行人重识别之端到端的生成与识别
Joint Discriminative and Generative Learning for Person Re-identification
原文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Zheng_Joint_Discriminative_and_Generative_Learning_for_Person_Re-Identification_CVPR_2019_paper.pdf
喜欢公布代码的文章,这样对于推动科研的发展才更有意义,也更经得起检验。推荐大家看看这篇文章的代码:
https://github.com/NVlabs/DG-Net
一般的使用GAN做样本增强的算法都是先训练GAN,然后再用生成的图像训练CNN。这篇文章的贡献是将两者结合成了端到端的网络,与此同时也在一定程度上解决了行人重识别中图像的结构变化、外观变化的问题。唯一的缺点是,损失函数的超参数偏多,训练流程些许繁琐。
话不多说,直接分析其算法框架:
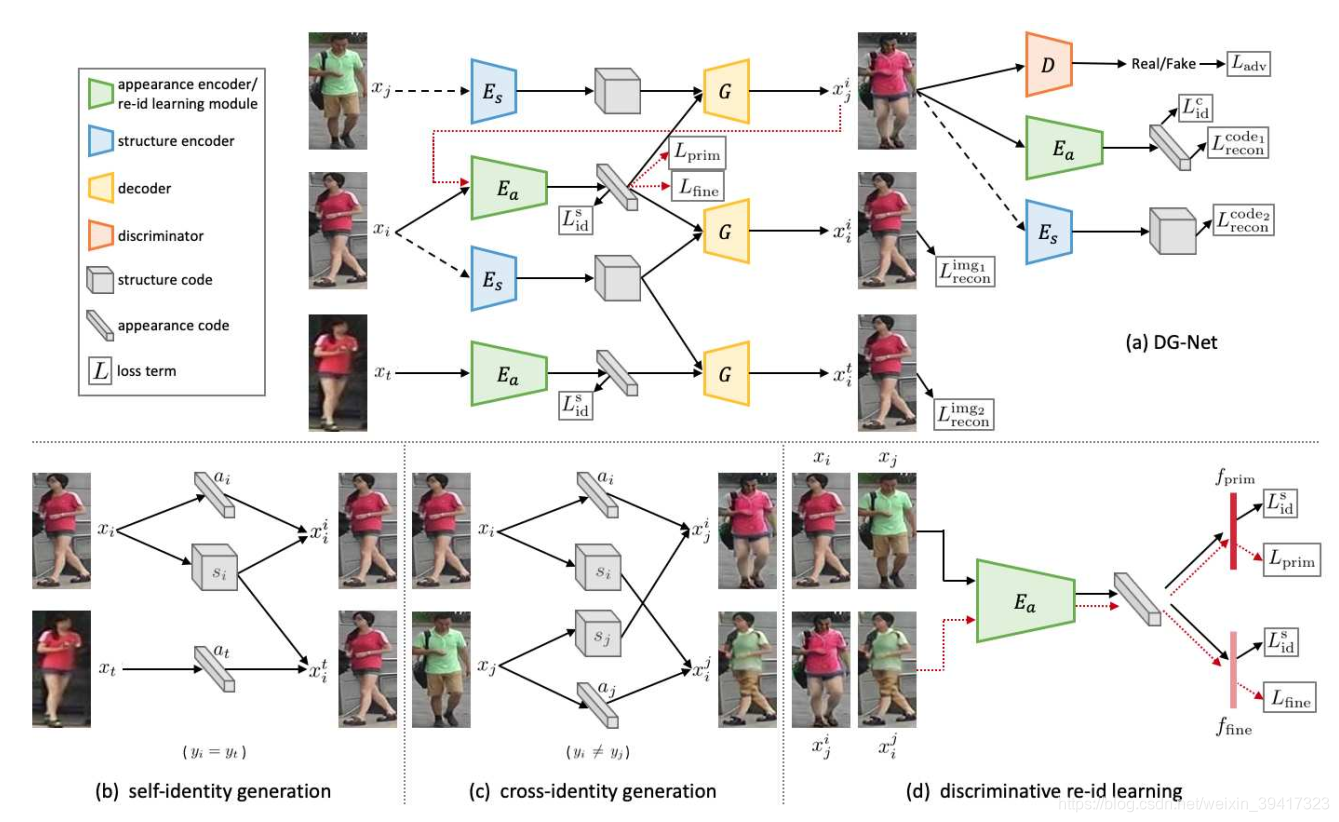
-
图中的编码器、生成器、判别器都是resnet的结构,在层数上有一些差别。
-
a代表外观信息,包括服装、头发、背包、背景等。s代表结构信息,主要指行人动作,具体如下图。除了最左一列和最上一行的图像,其余都是生成的。

-
x只有下标:表示数据库中的第i张图像。
-
x有下标和上标:图像是生成的,利用了上标图像的外观信息,利用了下标图像的结构信息。看一下框架图中的c就可以理解。
了解了以上内容,接下来详细说一下算法的内容:
(接下来用a代表外观特征向量、s代表结构特征向量)
生成模型:

类内生成模型:
如(b)所示,提取i的a和s,提取t的a,两张图像的label相同,所以利用以上a和s生成的图像应该是相同的。损失函数如下:
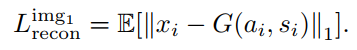

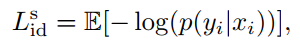
前两者对生成图像的差异进行惩罚,后者对图像的label进行监督。通过以上三者,实现了类内生成的监督。主要目的是为了训练G。
注意:由于G对于s更加敏感,容易忽略a,所以,提取s的时候只使用灰度图像。
类间生成模型:
如图©,作者希望生成的图像提取出的a和s与生成该图像的a和s是一样的,所以,对前后的a和s的差异性进行惩罚。
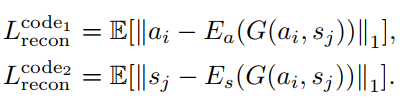
同样,对生成图像的label进行监督。
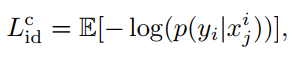
注意:这里是希望生成的图像与生成其使用的a对应的图像的标签相同。
同时,要对判别器进行约束:
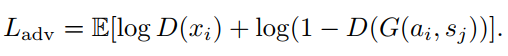
识别模型:
使用原数据库训练一个teacher model,其预测的图像label为q。
该部分利用了两个损失函数:
使用i的a和j的s生成的图像到底属于i还是j呢?为此作者使用了软标签,损失函数如下:
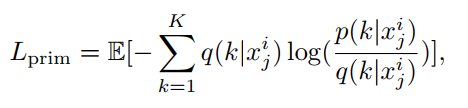
K是标签的种类,p是E得到的图像标签概率。使用该公式就实现了软标签。
为了让模型更加关注除了衣服颜色以外的细节信息,作者假定,使用同一个s不同a生成的都是同一身份,这样就强行让模型忽略服装颜色,从而尽可能关注一些其他信息。损失函数如下所示:
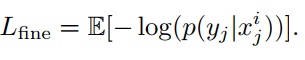
最后将两大部分的模型联合训练,多个损失函数互相补充,实现较好的效果。测试的时候只需要使用Ea和Es,将两者提取的特征进行连接,进行识别。
总结:这篇文章的工作量较大、思路也比较新颖。大多数文章使用GAN解决跨数据库问题,这篇文章使用GAN解决了数据库内部的种种问题。文章的细节较多,这篇博文适合于辅助该文章的阅读。还是强烈推荐大家看看文章的代码。
完
欢迎讨论 欢迎吐槽
