本篇是迁移学习专栏介绍的第五篇论文,PRICAI 2014的DaNN(Domain Adaptive Neural Network)。
Abstract
提出了一种简单的神经网络模型来处理目标识别中的Domain Adaptive问题。我们的模型将Maximum Mean Discrepancy(MMD)作为正则化方法引入监督学习中,以减少潜在空间中源域和目标域的分布不匹配。从实验中,我们证明MMD正则化是一种有效的工具同时在SURF选取特征和原始图像像素的一个特定的图像数据集上,来提供良好的领域适应模型。我们还表明,提出的模型中,之前denoising auto-encoder预训练,达到更好的性能比最近的基准模型在相同的数据集。这项工作代表了在神经网络背景下对MMD测量的首次研究。
1 Introduction
在基于学习的计算机视觉中,训练样本与测试样本之间的概率分布不匹配是现实场景中成功的关键问题。例如,假设我们有一个对象识别器,它是从包含具有特定视点、背景和转换的对象的训练集中学到的。然后将其应用于具有类似对象类别,但是不同视角、背景和转换条件的环境。这种情况可能是由于缺少表示目标环境的标记数据或对目标条件的知识不足造成的。如果采用传统的学习方法对其进行训练,就不能保证得到良好的识别模型。
研究了基于领域自适应和迁移学习的分布不匹配问题的解决方法。更具体地说,给定一个训练集及测试集
分别从分布
采样,目标是预测目标标签
,并且
的信息也不充足。近年来,针对这一问题提出了许多解决方案,包括计算机视觉应用(Gong et al., 2012, Gopalan et al., 2011, Long et al., 2013, Saenko et al., 2010)和自然语言处理(Daum´e-III, 2009, Pan and Yang, 2010)。
在图像识别中,Office数据集(Saenko et al., 2010)已成为评价领域自适应模型性能的标准图像集。该数据集的标准评估协议基于使用SURF特征描述符(Bay et al., 2008)作为模型的输入。然而,使用这样一个描述符通常需要一个仔细的工程来获得良好的鉴别特性。此外,在实时特征提取过程中,它可能会带来更多的复杂性。因此,在不使用任何手工特性描述符的情况下构建好的模型是值得的。
表示或特征学习提供了一个框架来减少对手工特征工程的依赖(Bengio et al., 2012)。可以认为是表征学习的例子有主成分分析(PCA)、独立成分分析(ICA)、稀疏编码、神经网络和深度学习。在深度学习中,贪婪的分层无监督训练(layer-wise unsupervised training,简称pre - training)对深度神经网络的成功起到了重要作用(Bengio et al., 2007, Erhan et al., 2010)。尽管基于表示学习的技术在许多应用中都取得了一些成功,但是解决分布不匹配的方法还没有得到很好的研究。
在本文中,我们提出了一种简单的神经网络模型,具有良好的区域自适应性能。特别地,我们利用非参数概率分布距离度量。例如,最大平均偏差(MMD),作为嵌入在监督反向传播训练中的正则化。MMD是用来减少两个隐藏层表示之间的分布不匹配,由来自不同领域的样本引起。据我们所知,尽管MMD有效,但在神经网络环境下的应用还没有得到研究。因此,这项工作是第一个在神经网络中使用MMD的研究。具体来说,我们将研究MMD正则化是否真的能提高神经网络的识别域自适应性能。
2 Preliminaries
在这一节中,我们将描述几个与我们提出的方法相关的工具,如MMD测量、前馈神经网络和去噪自动编码器。在最近的文献中也将包括一些关于这类工具的评论。
2.1 Maximum Mean Discrepancy
