Dual Attention Network for Scene Segmentation
CVPR 2019 语义分割(Object Detection)
研究背景
-
问题:
为了有效地完成场景分割的任务,我们需要区分一些混淆的类别,并考虑不同外观的对象。例如,草原与牧场有时候是很难区分的,公路上的车也存在尺度、视角、遮挡与亮度等的变化。因此,像素级识别需要提高特征表示的识别能力。
In order to accomplish the task of scene segmentation effectively, we need to distinguish some confusing categories and take into account objects with different appearance.
-
现有解决:
- 多尺度上下文信息融合 (multi-scale context fusion) : ASPP、PSPNet、LargeKernel etc.
- 通过使用分解结构或在网络顶部引入有效的编码层来增大内核大小,从而获取更丰富的全局上下文信息
- encoder-decoder 结构
问:这样做的缺点是什么?
答:以上方法可以捕获不同尺度的目标,但是它没有利用目标之间的关系,这些对于场景表达也是重要的。- 使用递归神经网络来捕捉长期依赖关系: 例如2D的LSTM。
问:这样做的缺点是什么?
答:有效性在很大程度上依赖于长期记忆的学习结果。
创新点
- 要点: 这篇论文通过基于
Self Attention mechanism来捕获上下文依赖,并提出了Dual Attention Networks (DANet)来自适应地整合局部特征和全局依赖。该方法能够自适应地聚合长期上下文信息,从而提高了场景分割的特征表示。 - 组成: 在一贯的dilated FCN (
Fully Convolutional Networks)中加入两种类型地attention module。其中position attention module选择性地通过所有位置的加权求和聚集每个位置的特征,channel attention module通过所有channle的feature map中的特征选择性地强调某个特征图。最后将两种attention module的output求和得到最后的特征表达。
The position attention module selectively aggregates the features at each position by a weighted sum of the features at all positions. Similar features would be related to each other regardless of their distances. Meanwhile, the channel attention module selectively