版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/PeaceInMind/article/details/79079686
之前的博客也说到了我一直不是很看好回归的方法,因为一般情况下文字识别还是需要精确的边框定位。pixellink在传统的像素二分类的基础上,没有采用回归,而是加了八个方向连接的预测。另外作者还没有用imagenet预训练的vgg,而只用1K数据训练,有点像物体识别的DSOD,直接从头训练,也是一大优势。
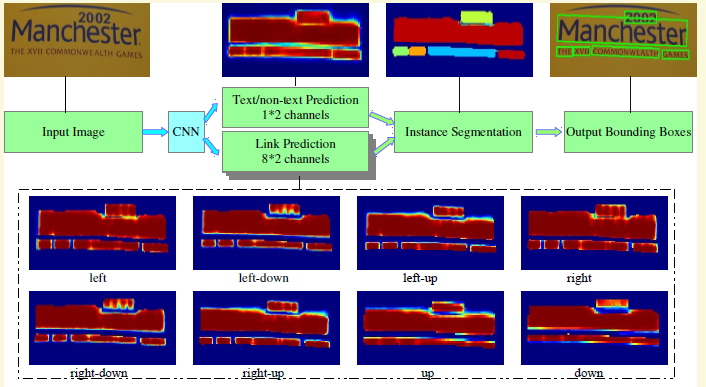
缺点上,首先很明显这是一个Link严重不均衡的任务,虽然作者采用的常用的weight方法,但是不能根治。另外论文认为不要大的感受野是个优点,反而我觉得其中有很大的缺陷, 由于文字像素跟一些树枝栅栏像素很类似,还是很需要上下文信息。 这些因素有可能就是导致有很多false positives的原因,所以作者要采用非常丑陋的后处理. 而且这个后处理对结果影响非常大,有十几个点之多。