公式输入请参考: 在线Latex公式
·归并排序以及Master Theorem
归并排序直接看数据结构了解什么意思,后面的主定理Master Theorem是专门用来算递归算法的复杂度的方法,具体看这里:
Master—Theorem 主定理的证明和使用
我就偷懒不写公式了。
总之,主定理里面三个条件算出来的,谁大就要谁作为时间复杂度标准,相等就随意取一个。
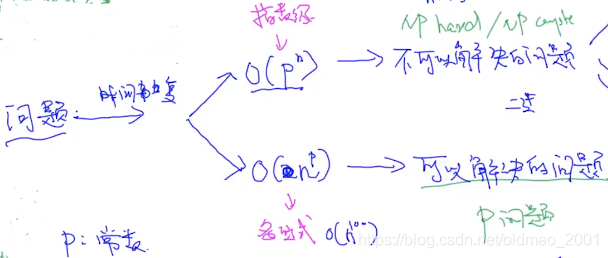
·P,NP,NP hard,NP complete 问题
https://blog.csdn.net/databatman/article/details/49304295
补充一点点:
·斐波那契数的计算
序列依次为1,1,2,3,5,8,13,21,…
问题:怎么求出序列中第N个数?
def fib(n):
# base case
if n<3:
return 1
return fib(n-2)+fib(n-1)
print (fib(30))|
时间复杂度
这个算法不适合使用主定理来解算法复杂度。可以用画图的方式来看看
条件是:
求f(8)
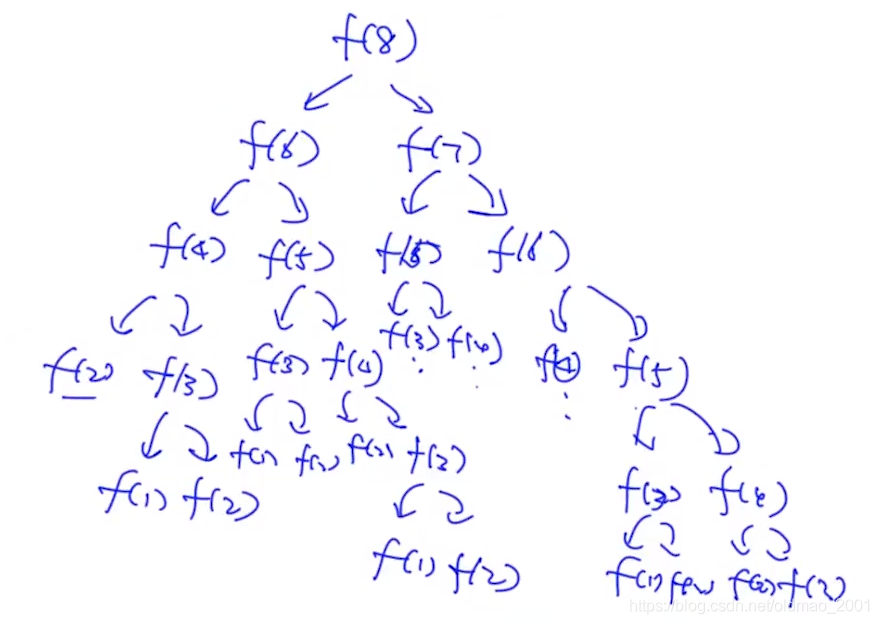
第一层要一个加法(f(6)+f(7)),第二层要两次,依次下去是
注意算f(n),那么树有n-2层,因为有两层是已知的。但是复杂度来说常数项可以忽略,所以复杂度就是
空间复杂度
递归调用的空间复杂度涉及到栈内存,后进先出,调用函数要逐个入栈,如果计算f(8)其实只用8个内存空间。
·递归实现与循环实现
从上面的代码和图可以看出来,使用递归来解决斐波那契数列很简便,代码也不用写很多,但是这个过程画成图了以后我们发现,其中一些计算重复了很多次,例如f(4)在计算f(5)的时候用了一次,在计算f(6)的时候用了两次,每次都重复计算,所以很慢。如果能只计算一次,那么就会大大加快计算的速度。
如果递归的计算n=50,普通机器里面死机。。
这种复用的计算方式就叫动态规划DP。原理就是维护一个二维数组,把计算的结果保存到数组中,避免重复计算。
import numpy as np
def fib(n):
tmp=np.zeros(n)
tmp[0]=temp[1]=1
for i in range(2,n):
tmp[il=tmp[i-2]+tmp[i-1]
return tmp[n-1]
def fib(n):
a,b=1,1
C=0
for i in range(2,n):
c=a+b
a=bb=a
return c
以上两个算法的结果都一样,不过第一个空间复杂度要高一点,它数组要长一些
思考题:怎么在
的时间复杂度下计算斐波那契数?
套公式
思考题:这个公式怎么得来的?
提示:转换成矩阵的连乘的形式,矩阵连乘可以简化(MATRIX DECOMPOSION)
·问答系统介绍
先要有语料库(Knowledge base)
例如
1.本课程是线上课程还是线下课程?
回答:线上课程为主
2.课程有助教吗
回答:每门课程都配备专业助教
3.学习周期是多久啊?
回答:通常来讲在3-4个月不等
4.如果不满意可以退款吗?回答:前两周提供无条件退款
5.老师都是什么背景啊?
回答:绝大部分都是全美前10学校的博士
6.课程会有考试吗
回答:有的。一般包括期中和期末
7.我只有编程基础,可以报名吗
回答:对于初级的项目班只要求编程基础
8.课程有实操吗
回答:大部分都是实操,动手能力是最重要的
9.课程为什么贵?
回答:跟别的知识付费不一样,我们会提供很多教学服务,辅助完成学员做完所有的项目
10.课程学完了能做什么?
回答:可以找相关岗位的工作问题不大
11.课程多久开一次啊?
回答:我们每个月开一期,但价格通常会不断升高
当用户输入问题:我想了解老师的背景
然后用这个问题去匹配语料库中的问题,看和哪个问题的相似度最大,机器就用那个问题来回答用户提问
相似度计算两个思路:
1、正则,这个方法是没有语料库的时候用,就是定义规则。
2、字符串相似度计算

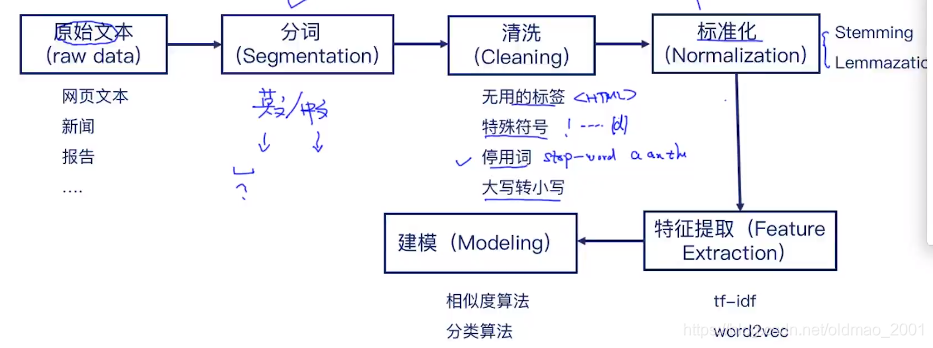
大概流程如下:
1、分词
2、预处理:拼写纠错,不同时态词语的还原,定冠词等无意义词的过滤,特殊词(例如一些html标签)的过滤,同义词替换处理。。。
3、文本的向量表示:booleanvector,count vector,tfidf,word2vec,seq2seq等
4、计算相似度(给定连个向量):欧式距离,cos距离,笛卡尔距离
5、排序
6、返回结果
最后看看关于问答系统现在两个思路:
| 现有的方法 | 知识图谱 |
|---|---|
| 文本的表示 | 实体抽取 |
| 相似度计算 | 关系抽取 |
把整体流程贴一下,下节从分词开始。