emphasizes interdependent channel maps by integrating associated features among all channel maps. We sum the outputs of the two attention modules to further improve feature representation which contributes to more precise segmentation results.
- 贡献:
- 提出了
Dual Attention Networks (DANet)在spatial和channle维度来捕获全局特征依赖。 - 提出
position attention module去学习空间特征的相关性,提出channel attention module去建模channle的相关性。 - 在三个数据集Cityscapes, PASCAL Context和COCO Stuff上实现了
state-of-the-art的结果 。
网络结构
总体结构
网络构架如下图:
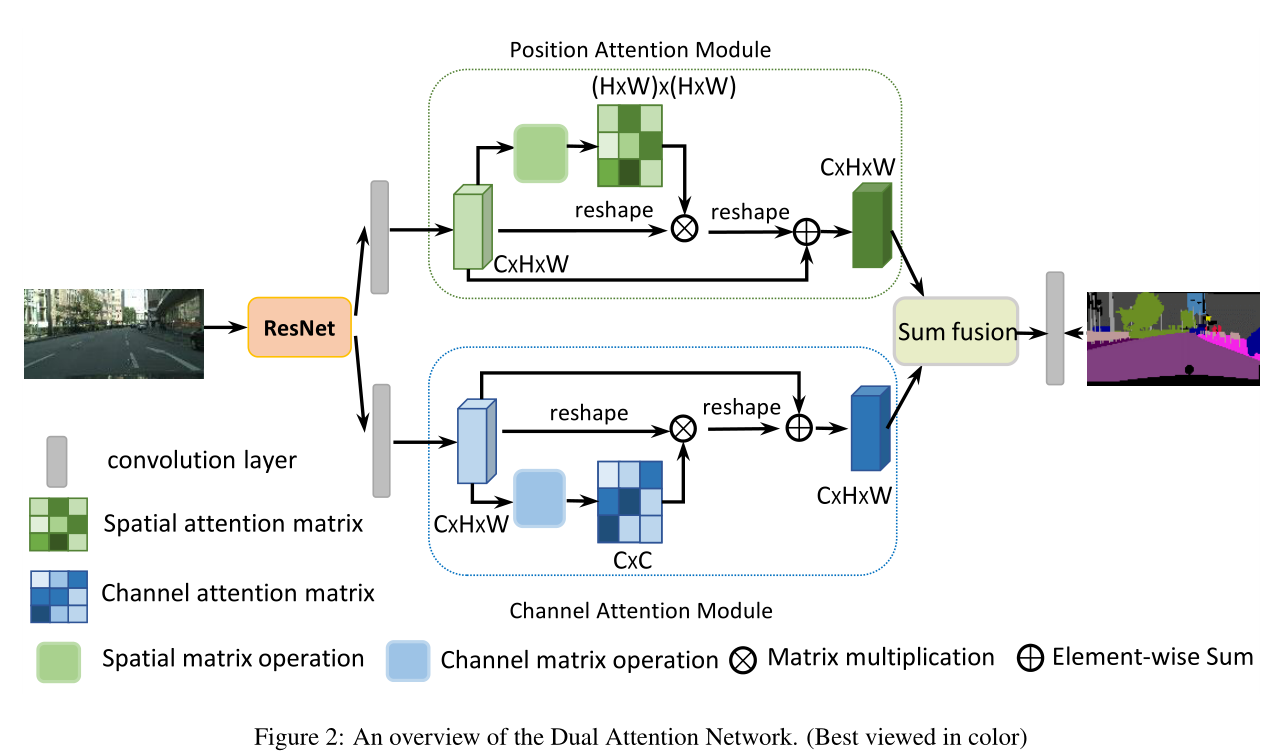
采用移除down-sampling的dilated ResNet(与DeepLab相同)的预训练网络基础网络为,最后得到的feature map大小为输入图像的 1 / 8 1/8 1/8。之后是两个并行的attention module分别捕获spatial和channel的依赖性,最后整合两个attention module的输出得到更好的特征表达。
Position Attention Module
捕获特征图的任意两个位置之间的空间依赖,对于某个特定的特征,被所有位置上的特征加权和更新。权重为相应的两个位置之间的特征相似性。因此,任何两个现有相似特征的位置可以相互贡献提升,而不管它们之间的距离。
The position attention module encodes a wider range of contextual information into local features, thus enhancing their representative capability.
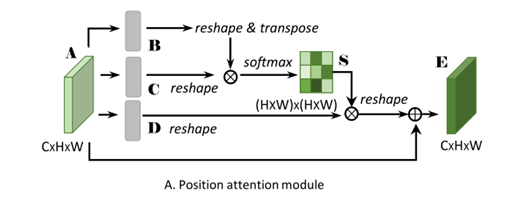
- 特征图 A ∈ R ( C ∗ H ∗ W ) A\in \mathbb R^{(C*H*W)} A∈R(C∗H∗W)首先分别通过3个卷积层(
BN和ReLu)得到3个特征图KaTeX parse error: Got function '\mathbb' with no arguments as argument to '\mathbb' at position 1: \̲m̲a̲t̲h̲b̲b̲{R},然后reshape为 { B , C , D } ∈ R ( C × N ) , N = H × W \{B,C,D\} \in \mathbb R^{(C×N)},N=H×W { B,C,D}∈R(C×N),N=H×W。 - 矩阵 C C C和 B B B的转置相乘,再通过
