相应软件下载:
Fiddler - 请求捕获工具,PC和手机都行。提取码:6qjt (推荐百度自行下载最新版)
7月初,放了几天暑假,到了大三了,要准备实习的事宜,就到各大招聘平台上搜寻称心的职位,我就想着找份关于Python方向的实习,但是各大平台关于Python的实习少之又少,只有实习僧平台稍许有点关于Python的实习。因为最近找到了一些数据图形化显示的开源库,就想着爬取实习僧的职位信息下来进行数据可视化分析分析。
起初,打开分析了实习僧的网页源代码,觉得应该挺简单的,但后来才发现,实习僧使用了字体反爬,职位信息的某些字段在源代码中显示不出来的。

以上职位的标题字段在源代码中有些显示不出来的:
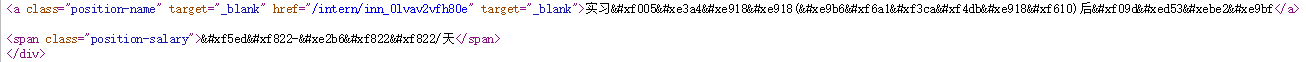
类似于标志的是实习僧自定义字体的标识,后来在网上找了一下怎样破解字体反爬,发现主要有几种方法:
- 字体静态映射:用人工的办法把对应的字体和标识保存下载,以便在爬取的时候进行解析。
- 分析ttf文件:解析源代码的ttf文件资源下来,转化为xml格式,根据字体的绘制路线和动态变化的规律,进行动态解析字体。
- OCR识别
以上几种方法中,前两种办法太麻烦,太浪费时间,而且还有点不稳定因素,果断放弃。最后一种OCR识别看着就觉得太高端,本着做个简单小爬虫的,所以放弃。
因为以上几种办法都不喜欢用,所以又仔细研究了网页源代码,然后惊奇的发现点开职位的详细的链接之后,里面的内容是没有使用自定义字体的了,这就说明我可以在搜索界面获取链接,然后再爬取链接对应页面的内容绕过字体反爬。但后来又想了一下想,如果这样做的话,每个职位都要爬取一个页面,哪所有的加起来也不是一个小数目了,有可能会被封IP,本着做个小爬虫,不想弄代理,也没钱弄代理,免费的也不好用,所以又pass掉这个方案。
在以上诸多方案被我抛弃掉之后,本想直接去github找别人已经做好的字体反爬的项目来抄抄,但是突然想起来,我实习僧的PC网页不能爬取,或许我能使用移动端进行爬取,绕过字体反爬。
然后我就通过电脑使用Fiddler软件配置代理,手机连接代理进行请求的捕获,懒得下载手机app,直接扫码打开的实习僧的微信小程序,进入职位搜索界面进行搜索,不出我所料,果然就找到的职位的API了:

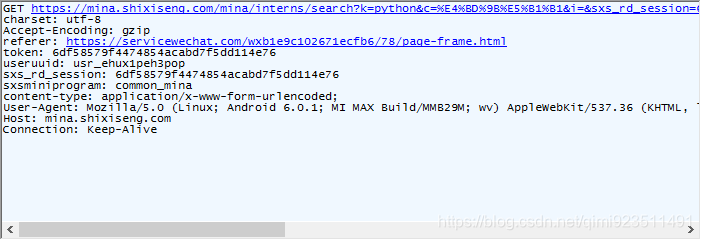
打开请求的详细信息:
请求头:
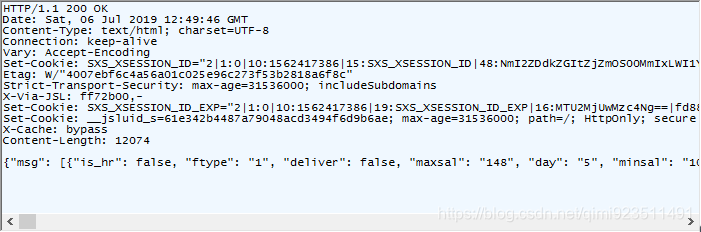
响应头:
取响应头其中的一条数据数据进行格式化:
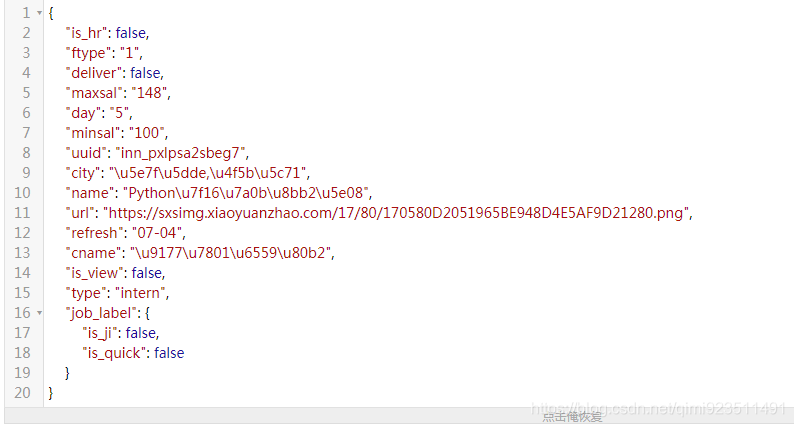
对应的职位信息就出来了,其中\u等前缀的字符是unicode编码,使用Python的json模块进行解析字符串就显示中文了:
import requests
import json
parameters = {
'k' : 'python',
'c' : '广州'
}
html = requests.get('https://mina.shixiseng.com/mina/interns/search', params=parameters)
#加载字符串为字典对象
result = json.loads(html.text)
#职位索引
index = 0
print('城市:', result['msg'][index]['city'])
print('职位名称:', result['msg'][index]['name'])
print('logo:', result['msg'][index]['url'])
print('时间:', result['msg'][index]['refresh'])
print('公司名称:', result['msg'][index]['cname'])
对应的控制台输出:
城市: 广州
职位名称: 研发工程师
logo: https://sxsimg.xiaoyuanzhao.com/company_logo/2015-14/bQY7aMiVDh2L365.png
时间: 06-27
公司名称: 三地信息
- city - 对应所在城市
- name - 对应职位名称
- url - 公司的logo
- refresh - 时间
- cname - 公司的名称
这个API没有设置任何的反爬的机制,甚至在PC浏览器上直接输入,都会接收请求处理。

