Adaptive Pyramid Context Network for Semantic Segmentation
简述:
当前基于上下文的分割方法在构造上下文特征和实际应用中各不相同。本文首先介绍了上下文特征在分割任务中的三个理想性质。作者发现全局导向的局部亲和力(GLA)在构建有效的语境特征中起着至关重要的作用,并在此基础上提出了自适应金字塔上下文网络(APCNet)的语义分割方法。
ACPNet构造的主体是设计多个Adaptive Context Module(ACM),每个ACM利用全局图像表示作为指导来估计每个子区域的局部亲和系数,然后使用这些亲和度计算上下文向量。实验结果表明,APCNet达到了最新水平,且在PASCAL VOC 2012测试集上获得了84.2%的新记录。
问题or相关工作:
目前最先进的语义分割方法主要利用深度卷积神经网络(CNNs),但由于CNN的卷积性质,局部卷积特征通常接受域有限,即使接受域很大,这些特征也主要局限于核心区域,而在很大程度上忽略了边界周围的环境。另一方面,来自不同类别的局部区域可能共享附近的特征。精确的语义分割往往需要来自不同尺度和较大区域的上下文信息来消除局部区域造成的歧义。
上下文特征提取已经证明在语义分割任务中有着非常重要的作用。语义分割任务中上下文特征有
以下三个特性:
- Multi-scale:
对象通常具有不同的大小和位置,需要多尺度来捕获图像内容,单尺度捕获对象会造成其他尺度中的细节丢失。 - Adaptive:
有用的信息在包含相关对象的区域产生,而相关区域可能在给定像素附近也可能距离较远,这对输入图像的内容和布局有很大影响。自适应的识别这些重要区域很重要。 - Global-guided Local Affinity (GLA):
要构造有效的上下文向量,可以通过加权的方式总结它们的特性来实现。如何估算聚合的亲和权值是一个问题。这些权值表明了不同的区域如何有助于预测一个低像素的语义标签。之前的模型是利用像素和重区域的局部来估计这些自适应权值。而作者认为局部和全局表示都是评估健壮的亲和权值所必需的。这种表示有助于提升语义分割结果。
对比于18年的DANet、PASNet等,下表可以看出他们包含的特性:

主要工作:
- 总结了上下文向量在语义分割中的三个理想性质,并从这些性质的角度对基于深层上下文的语义分割方法进行了比较。
- 提出了利用GLA特性的自适应上下文模块,利用局部和全局表示来估计局部区域的亲和权值。
- 方法在三个广泛使用的基准上实现了最好的性能,包括PASCAL VOC 2012、PASCAL - context和ADE20K数据集。
模型:
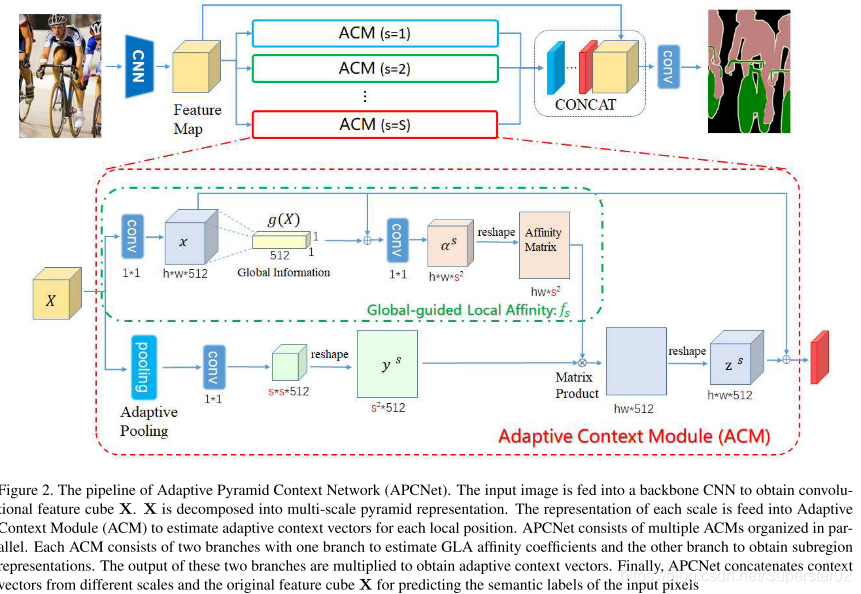
在简述中提到,APCNet的主体结构是对于某一特征图利用并行的多个ACM模块进行处理,将获得的Z^S串联成最终的自适应上下文向量  ,然后利用{Z_i}和局部特征{X_i}来预测每个像素的语义标签。如上图所示,ACM结构主要包含两个分支:其中第一个分支计算affinity coefficients α^s,第二个分支处理single-scale的表征 Y^s.
,然后利用{Z_i}和局部特征{X_i}来预测每个像素的语义标签。如上图所示,ACM结构主要包含两个分支:其中第一个分支计算affinity coefficients α^s,第二个分支处理single-scale的表征 Y^s.
说明如下(不同颜色块表示不同的part):
分支1:
X:X表示经过CNN处理后得到的特征图。通过1×1的卷积后,得到约简后的x。
g(X):利用spital global average pooling(空间全局池化)和1×1的卷积后得到。其为全局特征信息表征。
α^s:利用1×1的conv对于局部特征x_i和全局特征g(x)进行整合,后接一个Sigmod激活函数。(用1×1是因为大的空间卷积,复杂性高,性能较差)
Affinity Matrix:每一个亲和矢量均为s×s维,对于h*w个vector将其整合为一个大小为hw ×S^2。
分支2:
先对输入特征X adative avreage pooling,使用1×1 conv处理得到ss512大小的特征。Reshap成为s^2,便于与第1分支中的结构生成affinity map。
Matrix Prodyct中对两个分支产生的结果进行矩阵乘法运算得到hw∗512大小的结果,然后reshape为Z^S∗512,最后,利用残差连接将最初始的特征x累加到这个结果上。
对于某像素的标签预测问题,对不同的区域、像素分配不同的权重,作者这里给了一个比较抽象的描述:adaptive context vector的计算公式为:
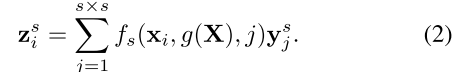
实验:
PASCAL VOC 2012:
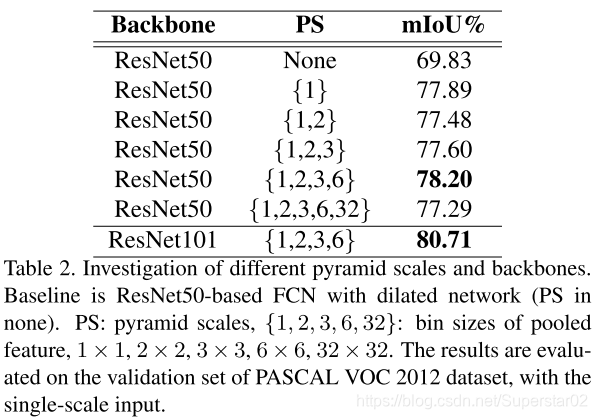
金字塔尺度pyramid scale对模型是有提升的,如下:
APCNet与FCN的对比,可视化结果如下:

进一步说明金字塔量表的有效性,在下图中可视化了不同量表的改进:

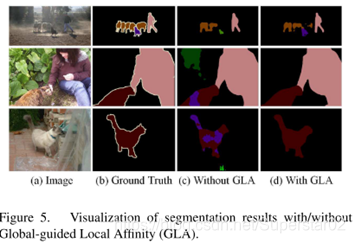
Global-guided Local Affinity (GLA)消融实验:

