大佬的之前的一篇论文DFN也是从类内与类间的角度解决语义分割的难点。在ADE20K上效果很好,但是不知道为啥在Cityscapes效果没有那么出众,可能是数据集特点不同。
Github:https://git.io/ContextPrior

Abstract:
最近的语义分割工作广泛探索了上下文相关性,以实现更准确的细分结果。但是,大多数方法很少区分不同类型的上下文依赖项,这可能会有损场景理解。在这项工作中,我们直接监督特征聚合以清楚地区分类内和类间上下文信息。具体来说,我们在Affinity Loss监督下开发出上下文先验。 给定输入图像和相应的gt,Affinity Loss将构建理想的类似的特征图,以监督上下文先验的学习。 所学习的上下文先验提取属于同一类别的像素,而相反的先验则专注于不同类别的像素。 通过嵌入到传统的深度CNN中,提出的上下文先验层可以选择性地捕获类内和类间上下文相关性,从而实现可靠的特征表示。 为了验证有效性,我们设计了有效的上下文先验网络(CPNet)。大量的定量和定性评估表明,所提出的模型与最新的语义分割方法相比具有良好的表现。 更具体地说,我们的算法在ADE20K上达到46.3%的mIoU,在PASCAL-Context上达到53.9%的mIoU,在Cityscapes上达到81.3%的mIoU。
Introduction:

当前在上下文信息依赖上的语义分割工作主要有两种:
1)基于金字塔的聚合方法。几种方法采用基于金字塔的模块或全局池来规则第聚合局部区域或全局上下文详细信息。但是,它们捕获了同质的上下文关系,而忽略了不同类别的上下文相关性。如图1(b)所示。当场景中存在混淆类别时,这些方法可能会导致上下文可靠性降低。
2)基于注意力的聚合方法。最近的基于注意力的方法学习通道注意力,空间注意力或像素点注意力以选择性地聚集异构上下文信息。但是,由于缺乏显式的正则化,注意力机制的关系描述不太清楚。因此,它可能会选择不良的上下文依赖关系。如图1(e)所示。总体而言,这两种路径都在没有明确区分的情况下汇总了上下文信息,从而导致了不同上下文关系的混合。
针对以往方法上下文信息不区分类别的问题,本文通过构造Context Prior,以将类内和类间的依赖关系建模为先验知识。将上下文先验公式化为二进制分类器,以区分当前像素属于同一类别的像素,而相反的先验可以集中于不同类别的像素。具体来说,本文首先使用全卷积网络来生成特征图和相应的先验图。 对于特征图中的每个像素,先验地图可以选择性地突出显示属于同一类别的其他像素,以聚集类内上下文,而相反的先验可以聚集类间上下文。为了将先验嵌入网络,本文开发了一个包含Affinity Loss的Context Prior Layer,它直接监督先验的学习。 同时,上下文先验还需要空间信息来推理这些关系。 为此,设计了一个聚合模块,该模块采用完全可分离的卷积(在空间和深度维度上均分开)有效地聚合空间信息。
Context Prior Layer:

先介绍一下整体流程,再细说每个模块:
1.经过Backbone Network生成特征图X,其尺寸为H × W × C0
2.使用可以聚合空间信息的Aggregatation Module生成H × W × C1特征图
3.经过卷积,生成H × W × (H * W)尺寸特征图,再进行Reshape,得到(H * W) × (H * W)的Context Prior Map,其中p为与其他像素是否同类的概率
5.对经过类内先验§和类间先验(1-p)的特征图与输入X进行Concat
6.为了保证Context Prior Map的准确,引入Affinity Loss监督学习
Affinity Loss:
这里算的loss是Context Prior Map与经过GT生成的Ideal Affinity Map之间的损失。首先介绍一下,Context Prior Map中H * W为输入特征的像素点个数,(H * W) × (H * W)的意思是输入特征图中每个像素点与其他像素点是否为同类别的概率。算loss之前,需要先生成Ideal Affinity Map。

如上图所示:
1.给定GT,先经过One-Hot编码,生成H × W × C的特征图,其中C为类别个数。图中的[1,0,0]代表该像素点属于第一个类别。
2.特征图与其转置矩阵相乘,得到生成的Ideal Affinity Map,图中每个像素点的值代表此像素点与其他位置像素是否为同类别,只有0,1两个类别。
对于先验图中的每个像素,这是一个二分类问题。 解决该问题的常规方法是使用二进制交叉熵损失:
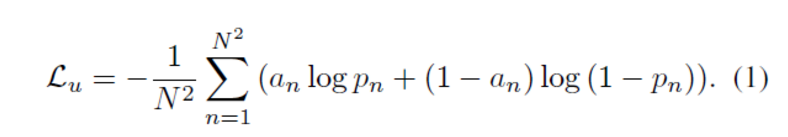
然而,这种一元损失仅考虑了先验图中的孤立像素,而忽略了与其他像素的语义相关性。先验特征图P的每一行的像素对应于特征图X的像素。 本文可以将它们分为类内像素和类间像素,它们之间的关系有助于推理语义相关性和场景结构。 因此,本文可以将类内像素和类间像素视为两个整体来分别对关系进行编码。 为此,本文基于二元交叉熵损失设计了全局项:

其中,(2)-(4)分别代表了先验图P中的第j行的类内预测值(精度),类内真实率(召回)和类间真实率(特殊性)。意思是将单个像素的类别预测与先验图全局的类内类间预测相关联。因此,Affinity Loss定义为:
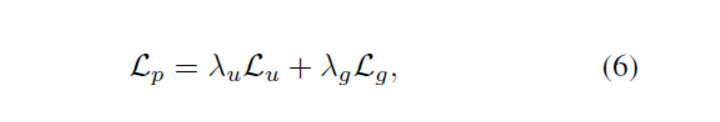
Aggregatation Module:
由于上下文先验图需要一些局部空间信息来推理语义相关性。 因此,本文设计了一种高效的聚合模块,该模块具有完全可分离的卷积(在空间和深度维度上均独立),以聚合空间信息。

如上图所示,由于常规卷积无法提取空间信息,本文使用1 × k DW + k × 1 DW代替k × k 卷积,作者这种方式为Fully Separable Convolution.。
Experiments:
1.消融实验:

2.Aggregatation Module:

3.ADE20K:

4.PASCAL-Context:

5.Context Prior Map:
