一,DANet(双注意力模型)
网络结构:
网络有两个注意力分支,一个是位置注意力模型(PAM),另一个是通道注意力模型(CAM):

位置注意力模型(PAM):
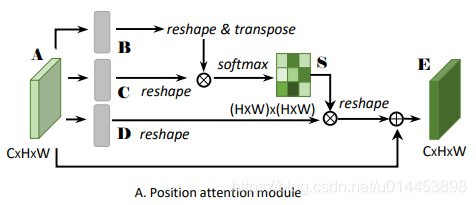
A是通过Resnet网络提起的特征图,维度是CxHxW。把A送入一个卷积层,得到特征图B和C,B和C的维度也是CxHxW。然后把B和C的维度reshape成CxN,(N=HxW)即N是特征图的像素个数。然后再把B进行矩阵转置,维度就 变成NxC。然后B和C进行矩阵乘法,得到一个NxN的注意力矩阵,其再通过softmax处理,就变成了S,S的维度也是NxN。
S的元素计算如下:

Sji 表示第i个像素对第j个像素的影响。两个像素越相近,他们的Sji值越大。
然后,再把A输入到一个卷积层,输出特征图D,D的维度是CxHxW,并把特征图D的维度reshape为CxN,然后再把D和S的转置矩阵(并reshape成CxHxW) 作矩阵乘法,最后乘上一个参数,和A加起来,得到最后的输出矩阵E,E的维度为CxHxW。
E的元素计算如下:
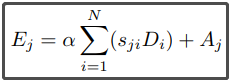
通道注意力模型 (CAM):
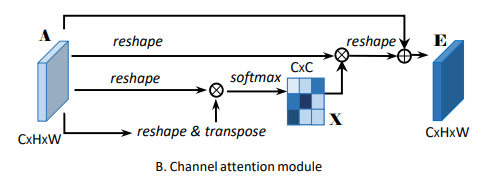
与PAM的计算不同的是,CAM是直接计算注意力矩阵X的。先把特征图A的维度reshape为CxN(N=HxW),然后再把A和A的转置矩阵进行矩阵乘法运算,再经过softmax层,就得到了注意力矩阵X了,X的维度为CxC,X的元素 计算如下:
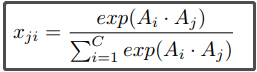
Xji 表示第i个通道对第j个通道的影响。
然后我们再把 X的转置矩阵与A做矩阵乘法,得到的矩阵的维度为CxR,再reshape成CxHxW,最后该矩阵乘上一个参数,再与A矩阵相加,就得到了最终的输出E矩阵,E的维度为CxHxW。E的元素计算如下:
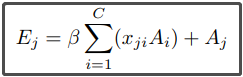
二,代码链接:
https://github.com/Andy-zhujunwen/danet-pytorch
三,效果:

