残差编码:
Fisher Vector
https://blog.csdn.net/ikerpeng/article/details/41644197
VLAD特征
https://blog.csdn.net/happyer88/article/details/47054503
深度纹理编码网络 (Deep TEN: Texture Encoding Network)
语言: English
这是一篇CVPR2017的投稿 (ArXiv的链接:https://arxiv.org/pdf/1612.02844v1.pdf)在这里给大家介绍一下这部分的工作,不像写论文那样用词严谨,这里简单介绍一下核心思想,方便大家阅读。(我个人是来到美国之后才接触科研,文中学术名词的汉语表述有不当之处还请谅解。)
我们提出了一个新的深度学习模型,这个模型推广了传统的字典学习 (dictionary learning) 和残差编码 (Residual Encoders),比如 VLAD 和 Fisher Vector。提出的编码层 (Encoding Layer) 和已有的深度学习结构兼容,实现了端对端的材料识别 (End-to-end),并且取得了不错的效果。
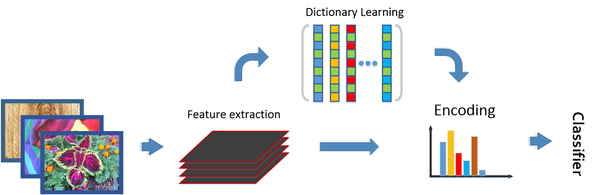
这个方法主要是受到传统方法的启发:对于输入的图片,我们通常先提取图像特征(比如SIFT 或者是 filterbank responses),之后一个字典可以通过非监督式的聚类得到,这样我们可以对已有的图片特征进行编码(材料识别中通常使用一些无序的编码器,比如BoWs,VLAD),并使用分类器进行分类。传统方法有以下两个特点:1. 输入图片可以为任意大小,编码器可以转化为一个固定长度的表达。2. 特征本身是通用的(domain-independent),字典和编码表达通常挟带了域信息(domain-specific information)。
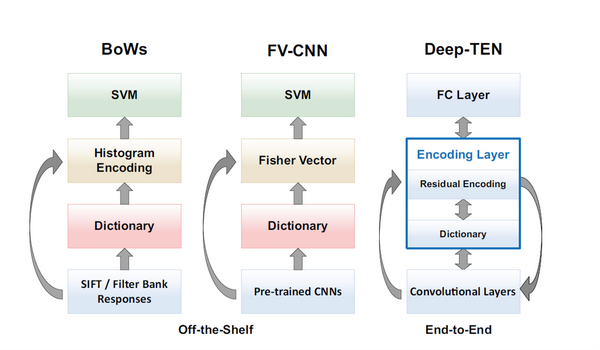
受到传统方法的启发(左图),Cimpoiet. al. CVPR 2015 使用了预训练的神经网络的卷积层提取了深度特征,并且使用了 Fisher Vector 编码器,刷新了当时的state-of-the-art(中图)。但是这种方法仍然有局限性,因为它包含了许多分步的优化,这样特征提取(卷积层),字典学习和编码器不能够从标识的数据(labeled data)中得到进一步优化。理想的方法是如右图,将整个字典学习和编码整合到一个CNN网络层中,使它与已有的深度学习体系兼容,这样以来就实现了端对端的学习优化。
方法部分有一些tricky,我们主要是提出了个数学模型 (Residual Encoding Model),推广了已有的编码器 (VLAD, Fisher Vector),并且使得整个系统是可微分的,这样我们就可以像已有的深度学习层一样,从loss function中学习到参数。也就是说它实现了监督式的字典学习(supervised dictionary learning)。这个模型有很多特性,它使得CNN网络可以接受任意大小的图片,并且因为字典学习和表达容易携带Domain信息,这样学习到的深度特征就更加容易应用于其他domain。
这个模型有很多可以应用的地方,除了文中提到的材料/纹理识别以外,因为它推广了VLAD和Fisher Vector,那么可以期待它在Robust Recognition中的应用前景(比如场景识别scene understanding),还有图像检索(image retrieval) 等等。欢迎大家多关注我的工作,而且我们提供基于Torch的代码(zhanghang1989/Deep-Encoding)。我个人现在在做visualize 和 inverse 这个编码网络,欢迎多交流 ([email protected])。
参考:机器视觉:GMM、fisher vector、SIFT与HOG特征资料
图像检索:BoW图像检索原理与实战
Context Encoding for Semantic Segmentation
https://blog.csdn.net/u013548568/article/details/80223804
https://blog.csdn.net/u011974639/article/details/79806893