Context Prior for Scene Segmentation–CVPR, 2020
文章目录
一、背景介绍
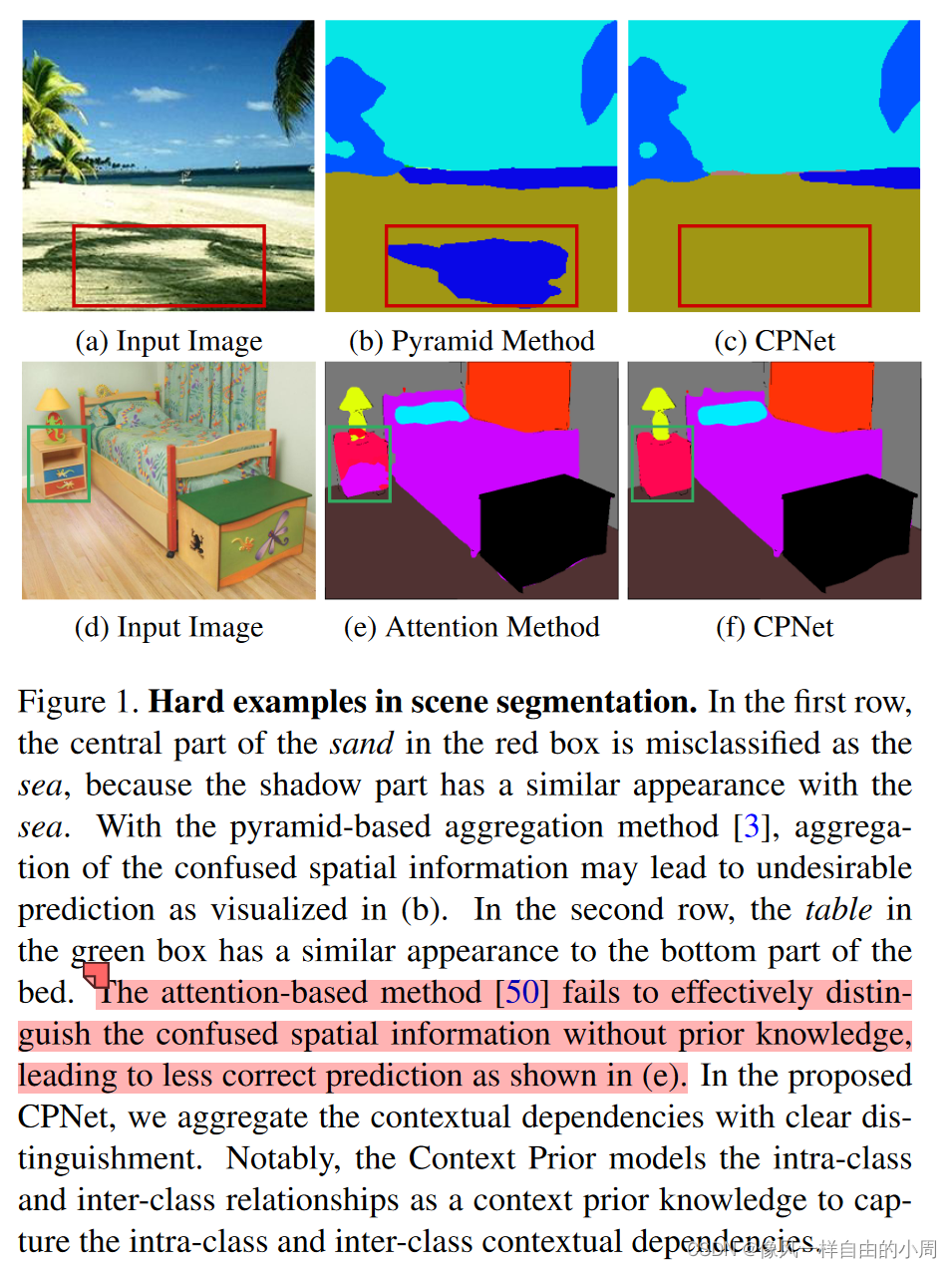
- 问题:现阶段,不少语义分割方法所限于卷积结构,忽略了同类型的上下文之间的关系,但同一类别的相关性(类内上下文)和不同类之间的差异(类间上下文)使得特征表示更加鲁棒并减少可能类别的搜索空间。目前主要有两种改进方式:1.Pyramidbased aggregation method. 这类方法重视类内关系、忽视了类间关系。从而在困难样本上效果较差。2.Attention-based aggregation method. 由于缺乏明确的正则化约束,attention关于类内和类间的关系描述并不是很明确,这会导致选择不需要的上下文关系。
二、方法介绍

我们知道语义分割通常要通过特征提取网络如ResNet、HRNet等获得特征 X X X,然后经过一系列模块如ASPP等以及上采样得到最终的输出结果。有监督学习中,有着标签 L L L。作者这里在获得特征 X X X后,通过自行设计的Context Prior Layer来选择性地捕获类内和类间的上下文依赖,从而实现稳健的特征表示。这里就有一个急需解决的问题就是这个上下文先验也就是类内和类间信息如何获得?作者这里直接使用标签 L L L通过下采样和重构后获得 A (Ideal Affinity Map)来作为监督信息,使得特征通过aggregation、卷积层和Reshape操作得到的 P(Context Prior Map)能够学习到特征的类内和类间的关系。然后为了更好的去进行监督约束,提出了Affinity Loss。好了,下面就涉及三个部分:A的生成、Affinity Loss、如何从 X X X获取P。
1.A的生成

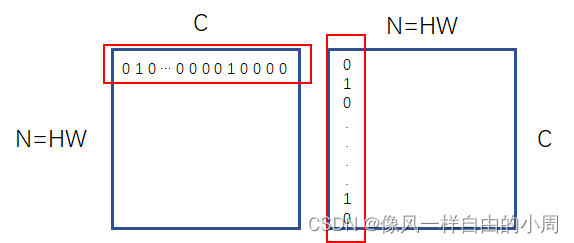
因为特征图 X X X大小 C 0 × H × W C_0 \times H \times W C0×H×W往往比标签L要小,故需要进行下采样操作。作者希望获得的A大小为 N × N , N = H × W N \times N, N=H\times W N×N,N=H×W,A的值仅包含0和1,其中1表示行和列对应的像素点属于同一类,0表示行和列对应的像素点不属于同一类。作者这里先对下采样获得的特征图进行one hot编码,如原来有三类,分别为0, 1, 2就分别变为[1, 0, 0]、[0, 1, 0]、[0, 0, 1]。这里通过one hot编码后就得到了 H × W × C H \times W\times C H×W×C大小的 L ′ L' L′。然后通过 A = L ′ L ′ T A=L'L'^T A=L′L′T就得到了最终的Ideal Affinity Map,这里的 L ′ L' L′先通过reshape操作变成 N × C , N = H × C N\times C,N=H\times C N×C,N=H×C,即变成了一个矩阵。如下图,矩阵 L ′ L' L′的第i行都为第i个像素点的one hot编码,这两个一乘,只有第i个像素和第j个像素属于同一类才能为1,否则为0。这样我们便获得了A。
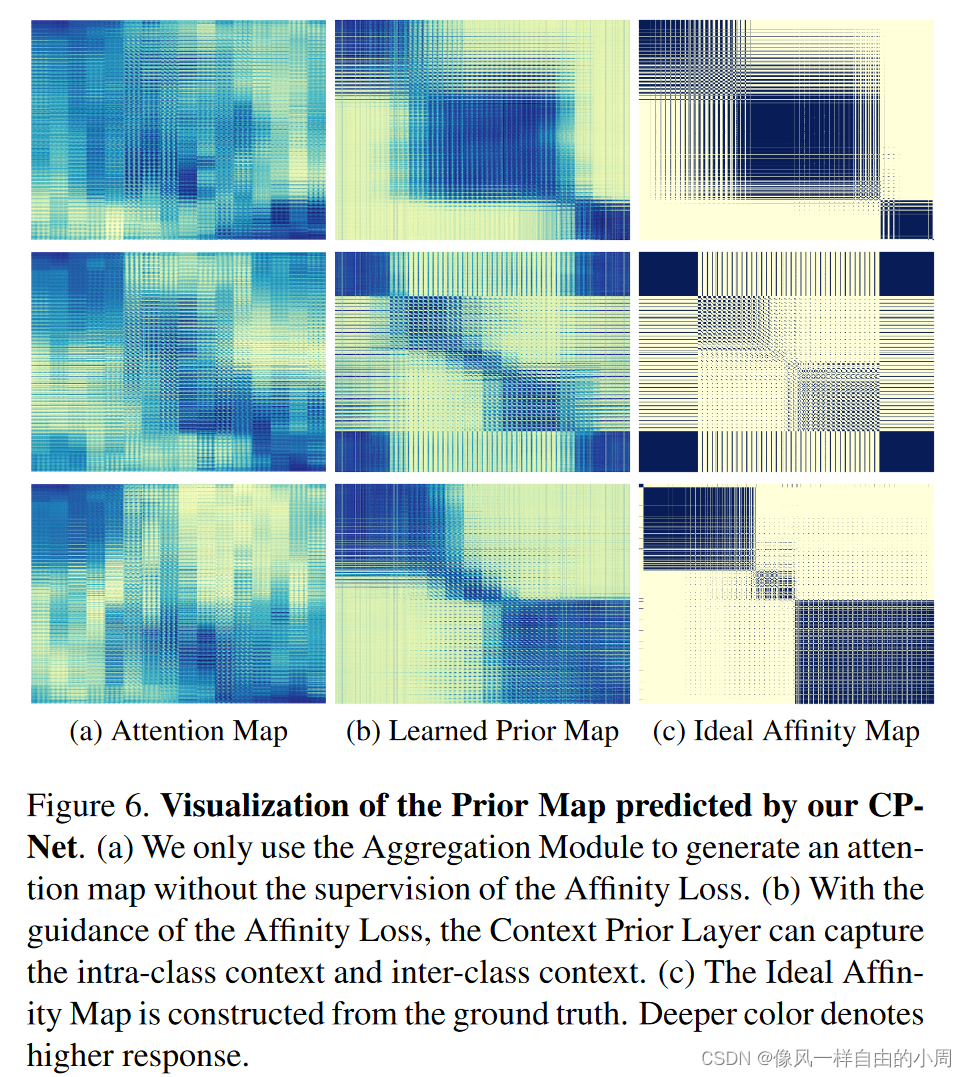
下图为可视化的A和P等
2.Affinity Loss
由于想要使用A来监督生成P,我们将A看为一个2分类的Ground Truth,P为我们获得的概率分布图。那么语义分割常用的监督函数为CE Loss,如下:
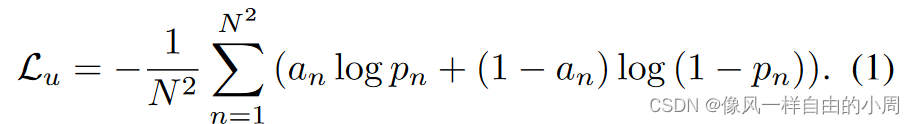
但是,该函数只考虑了先验图中的孤立元素,而忽略了与其它像素的语义相关性。为了解决这个问题,作者依据常用的语义分割指标Precision、Recall等设计出下列损失函数。