softmax得到spatial attention mapS ∈ R ( N × N ) S\in \mathbb R^{(N×N)} S∈R(N×N)。 - 矩阵 S S S的转置和矩阵 D D D相乘,
reshape result到 R ( C ∗ H ∗ W ) \mathbb R^{(C*H*W)} R(C∗H∗W)再乘以尺度系数 α \alpha α 再reshape为原来形状,,最后与 A A A相加得到最后的输出 E E E
其中 α \alpha α初始化为0,并逐渐的学习分配到更大的权重。可以看出 E E E的每个位置的值是原始特征每个位置的加权求和得到的。
S S S矩阵的每一个元素为:
s j i = exp ( B i ⋅ C j ) ∑ i = 1 N exp ( B i ⋅ C j ) s_{j i}=\frac{\exp \left(B_{i} \cdot C_{j}\right)}{\sum_{i=1}^{N} \exp \left(B_{i} \cdot C_{j}\right)} sji=∑i=1Nexp(Bi⋅Cj)exp(Bi⋅Cj)
s j i s_{ji} sji测量 i t h i^{th} ithposition对 j t h j^{th} jthposition的影响。

E E E中的每一个元素为:
E j = α ∑ i = 1 N ( s j i D i ) + A j E_{j}=\alpha \sum_{i=1}^{N}\left(s_{j i} D_{i}\right)+A_{j} Ej=αi=1∑N(sjiDi)+Aj

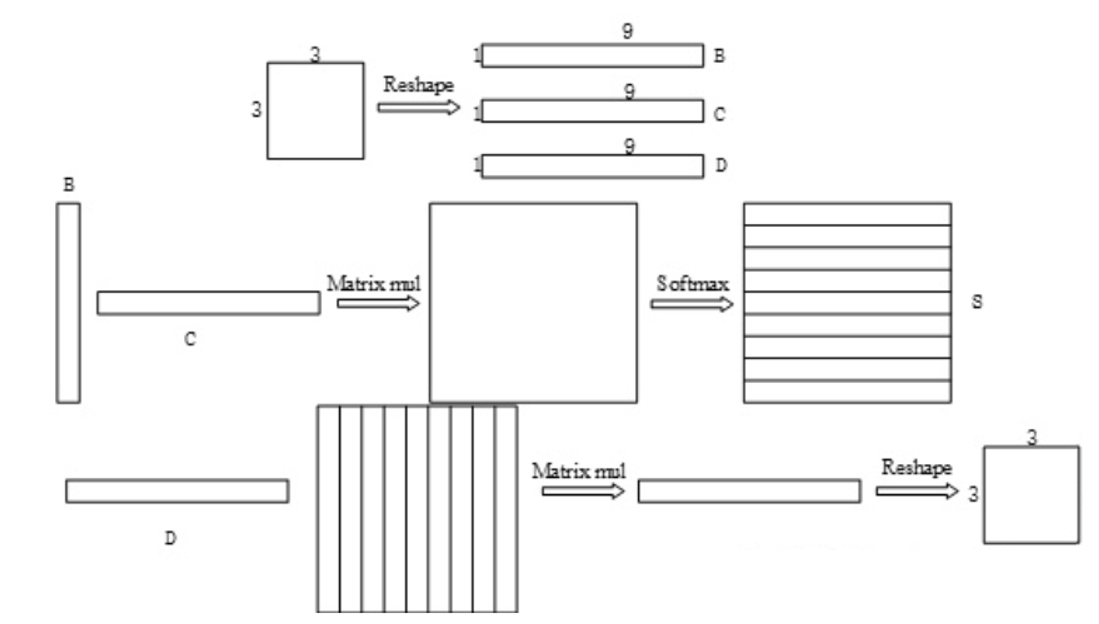
S S S矩阵相当于一个attention,它的每一行计算的是,所有像素与某个像素之间的依赖关系,softmax概率化,softmax值越大,说明更可信,相对的依赖性也更强。
每个位置的结果特征 E E E是所有位置的特征和原始特征的加权和。因此,它有一个全局上下文视图,并根据空间注意力图选择性地聚合上下文。相似的语义特征实现了相互增益,从而提高了类内紧凑性和语义一致性。
Channel Attention Module
每个高层次特征的通道映射都可以看作是一个特定于类的响应,不同的语义响应相互关联。通过探索通道映射之间的相互依赖关系,可以强调相互依赖的特征映射,提高特定语义的特征表示。
By exploiting the interdependencies between channel maps, we could emphasize interdependent feature maps and improve the feature representation of specific semantics.