最大平均偏差(MMD)是测量两个概率分布之间的差异从他们的样本。在不初始估计密度函数的情况下比较分布是一种有效的目标识别准则。给定两个概率分布,MMD定义为:式子1
(\mathfrak {F})是函数
的一个类。通过定义
作为函数unit ball在一个通用重放核希尔伯特空间(RKHS)中的函数集,用
表示,
将检测p和q之间的任何差异(Borgwardt et al., 2006)。
在数据空间,
分别为从分布
中抽取的数据向量。基于f在一个普遍的RKHS中是函数unit ball的事实,我们可以将MMD的经验估计重写为:式子2
称为特征空间映射feature space map。
通过将(2)转换为向量-矩阵乘法形式,我们得到了该形式的kwenel方程(Borgwardt et al., 2006)。式子3和式子4
其中是数据空间中所有可能内核的Gram矩阵。
在领域适应或转移学习中,MMD被用来减少源域和目标域之间的分布不匹配。Pan等人(2009)提出了一种基于PCA的模型,称为(Transfer Component Analysis, TCA),该模型使用MMD来诱导一个子空间,其中不同域中的数据分布彼此封闭。Long等人(2013)提出了一种传输稀疏编码(Transfer Sparse Coding, TSC),它在编码阶段利用MMD匹配稀疏编码的分布。
我们在这里的工作采用了类似于TCA和TSC的将MMD合并到学习算法中的思想。不同的是,在TCA和TSC都是无监督学习的情况下,我们对有监督准则进行MMD正则化。我们期望嵌入在监督训练中的MMD正则化能产生更好的识别特征。
2.2 Feed Forward Neural Networks
在过去的几十年里,前馈神经网络(FFNN)被广泛应用于解决包括目标识别在内的许多识别任务。标准的FFNN结构由三种类型的层组成,它们是具有加权层间连接的输入层、隐藏层和输出层。FFNN训练对应于根据特定的准则调整连接权值。
让我们考虑一个单层隐层神经网络,其中分别作为可见层、隐藏层和输出层。我们将
表示为相邻层之间的连接权值。FFNN可以写成:式子5和式子6
其中分别为隐含单位偏差和输出单位偏差。
注意,两个是非线性激活函数。在这项工作中,我们使用的rectifier很熟近似softplus函数
和将softmax函数
, 其中
。rectifier函数
被认为可能比Logistic函数更像生物本身(Glorot et al ., 2011)。更重要的是,多项实验工作证明整流激活函数可以提高神经网络模型的性能(Nair和Hinton, 2010)。此外,利用softmax函数对FFNN输出进行了概率解释。
给定n标签的训练数据,其中
表示每个类有一个活动输出节点的标签,以经验对数似然损失函数的形式给出FFNN的目标函数为:式子7
通常是最小的反向传播算法。
2.3 Denoising Auto-encoder
自动编码器是一种用于学习有效编码的无监督神经网络。在深度学习研究中,它被认为是一种有效的深度神经网络预训练技术(Bengio et al., 2007)。在结构上,除了输出层节点数与输入层相同外,自动编码器与标准的前馈神经网络非常相似。自动编码器的目标是通过重构损耗函数来重构自身的输入。
去噪自动编码器(DAE)是自动编码器模型的一种变体,该模型通过重构给定噪声对应的干净输入来捕获健壮的表示(Vincent et al., 2010)。定性地说,使用几种类型的噪声来识别目标噪声,如零掩蔽、高斯噪声和椒盐噪声,可以描述与第一个隐层参数相对应的特定过滤器(Vincent et al., 2010)。DAEs一直被认为比标准的自动编码器更好,在深度学习辨别性能方面可以与受限制的玻尔兹曼机相媲美(Erhan et al., 2010, Vincent et al., 2010)。
