d smpl推理脚本的时候出现以下错误:TypeError("forward() got an unexpected keyword argument 'flip_test'") when using demo_3d_inference 。 推测是Pytorch版本问题,即使我已经下载了basicModel_neutral_lbs_10_207_0_v1.0.0.pkl。所以目前AlphaPose无法进行3d捕捉。issue#11178就是这个问题,问题提出时间不长,创作团队尚未解答。
python scripts/demo_3d_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --video examples/video_demo/dance.mp4 --flip --pose_track

参数测试
Alphapose的运行时有很多参数,可以找前人做过的实验试一试6.7
比如加个包围盒
python scripts/demo_inference.py --cfg configs/halpe_26/resnet/256x192_res50_lr1e-3_1x.yaml --checkpoint pretrained_models/halpe26_fast_res50_256x192.pth --webcam 0 --vis --showbox --pose_track

参考链接
1.Alphapose - Windows下Alphapose(Pytorch 1.1+)版本2021最新环境配置步骤以及踩坑说明
2.Windows10下的AlphaPose配置,人体摔倒姿态识别
3.保姆级教程–Ubuntu18.04从零安装nvidia驱动,CUDA,cudnn及nvidia-docker2
4.doc/install.md文档有些需要更新的部分
5.论文复现–RMPE: Regional Multi-person Pose Estimation
6.第4节:alphapose项目运行和参数
7.【多人姿态估计】AlphaPose推理demo复现
8.TypeError(“forward() got an unexpected keyword argument ‘flip_test’”) when using demo_3d_inference #1117