文章目录
Distributed Representation
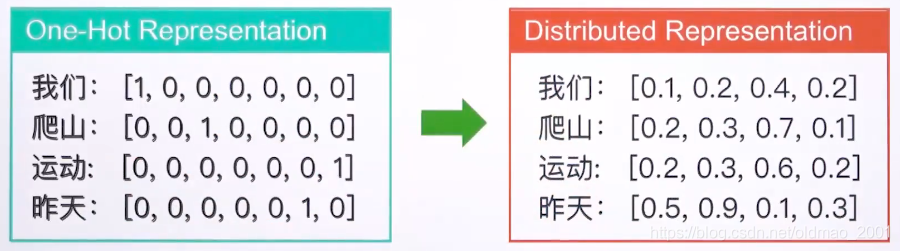
分布式表示法不依赖于词典,向量里面都是非零的数据,解决了one-hot向量表示的稀疏性和向量长度过大的问题。one-hot向量维度要和词典一样,而分布式表示法维度通常小于300。
先来看看上面的分布式表示法再来计算相似度。
欧式距离:
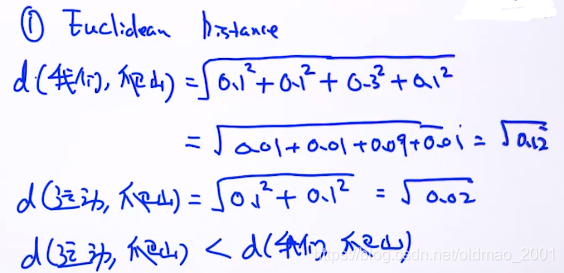
因此可以得到结论是:
sim(运动,爬山)>sim(我们,爬山)
这个是符合我们的预期的。
我们把这种分布式表示方法称为词向量(word vector),当然词向量有很多种表示方式,分布式表示是其中一种。
思考:
Q:100维的One-Hot 表示法最多可以表达多少个不同的单词?
答:100的阶乘。
Q:100维的分布式表示法最多可以表达多少个不同的单词?
答:正无穷多个。
了解完概率之后,下面来看看怎么学习每一个单词的分布式表示(词向量)。
Learn Word Embeddings
输入:string,当有多个文章或者句子,可以把他们直接做拼接,连成长字符串。长度一般在
左右。
然后丢到模型里面,常用的词向量训练模型可以有:

MF是矩阵分解,最后那个是高斯嵌入?
最后是生成分布表示的函数,写做:
,其中dim代表训练出来的词向量的维度,可以是100/200/300等,相当于超参数。其他的参数不同的模型又有所不同,具体在学习每个模型的时候再讲解。
由于输入的数据比较大,通常我们都是用大公司训练好的结果。我们只需要输入词语(key value)然后得到词向量结果
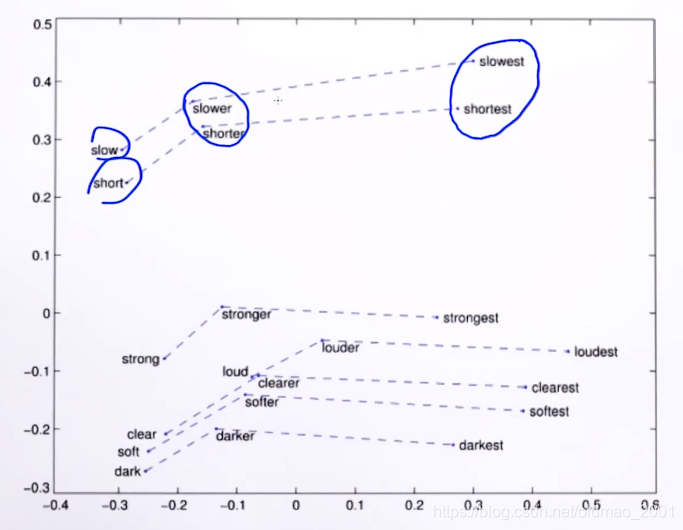
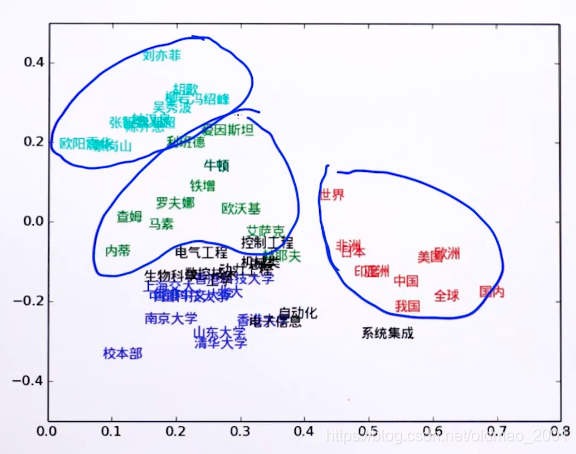
词向量可视化
这个很多论文里面有,随便贴一点
From Word Embedding to Sentence Embedding
有很多种方法,这里讲一种平均的方法。
平均法 average

以上计算结果就是:我们去运动这个句子的句向量。