可视化结果如下:
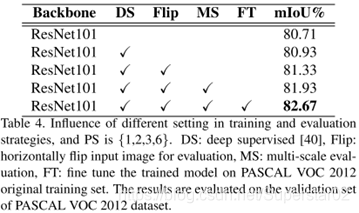
测试了不同的设置对模型的影响,包括Deep supervision、数据增强、多尺度、微调模型,(上面的两张表的输入都是单一输入(没有对一张图进行flip等数据增强处理))从下表可以看出的是微调模型对性能的提升还是比较大的。
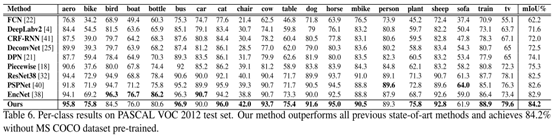
20类目标分割性能:
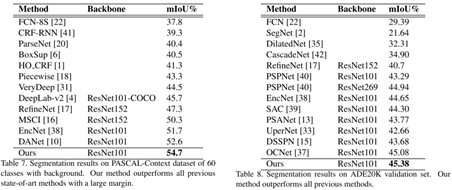
其他模型的分类效果对比:
结论:
本文中,讨论了上下文特征的属性,并提出APCNet自适应地构建用于语义分割和方法骨干场景理解的多尺度上下文表示。 APCNet引入了自适应上下文模块,它通过全局引导的局部亲和生成局部亲和系数。根据属性和灵活性,APCNet可以扩展到其他场景理解任务。
问题:文章提到Adaptive pooling但是没说指的是什么,经查阅网上资料,明白:
自适应池化Adaptive Pooling是PyTorch含有的一种池化层,在PyTorch的中有六种形式:

原理:
自适应池化Adaptive Pooling与标准的Max/AvgPooling区别在于,自适应池化Adaptive Pooling会根据输入的参数来控制输出output_size,而标准的Max/AvgPooling是通过kernel_size,stride与padding来计算output_size。


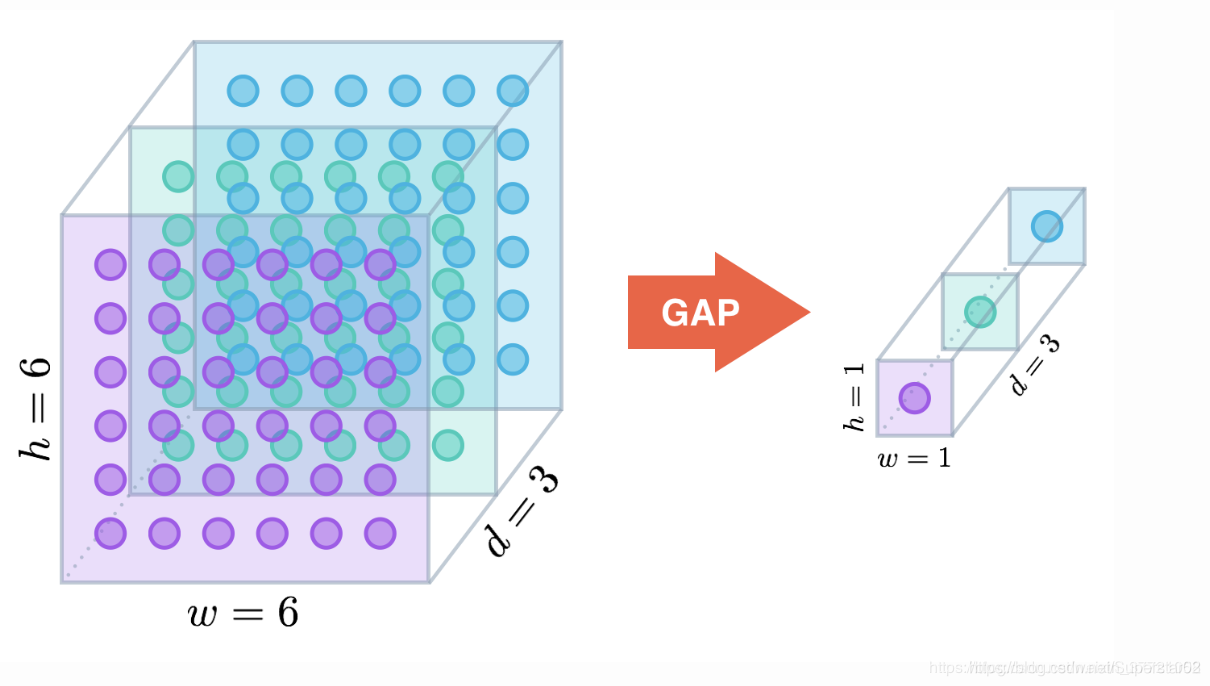
全局平均池化:
用GAP替代FC全连接层。有两个有点:一是GAP在特征图与最终的分类间转换更加简单自然;二是不像FC层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳。更直观的图像来看GAP的工作原理: