Abstract:
Long-range 上下文信息对语义分割的性能是十分重要的。早先 re-weighting 的方法是使用 global context 来 re-weight 通道来提升准确率。但是,全局共享的特征向量对于输入图像中不同类的区域可能不是最优的。
本文,我们提出了一个 Context-adaptive Convolution Network(CaC-Net) 去预测语义分割特征图中每一个空间位置的spatially-varying feature weighting vector(空间变化的特征加权向量)。CaC-Net中根据全局上下文信息来预测 context-adaptive conv。当conv与特征图卷积时,预测conv能够生成spatially-varying feature weighting vector 同时捕获 全局和局部 上下文信息。
Introduction:
同一类对象的尺寸变化显著,不同类对象的外观相似,这给语义分割带来了很大挑战。
为了处理这些问题:探索long-range contextual information …一个是聚合不同区域位置的 loacl context,一种是global contextual 信息加权通道,特征权重能够自动地突出与给定场景相关的特征,抑制不相关的特征。例如:船通常出现在海里而不是门里。在水场景的相关背景下,水相关特征通道权重提高,以增加船像素预测的几率(SENEt)(关于通道注意力的解析,新奇)但是所有的空间位置共享一个权重,实际上,水场景中天空和水的区域权重应该是不同的。

Method:
全局上下文信息的通道权重存在问题,2D特征图的所有空间位置都共享一个权重向量。CaC-Net 采用 global context ,但是spatially-varying feature weighting vector(空间变化的特征加权向量)能够捕获不同位置的独特特征,从而提升性能。 采用带有空洞卷积的ResNet作为分割的主干网络,在最后两个block移除下采样,空洞率设为2,4.得到输入的 1/8 尺寸。
采用带有空洞卷积的ResNet作为分割的主干网络,在最后两个block移除下采样,空洞率设为2,4.得到输入的 1/8 尺寸。
CaC Kernel Prediction:Tk,Tq采用1*1conv实现
key feature:来捕获 输入X的c的通道的c 个不同特征
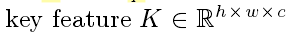
Query feature:来捕获K的全局空间(每个元素的)分布
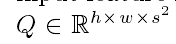
得到Tk 和 Tq之后,需要进行reshape到二维:
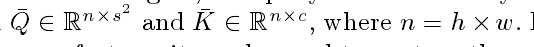
然后在做矩阵相乘:

再将结果 reshape 到三维:sxsxc 作为我们的 CaC 核。
Weighting Factor Generation:
以depth-wise conv的方式 带有空洞率为1,3,5。。D 的每一个通道可以用于调节输入特征图的一个通道
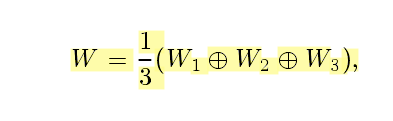
最终:采用与输入进行点乘。
上采样部分采用双线性插值
实验中:采用辅助loss 在 Res-4之后
消融实验:发现 CaCnet 中,有 两个 CaC 模块效果最好,并且两个模块卷积核size为 3+3 最好