在本文中,我们将DAE作为我们提出的域自适应模型的训练前阶段。来自源域和目标域的未标记图像被认为是DAE预训练的输入。我们将研究有无DAE预训练对区域适应性能的影响。
3 Domain Adaptive Neural Networks
我们提出了一个标准前馈神经网络的变体,我们称之为域自适应神经网络(DaNN)。该模型将MMD测度(2)作为正则化方法嵌入到有监督的反向传播训练中。通过这种正则化,我们的目标是训练网络参数,使监督准则得到优化,并使隐含层表示形式在不同的域中保持不变。
给定一个元数据标签,以及没有标签的目标数据
,给出了单一层DaNN的损失函数:式子8
其中是与(7)相同的损失函数,但仅应用于源数据,
是激活前的输出线性组合,
是正则化常数控制MMD对损失函数贡献的重要性。
为了最小化(8),我们需要的梯度。同时计算
的梯度
是平凡的,计算
的梯度取决于核函数的选择。我们选择高斯核函数作为形式的核函数,它被认为是一个通用核函数(Steinwart, 2002)
,其中s为标准差。
通过函数-向量形式,我们可以重写函数(8)中为高斯核函数。表示样本向量
,
。每个样本中的附加元素1被用来将计算与偏差结合起来。我们来定义参数矩阵
和
。因此
函数能被重写为:式子9
让是
的梯度,对于
,
可以是s或者t,然后
来源于:式子10
现在很容易看出的梯度为
:式子11
选择高斯核的主要原因是,它已经得到了很好的研究,并在实践中证明了MMD的实用性(Gretton et al., 2012)。此外,值得注意的是,MMD在这里应用于线性组合输出之前,我们把非线性激活函数。这意味着MMD提供了一个关于隐藏表示的实际分布差异的有偏估计。然而,由于我们使用接近线性的整流激活函数,我们期望(9)中的测量值能够很好地逼近真实的分布差异。
在实现过程中,我们将JNNs和分为两步。首先,利用对U1更新的小批量随机梯度下降,使JNNs最小化。小批量设置已经成为神经网络训练的一种标准做法,以建立速度和准确性之间的妥协。然后,
通过对梯度(11)重新更新U1来最小化。后一个步骤是通过全批量梯度下降来完成的。算法1总结了这个过程的细节。

4 Experiments and Analysis
在多个领域不匹配的情况下,我们在目标识别上下文中评估了我们提出的方法。我们首先将DaNN与基线和其他最近的领域适应方法进行了比较。然后报告了以30次独立运行的平均值和标准差表示的识别精度的结果。最后,通过测量一个域与另一个域之间第一隐层激活量的差值,研究了MMD正则化的效果。
4.1 Setup
我们的实验使用了Office数据集(Saenko et al., 2010),其中包含来自三个不同领域的31个对象类的图像:amazon、webcam和dslr。在amazon中,图像包含一个单独的居中对象,而对于其他图像,则是在不受约束的设置中获取的,其中包含一些变化,如光照和背景更改。这里我们只使用了10个对象类,遵循Gong等人(2012)设计的协议,最终总共使用了1410个实例。amazon、webcam和dslr的图像数量分别为958、295和157。基于定义域(ROD)测度的秩(Rank of Domain, ROD),网络摄像头和单反被认为是更相似的(Gong et al., 2012)。图1中可以看到Office图像的示例。

实验中使用的DaNN模型只有一个隐藏层,即,一个由256个隐藏节点组成的浅层网络。DaNN的输入层可以是原始像素,也可以是SURF特性。输出层包含与十个类对应的十个节点。
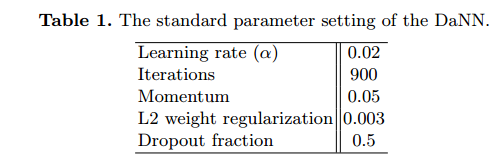
在我们所有的实验中,我们都使用了表1中指定的有监督反向传播学习的参数设置。注意,我们采用了Hinton等人(2012)引入的dropout正则化,该正则化对每个具有一定概率的训练用例随机省略一个隐藏节点。
在减少过拟合的意义上,如果从一个小的训练集训练一个神经网络,它被证明可以产生更好的性能。