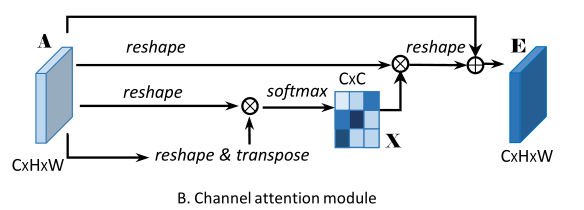
- 在
Channel Attention Module中,最下面两条通路,分别对 A ∈ R ( C ∗ H ∗ W ) A\in \mathbb R^{(C*H*W)} A∈R(C∗H∗W)做reshape成为 R ( C ∗ N ) \mathbb R^{(C*N)} R(C∗N)和reshape与transpose成为 R ( N ∗ C ) \mathbb R^{(N*C)} R(N∗C) - 将得到的两个特征图相乘再通过
softmax得到channel attention mapX ∈ R ( C ∗ C ) X\in \mathbb R^{(C*C)} X∈R(C∗C) - X X X与 A A A做乘积$ \mathbb R^{(CC)} * \mathbb R^{(CN)} 再 乘 以 尺 度 系 数 再乘以尺度系数 再乘以尺度系数\beta 再 ‘ r e s h a p e ‘ 为 原 来 形 状 再`reshape`为原来形状 再‘reshape‘为原来形状\mathbb R^{(CHW)} , 最 后 与 ,最后与 ,最后与A 相 加 得 到 最 后 的 输 出 相加得到最后的输出 相加得到最后的输出E \ in \mathbb R^{CHW}$。
其中β初始化为0,并逐渐的学习分配到更大的权重。
X X X矩阵的每一个元素为:
x j i = exp ( A i ⋅ A j ) ∑ i = 1 C exp ( A i ⋅ A j ) x_{j i}=\frac{\exp \left(A_{i} \cdot A_{j}\right)}{\sum_{i=1}^{C} \exp \left(A_{i} \cdot A_{j}\right)} xji=∑i=1Cexp(Ai⋅Aj)exp(Ai⋅Aj)
其中 x j i x_{ji} xji测量了 i t h i^{th} ithchannel对 j t h j^{th} jth channel的影响。

EE中的每一个元素为:
E j = β ∑ i = 1 C ( x j i A i ) + A j E_{j}=\beta \sum_{i=1}^{C}\left(x_{j i} A_{i}\right)+A_{j} Ej=βi=1∑C(xjiAi)+Aj
每个通道的最终特征是
所有通道的特征和原始特征的加权和,这模拟了特征映射之间的长期语义依赖性。这有助于提高特征的可辨别性。

Attention Module Embedding with Networks
- 两个attention module的输出先求和再做一次卷积得到最后的预测特征图。
Specifically, we transform the outputs of two attention modules by a convolution layer and perform an element-wise sum to accomplish feature fusion. At last a convolution layer is followed to generate the final prediction map.
- 没有采用级联的操作,因为这样需要更多的GPU,本文的
attention modules非常简单,可以直接插入到先用的FCN中,显著地提高了效果且不增加非常多的参数。
We do not adopt cascading operation because it needs more GPU memory. Noted that our attention modules are simple and can be directly inserted in the existing FCN pipeline.
数据集:
The dataset has 5,000 images captured from 50 different cities. Each image has 2048 × 1024 pixels, which have high quality pixel-level labels of 19 semantic classes. There are 2,979 images in training set, 500 images in validation set and 1,525 images in test set.
The dataset has 10,582 images for training , 1,449 images for validation and 1,456 images for testing, which involves 20 foreground object classes and one background class.
he dataset provides detailed semantic labels for whole scenes, which contains 4,998 images for training and 5,105 images for testing. In our paper,we evaluate the method on the most frequent 59 classes along with one background category (60 classes in total).
