CVPR2018 ORAL
2018年3月,作者单位:Rutgers University
作者博客
EncNet_cvpr2018_slides
源码

贡献1、Context Encoding Module + Semantic Encoding Loss (SE-loss)
这个context encoding module和SENet的SE-block大同小异,作用就是一个channel attention。
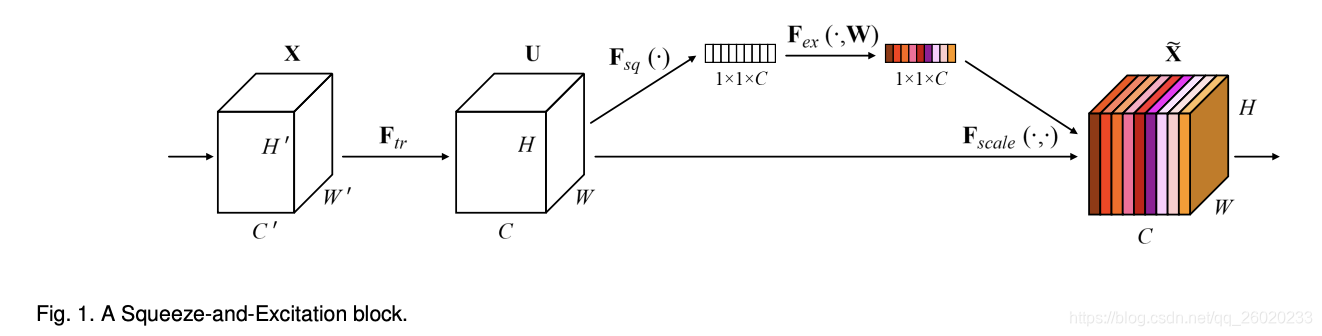
