PixelLink: Detecting Scene Text via Instance Segmentation,该文章发表在AAAI2018上,代码地址:https://github.com/ZJULearning/pixel_link
该篇文章灵感来自于图像分割算法和之前CVPR2017的SegLink,看过SegLink和EAST这两篇文章的话,这篇文章其实很容易理解。
在介绍文章思想之前先介绍一下作者做这个工作的想法,作者认为有些方法比如EAST,采用了框的回归又结合了图像分割(EAST中提取到的score map就是分割结构),实际上图像分割已经能给出文本的位置了,没有必要使用框进行回归,所以文章只使用了分割的方法没有采用框回归进行文本定位。但是文字检测不同于图像分割,文字检查要的定位更为的精确,仅仅采用分割的方法不能精确的将距离近的文本很好的定位,所以采用SegLink中link的思想,在预测中不仅预测出哪些像素是否为文本,还要预测出是文本的像素他们之间是否能连接在一起组成一个好的文本框(比如,有两个像素都被检查成文本像素,但是他们是两个文本框的像素,他们之间的link的概率会较小),从而输出更为精确的检查区域。
看懂上面这段思想后,下面内容就很好理解了。大致流程如下图所示
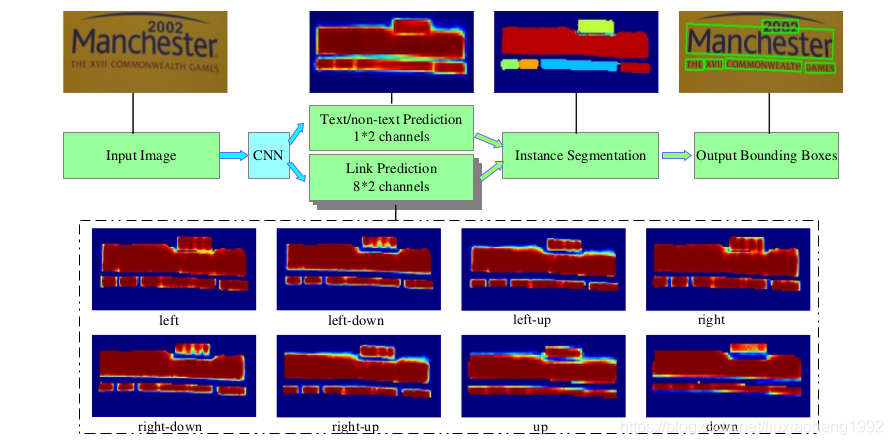
一、网络结构
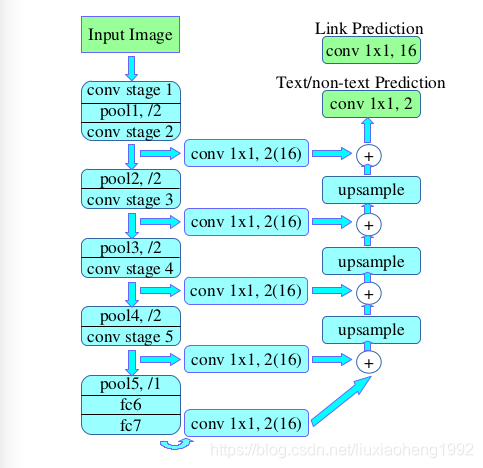
文中网络的backbone采用的是VGG16,并将最后两层全连接层改为卷积层,结构采用的是FCN的结构,文章尝试了两种feature map的融合结构,分别取{conv2_2, conv3_3, conv4_3, conv5_3, fc_7(这里其实是第七层卷积层)}进行融合和取{conv3_3, conv4_3, conv5_3, fc_7(第七层卷积层)}进行融合。输入为图片,输出为18通道的结果,其中2通道表示预测的每个像素是否为文本,16通道表示每个像素与它八个邻域是否需要连接的概率图。
网络结构如下图所示(图中的fc6和fc7为卷积层),图中的加号就是feature map相加。
在得到上述的18个通道后,先是使用了两个阈值分别对像素预测结果和link预测的结果进行过滤,然后对于预测为正样本的像素结合link通道的预测结果将所有像素连接起来(因为两个像素有两个link,这里连接的规则是,如果有一个link达到阈值,则将这两个像素连接起来),这样就能得到文本检测的区域,最后使用OpenCV中的minAreaRect(该函数是输出包围点集的最小矩形,该矩形可以是旋转的)。这样就可以输出一些列的文本框了,但是文章为了防止一些噪声的影响,将检查结果中短边小于10或者面积小于300的文本框进行滤除,从而得到最终的文本检查结果。
二、标签(Ground Truth)的生成
标签的生成比较简单,在文本框里的像素为正样本,如果有文本框重叠的问题,重叠区域为负样本。link的标签也很容易理解,如果两个像素来自同一个文本框那么他们之间的link为正样本,其他为负样本。要注意的是,这里groundtruth的大小不是图像大小,具体大小与网络输出大小有关,也就是和网络的输出为同一大小。
三、损失函数的定义
损失函数定义如下
因为link的结果是基于正样本的pixel来计算的,所以
这里设置为2.0。
像素的损失计算
因为图像中的文字区域有大有小,如果所有像素的权重是一样的,这样做对小的文字不公平,会导致训练结果效果不好。对此不同的文字区域中的像素的权重是不一样的,具体设置方法如下。
假设一张给定的图像中有N个文本框,那么每个文本框的权重都相等且都设为
,
的计算方法如下
其中,对于第i个文本框来说
,那么该框里面每个像素的权重都设为
按照上述规则正样本中的像素权重就可以确定了,而且小文本框权重更大,反之亦然。之后采用Online Hard Example Ming(OHEM)选出的负样本中像素的权重都设为1。
通过上述两个规则就可以得到一个权重矩阵
,下结合这个矩阵就可以计算出
,计算方法如下
其中
是通过交叉熵(Cross-Entropy)损失函数求得像素是否为文本的损失函数矩阵。
连接的损失计算
连接预测的损失是按照link是否为正负样本分开计算的,而且只计算像素为正样本的连接。计算方法如下:
其中,
是对link的交叉熵损失计算矩阵。
和
是link的权重,它们的计算方式如下所示
其中,W就是在像素损失计算中介绍的像素的权重,k表示与像素(i,j)相邻的第k个像素,
表示link的标签值。
最后连接的损失计算如下式所示
其中rsum表示reduce sum。
到这里PixelLink算法基本介绍完了。
欢迎加入OCR交流群:785515057