公式输入请参考: 在线Latex公式
概述
前一节已经讲了Transformer模型的attention机制。并且提出了时序类模型(RNN/LSTM)的缺点,然后这节来看看解决这些个问题的Transformer。
之前paper带读也有一些笔记,估计没这里通俗易懂,就当做二刷吧。
理解Transformer就是要弄清楚下面三个问题:
· How does Transformer implement long-term dependency?(i.e., to replace LSTM time dependency)
· How does self-attention, encoder-decoder attention, decoder attention differs?
· How does Transformer encodes diferent ordering of words
先贴下原文的图:

里面每个模块的结构:

可以看到,整个大模型和RNN/LSTM时序模型不一样,句子向量是直接一起输入的,然后可以并行计算,而且它是纵向上的深度模型。
Encoder模块
Transformer模型包含Encoder和decoder两个大模块,
每个Encoder和decoder大模块各自又有很多layer,每个Encoder和decoder的layer有自己的block。
Encoder的block如下图(虚线部分是残差连接):

对应的代码也是两个部分:自注意力和前向传播层(主要负责非线性变换)

MultiHeadAttention
代码中用的MultiHeadAttention不是Self-Attention
实际上很好理解,上节中讨论的一个单词转换为特征向量(上图中的绿色部分)后,输入Self-Attention,这里如果和一套QKV进行计算,得到一个结果,如果和多套QKV计算,就得到多个结果,然后把结果concat后降维,这个过程就是多头注意力,这里的多头表现在多套QKV来进行计算。
注意:单词之间计算score采用的是一个mask来实现的,这个mask和Decoder中的attention使用的mask不一样。

下面就是一个单词用了8个头的自注意力,得到8个z,然后concat后和权重矩阵进行降维,得到最后的Z就是包含了所有多头注意力的结果的向量。这里Z的维度是和原来的输入维度一样。

Add & Normalize
下面看模块中的另外一个部分。
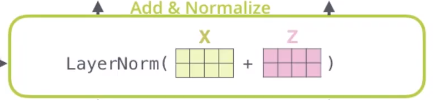
对应代码:

注意代码中有对应的残差。
Decoder模块
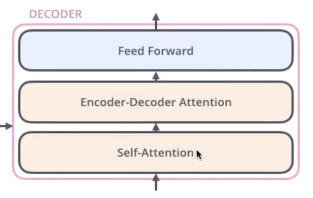
从结构上看可以重用Encoder端的自注意力和FF模块。

从代码上看,Encoder-Decoder Attention用的框架和Self-Attention是一样的。实际上Self-Attention是针对句子内部各个单词之间的关系,Encoder-Decoder Attention是针对Encoder和Decoder之间的关系。
dec_outputs,dec_self_attn=self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs,dec_enc_attn=self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
从代码中看到Self-Attention的输入都是dec_inputs, dec_inputs, dec_inputs
Encoder-Decoder Attention的输入是:dec_outputs, enc_outputs, enc_outputs
相当于找到当前Decoder的输出与Encoder的各个输出之间的关系。例如,输入9个单词,经过Encoder得到输出:9个Z,然后用Decoder和这九个Z分别两两进行QKV的attention操作
位置信息
关于位置信息是用位置向量与词向量进行相加(不是点乘也不是concat)来处理的。