context encoding module中的encoding layer结构是作者在cvpr2017中的一个工作,将CNN引入了字典学习,具体如下所示:

此外,引入的SE-loss的好处是,不同于per-pixel loss,SE-loss对不同大小的物体有同等贡献,这对小物体的分割性能有一定提升。
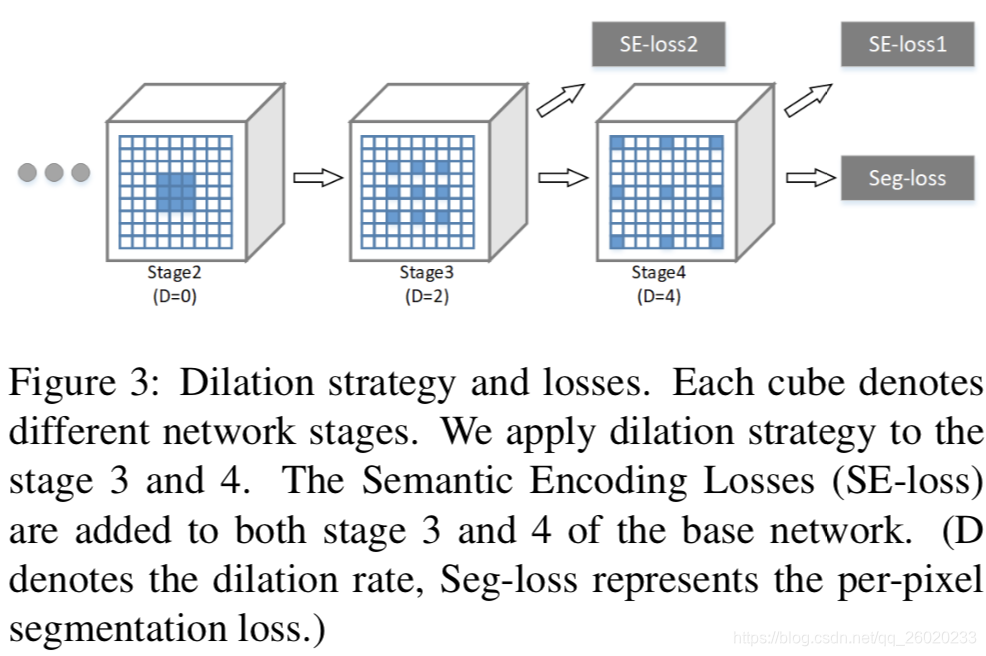
贡献2、提出了新的分割网络结构EncNet
该网络结构主要引入了Context Encoding Module,使用了dilation策略,在PASCAL2012以及COCO-Place