1、Introduction
- 作者提出是不是捕捉语义信息等价于扩大感受野?
- 传统的encoder(BoW,VLAD)可以编码全局特征统计十分方便
- 一个encoding层将字典学习和残差编码都融合到一个网络里面,作者通过扩展encoding层来捕获全局的特征统计
2、contribution
- 第一是设计SEloss,不想pixelwise的损失,SEloss损失对于大目标和小目标施以相同的权重,网络对于小目标是有提升的
- 通过一个编码层,编码整体语义信息,选择class-dependent features,例如降低车辆出现在屋内的概率
- 同步BN,和memory-efficient的编码层
3、
- 首先作者利用编码层来获得特征统计来获得全局的global信息,为了更好地利用全局语义信息,用chanel-wise attention来选择class-dependent的特征图。编码层学习到了一个语义信息的字典,输出具有丰富语义信息的残差编码器
Input feature: CXWXH —>
Inherent codebook:
Scaling factors:
最后会输出k个残差编码,
这样做的目的是什么呢?
通过将图像的HXW个C维特征,每一个都与语义词
做差,然后和所有语义词做差的结果相加进行归一化,获得一个像素位置相对于某个语义词的信息
,然后将这N个结果求和加在一块获得最终的
,获得整张图像相对于第k个语义词的信息。
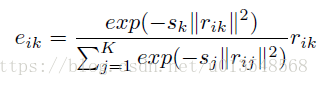
是C维的,最后将k个
融合到一起,这里没有用concat,一方面concat包含了顺序信息,另一方面用加的方法节省了显存。这里加起来的含义是获得整张图像相对于K个语义词的全部信息
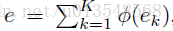
- 然后利用产生的e来产生通道权重,来一个channel-wise的attention
利用e再加一个全连接构成一个SEloss,标签的产生直接看该幅图内有哪些类,对应位置置1
整体网络框架如图
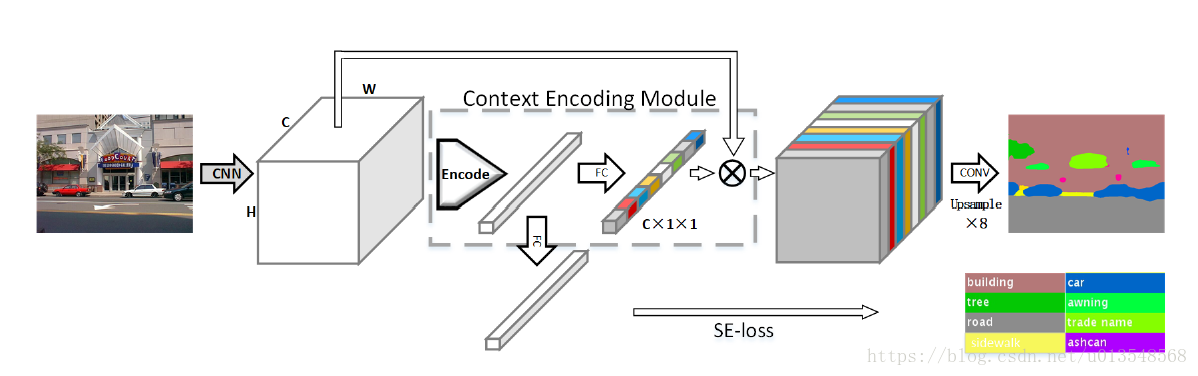
最后作者的k选择的是32
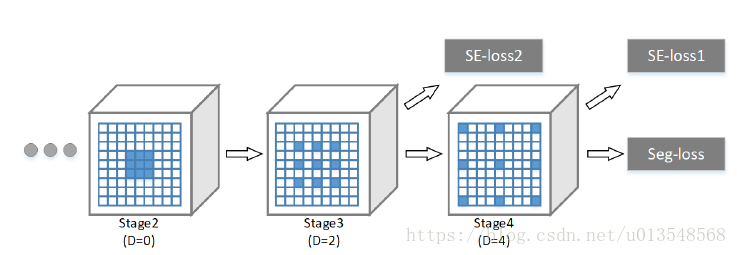
分别在stage 3,4设计了两个SE-loss,同时作者探讨了K的影响,k=0相当于global pooling
4、实验略。