结合 L u , L g L_u,L_g Lu,Lg作者便设计出了最终的损失函数: L p = λ u L u + λ g L g L_p=\lambda_u L_u + \lambda_g L_g Lp=λuLu+λgLg。
3.如何从 X X X获取P
通常情况下,我们通过卷积层等就能够获取P。有一个问题需要解决的便是,由于P需要学习到类内和类间的关系,故需要捕获更多的空间关系(即更大的感受野)。这就需要更大的卷积核(这里作者通过实验发现当大小为11时刚好合适,同时通过对比实验发现相较于其它聚合方式如ASPP等要更加优秀),而更大的卷积核则会带来更大的计算量。作者为了减少计算量,使用了深度可分离卷积。设计出Aggregation模块,如下:

好了,我们获得了P,那么这个学习到的P该如何和我们的特征图 X X X进行交互呢?作者这里采用的是直接相乘然后concatenate在一起,最后通过卷积和上采样操作等得到最终的语义分割输出。使用下列损失函数进行约束。其中 L s , L a , L p L_s, L_a, L_p Ls,La,Lp分别表示main segmentation loss, auxiliary loss, and affinity loss functions。这个损失函数中前两个是正常语义分割有的损失,最后一个是作者提出的损失。

下面我们来看一下相乘这个操作,即论文中的


下面我们简单看一下Y这个操作。
4.Y操作
我们已经知道P大小为 N × N , N = H × W N\times N,N=H\times W N×N,N=H×W, X ~ \widetilde{X} X 大小为 C 1 × H × W C_1\times H \times W C1×H×W。我们先将 X ~ \widetilde{X} X 通过reshape操作变成 C 1 × N C_1\times N C1×N大小的矩阵。那么 Y Y Y操作就如下所示。
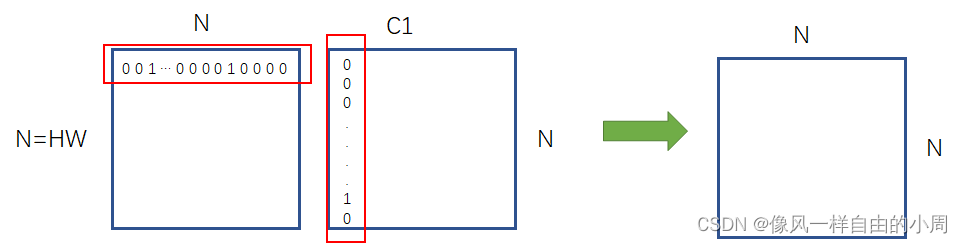
由于P是通过sigmoid函数获得,值在0到1之间,可能为小数。选取第(i,j)点特征值 P i j P_{ij} Pij,可以理解为第i个像素和第j个像素同属于一个类别的概率。这样就有点像attention操作里面的加权求和,只不过这里的权重有着 A A A这个先验约束。这样的加权求和有一种偏向性,使得属于同一类别的特征值放大、不属于同一类别的特征值缩小甚至变成0。