Challenge 2017上取得SOA的结果,而且在CIFAR-10分类任务上验证了使用Context Encoding Module能很好地提高浅层Resnet网络的性能。
SyncBN的实现细节
参考阅读
一个工程细节问题,将跨卡BN同步需要两次同步简化为一次同步
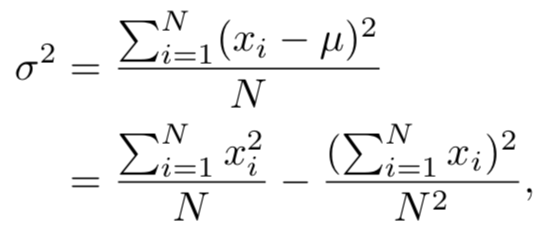
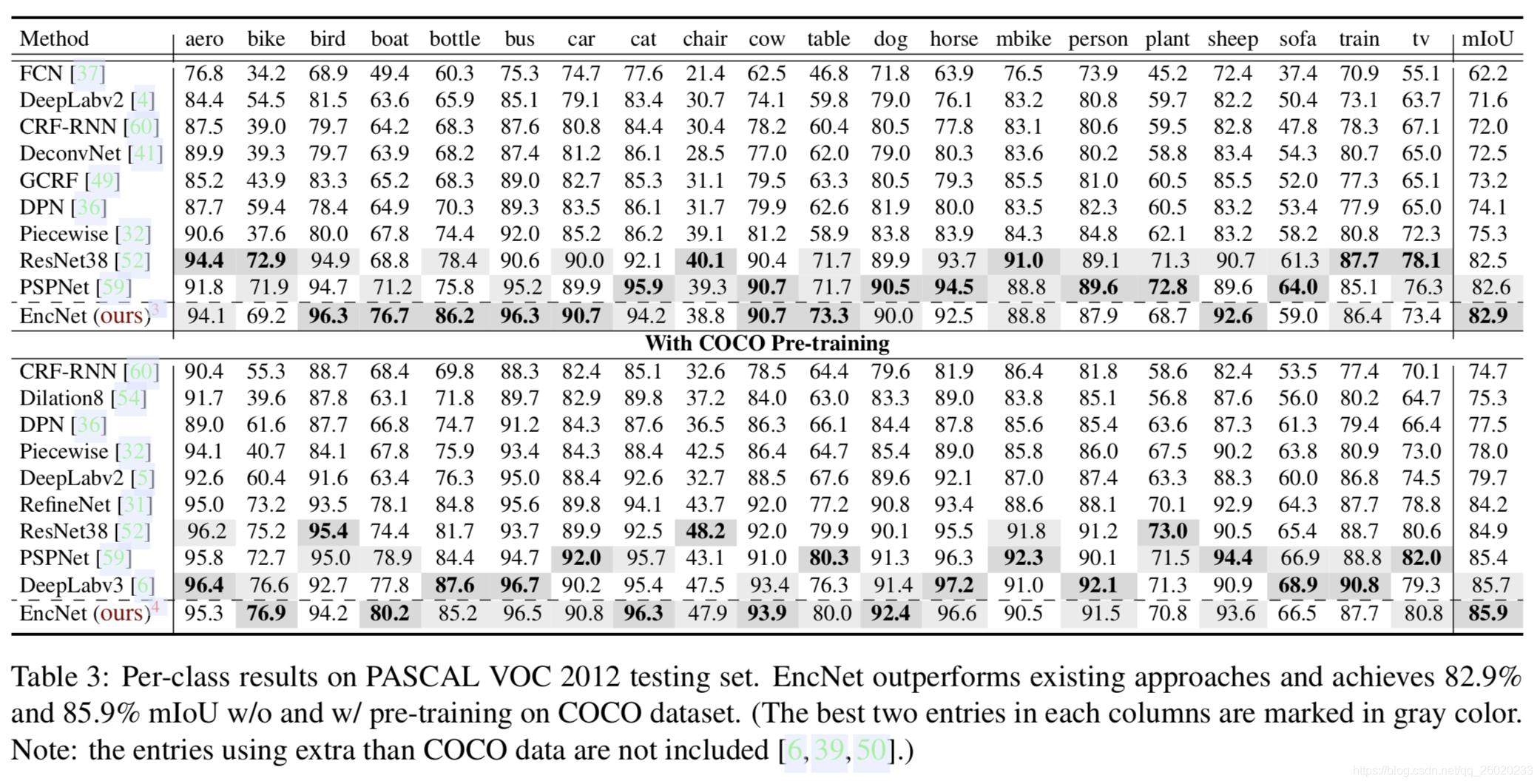
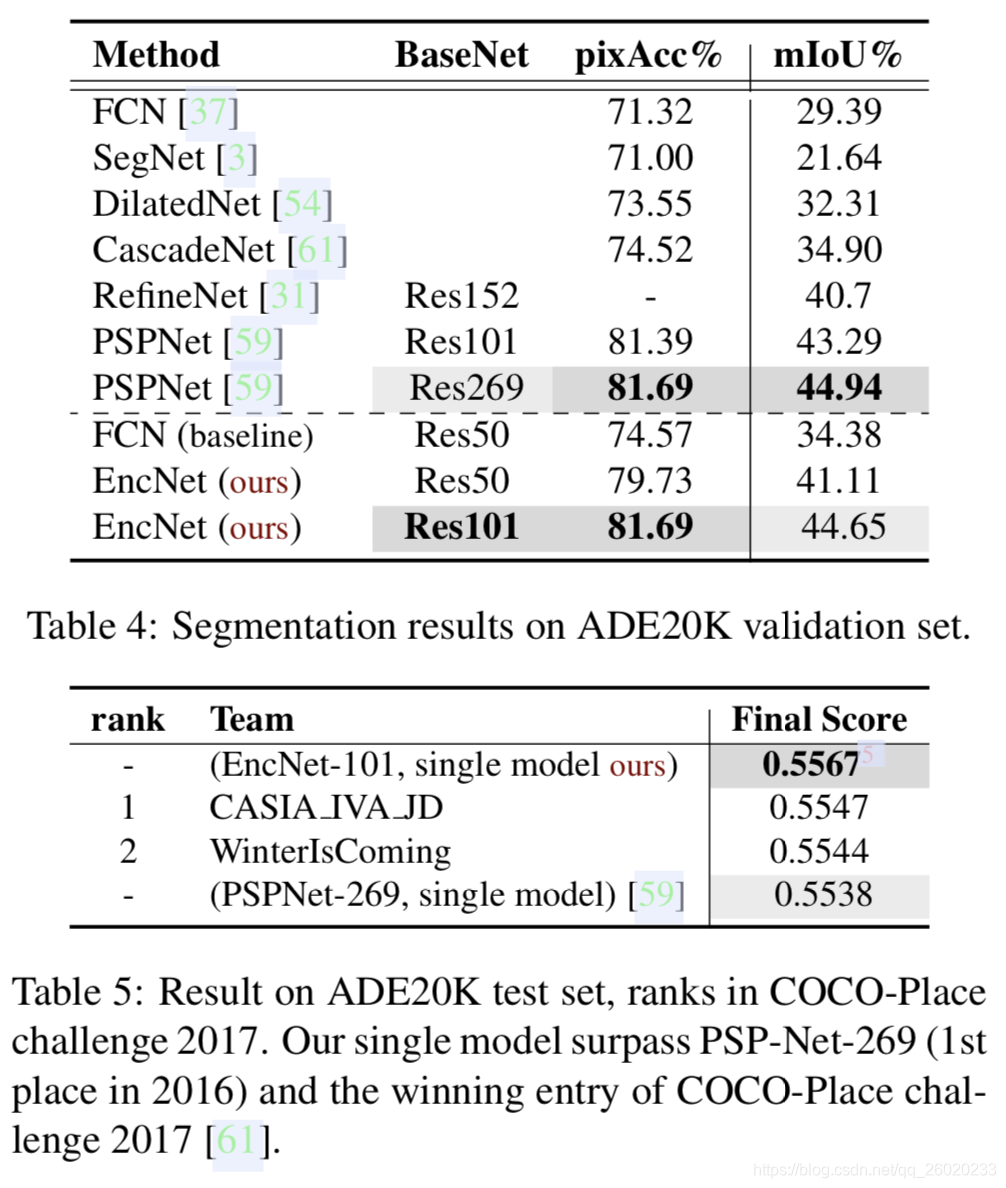
实验结果

源码