训练过程:
- poly学习率策略:每个epoch后,学习率乘以 ( 1 − i t e r t o t a l i t e r ) 0.9 ( 1 − t o t a l i t e r i t e r ) 0.9 (1-\frac{iter}{totaliter})^{0.9}(1−totaliteriter)0.9 (1−totaliteriter)0.9(1−totaliteriter)0.9;
- 初始学习率为 0.01 0.01 0.01、 0.9 0.9 0.9动量、 0.0001 0.0001 0.0001权重衰减;
- 对于CityScape, batchsize=8,其它为16
- 随机crop、水平翻转;
实验结果
Ablation Study for Attention Modules
消融实验比较两个分支分别的作用和两个分支都有的时候的效果

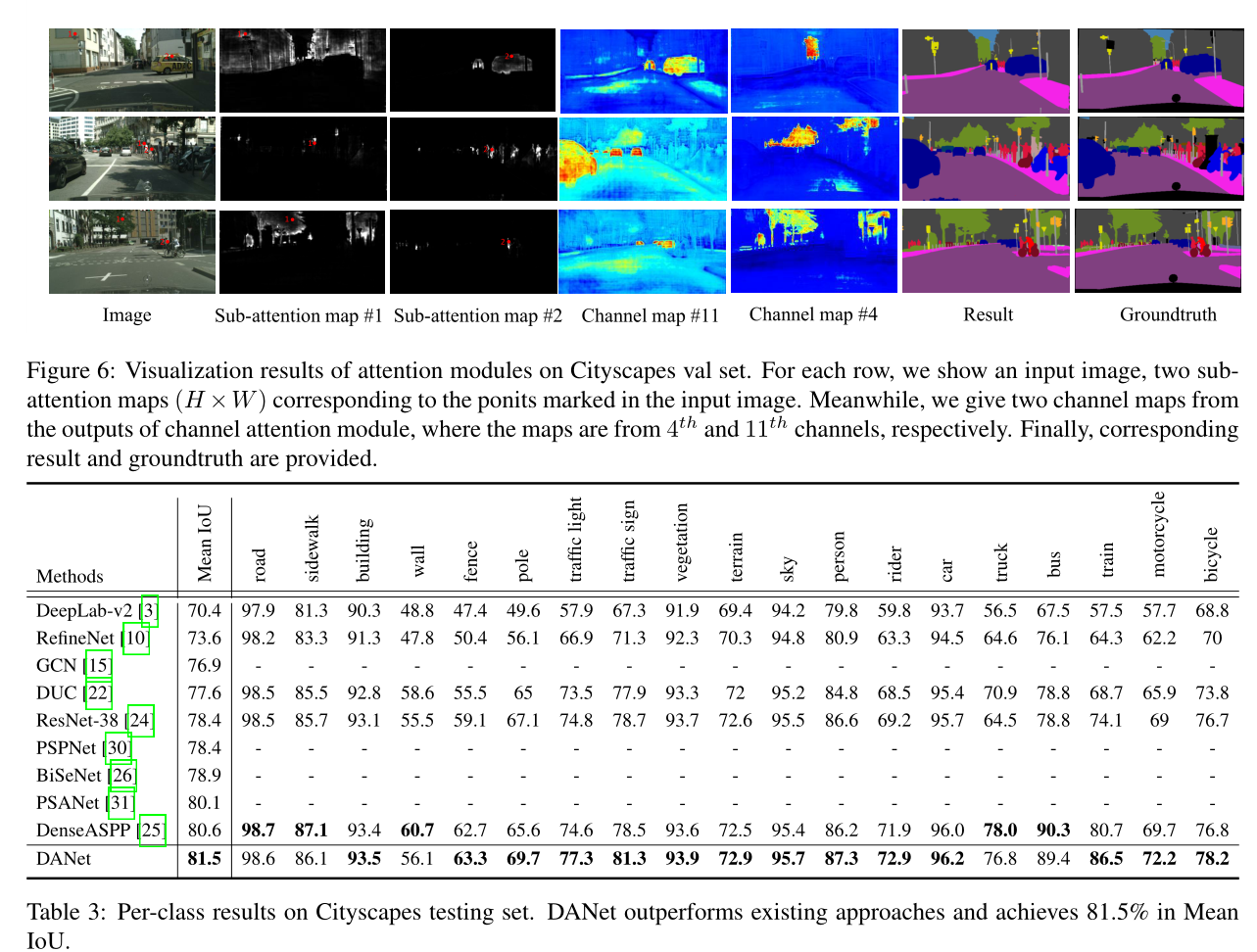
位置注意力模块的效果在图4中可视化, 一些细节和对象边界在使用位置注意力模块时更加清晰, 例如第一行中的 “杆子” 和第三行的 “人行道”。对局部特征的选择性融合增强了对细节的区分。

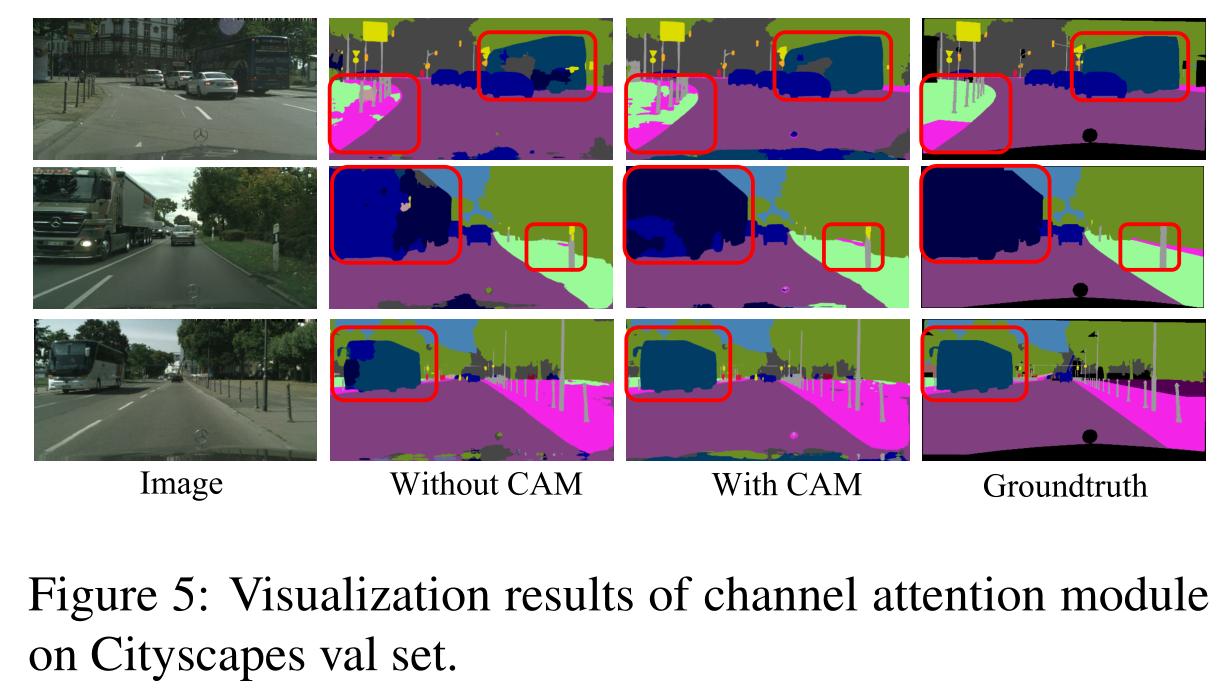
同时, 图5证明, 利用我们的信道注意模块, 一些错误分类的类别现在被正确地分类, 如第一行和第三行中的 “公交车”。 通道映射之间的选择性集成有助于捕获上下文信息。 语义一致性得到了明显的改善。
Ablation Study for Improvement Strategies
训练方法等trick所带来的的效果消融实验

提升策略:
DA: 随机缩放
Multi-Grid: 在最后一个ResNet块中应用了不同大小的网格层次结构(4,8,16)
MS:多尺度测试 {0.5 0.75 1 1.25 1.5 1.75 2 2.2}
(1) DA: Data augmentation with random scaling.
(2) Multi-Grid: we apply employ a hierarchy of grids of different sizes (4,8,16) in the last ResNet block.