对于MMD正则化,我们通过如下计算设置高斯核的标准差 (Baktashmotlagh et al., 2013),其中MSD为所有源样本间距离的中值平方。MMD正则化常数γ被设置足够大(
),以适应小的值(11)相比
为每个迭代。
我们根据来自Office数据集。评价分为两种情况:1)无监督适应和2)半监督适应。当我们在训练过程中既可以使用源域的标记图像,也可以使用目标域的未标记图像,但不合并目标域的标记时,无监督自适应对应于该设置。在半监督自适应中,我们将来自目标域的一些标记图像合并为额外的训练图像。选择目标域中每个对象类别的前三个图像。与最初的工作不同(Saenko et al., 2010),我们使用了来自源域的所有标记图像,而不是随机采样。
然后将我们的模型与基于SVM的基线、现有的两种域自适应方法以及一个简单的神经网络进行性能比较:
L-SVM:一个线性核支持向量机(Cortes and Vapnik, 1995)模型,应用于原始特征。
L-SVM + PCA:与L-SVM模型相同,但在模型之前使用PCA来降低特征维数。
GFK (Gong et al., 2012):考虑源域和目标域之间无限多的中间子空间,然后进行k-NN分类的大地测量流核方法。
TSC (Long et al., 2013):基于图的正则化稀疏编码与MMD正则化、logistic回归相结合的传输稀疏编码技术。
NN:一种单层神经网络,结构和参数设置与我们的DaNN相同(表1),但没有MMD正则化
4.2 Results on SURF Features
我们首先研究了我们的模型在龚等人(2012)提供的标准图像特征上的性能。简单地说,首先利用缩放和灰度图像上的SURF描述符来检测局部尺度不变的兴趣点,从而获得图像特征。然后,使用从amazon图像子集训练而来的代码本将数据点编码为800-bin直方图(Saenko et al., 2010)。最后的特征被归一化,z得分为零均值和单位方差。我们进行了无监督设置评估,结果如表2所示。
我们发现,在这些标准特性上,DaNN和TSC比其他方法具有更好的性能。更具体地说,当特定域对中有amazon集时,DaNN的性能很好。在webcam-dslr移位的情况下,在以前的工作中没有在Office数据集上测试过的TSC是令人惊讶的最佳模型。尽管TSC方法有效,但与基于神经网络的方法相比,TSC具有更长的特征提取时间,因此在实际应用中效率较低。我们还注意到,包含多个中间子空间的GFK在一些情况下没有超过基线。这表明对GFK生成的子空间的投影不足以减少域不匹配。

4.3 Results on Raw Pixels
我们还对Office图像的原始像素进行了评估。以前关于Office图像集的工作大多是使用基于冲浪的特性完成的。直接研究Office原始像素上的性能是值得的,因为在减少手工特征提取器需求的意义上,在原始像素上的好模型更可取。我们首先将2D RGB值中的Office图像像素转换为灰度像素,并将其调整为28 - 28维。然后z分数为零,单位方差为零。
Domain Adataption Setting
在这个实验中,我们对所有的域对运行了无监督和半监督自适应设置。此外,我们还研究了神经网络和DaNN监督训练之前的DAE预训练对性能的影响。DAE预训练会稍微改变算法1的步骤1。我们将这些模型分别表示为DAE + NN和DAE + DaNN。图2描述了预训练权重的示例。表3给出了所有域对的Office原始像素的完整准确率。


很明显,与基于svm的基线和神经网络模型相比,我们的DaNN始终在所有域对上提供精度改进。换句话说,MMD正则化确实提高了神经网络的性能。与在无监督训练阶段采用MMD正则化的TSC相比,我们的DaNN在大多数情况下都有较好的表现。然而,TSC可以匹配网络摄像机-单反相机对DaNN性能的影响,与其他单反相机相比,TSC具有较低的水平失配。这表明,在有监督训练中使用MMD正则化可能比在无监督训练中获得更多的适应能力,对不匹配较难解决的配对。
将DAE预训练应用于神经网络和DaNN中,确实提高了所有对域的性能。这些改进对于一些情况来说是非常重要的,特别是对于网络摄像头-单反的情侣。一般来说,DAE预训练也产生了更稳定的模型,即在30次独立运行中产生更低的标准差。此外,在这些实验中,DAE预训练和DaNN的结合几乎在所有情况下都表现得最好。在定性分析的意义上,如图2所示,DAE预训练捕获了从本地blob检测器到对象部件检测器的更独特的\filter \,特别是包含amazon图像时。这一效果与最初DAE工作中发现的结果多少是一致的(Vincent et al., 2010),这表明DAE预训练提供了更有用的神经网络表示。
在半监督设置中,性能趋势与非监督设置有一定的相似性。然而,与无监督设置相比,神经网络和DaNN的性能差异变得更小。这一结果也适用于DAE的培训前情况。这表明,当从目标区域获取一些标记图像时,MMD正则化和DAE预处理的效果都可能较差。
In-domain Setting
有人可能会问,与标准的学习设置相比,表3所示的领域适应结果是否合理。我们将此标准设置称为域内设置,其中训练和测试样本来自相同的域。域内性能可以作为一个参考指标,表明域自适应模型在处理域不匹配时的有效性。
我们研究了4.1节中描述的非域自适应模型的域内性能,即、L-SVM、PCA+L-SVM、NN对办公图像原始像素的检测。对于每个域,我们进行了10次交叉验证。以均值和标准差表示的完整域内结果如表4所示。一般情况下,我们可以看到最好的域内模型是训练图像和测试图像的神经网络模型。

与域自适应结果相比,使用amazon或webcam作为目标集时,域内的最高准确率要优于域内不匹配的结果(最高准确率见表3)。这表明可能需要一个更好的域适应模型来克服这些不匹配。然而,当dslr作为目标集时,其域内精度甚至低于W上的最佳域自适应结果
。了解到摄像头和数码单反图像非常相似,摄像头的图像集也比较多,说明域自适应确实有助于为这种设置生成更好的对象识别模型。
5 Conclusions and Future Work
本文提出了一种简单的神经网络模型,即域自适应神经网络(DaNN),以减少目标识别中的域不匹配问题。在这项工作中,我们利用MMD测量作为正则化的监督反向传播训练。这种正则化鼓励隐藏层表示分布彼此相似。我们证明了DaNN在Office图像集上表现良好,特别是在原始图像像素作为输入时。此外,与基于svm的基线、GFK (Gong et al., 2012)和TSC (Long et al., 2013)在几乎所有域对的办公室图像集中(Saenko et al., 2010)相比,在去噪自动编码器(DAE)预训练之前的DaNN具有更好的性能。
尽管MMD的正则化效果显著,但仍有许多方面有待进一步改进。我们已经看到,原始像素上的性能仍然不如SURF特性上的性能好,而原始像素是表示学习方法的主要关注点。我们注意到,在没有任何手工特性提取器的情况下,性能良好的模型可以更好地降低复杂性。由于深度架构近年来在许多应用中取得了一定的成功(Bengio, 2013),因此使用更深层的神经网络层和类似的策略,可以在原始像素上实现更好的模型(Bengio, 2013)。我们使用带DAE预训练的标准深度神经网络(由于页面限制,这里没有显示)进行的初步工作表明,较深的表示并不总是能够提高针对域不匹配的性能。
此外,对于计算MMD的内核选择问题,从领域适应的角度进行研究也是值得探讨的。我们假设,通用高斯核函数能够检测出办公数据集中任何潜在的分布不匹配,这可能是不正确的。更好地理解核函数与特定图像失配的关系,如背景、光照、仿射变换的变化等,将对这一领域的研究产生重要的影响。