(3)MS: We average the segmentation probability maps from 8 image scales{0.5 0.75 1 1.25 1.5 1.75 2 2.2} for inference.
Visualization and Comparing with State-of-the-art
与其他的工作比较:可视化地对比注意力 和其他性能数据分析
结论与思考
作者结论
提出了一种用于场景分割的双注意网络(DANet),该网络利用自注意机制自适应地融合局部语义特征。同时,作者引入了Position attention module 和 Channel attention module 去捕获空间和通道维度上的全局依赖关系。
记录该工作的亮点,以及可以改进的地方
DANet在Cityscapes,Pascal VOC2012, Pascal Context和COCO Stuff上取得了杰出的成绩,在未来,作者希望在减少计算复杂度,提高模型的鲁棒性方面有相应的研究。
参考文献:
论文地址:Dual Attention Network for Scene Segmentation
Dual Attention Network for Scene Segmentation - 知乎
语义分割之Dual Attention Network for Scene Segmentation - Hebye - 博客园
Dual Attention Network for Scene Segmentation 论文笔记 - 程序员大本营
论文阅读-Dual Attention Network for Scene Segmentation - 知乎
论文阅读 - Dual Attention Network for Scene Segmentation
针对本篇论文的演讲PPT(很不错):Dual Attention Network for Scene Segmentation讲解_mieleizhi0522的博客-CSDN博客