Naive Bayes模型中词概率的计算
垃圾邮件里经常出现“广告”,“购买”,“产品”这些单词。也就是p(“广告”|垃圾)>p(“广告”|正常),p(“购买”|垃圾)>p(“购买”|正常)……这些概率怎么计算?
垃圾这个词的概率
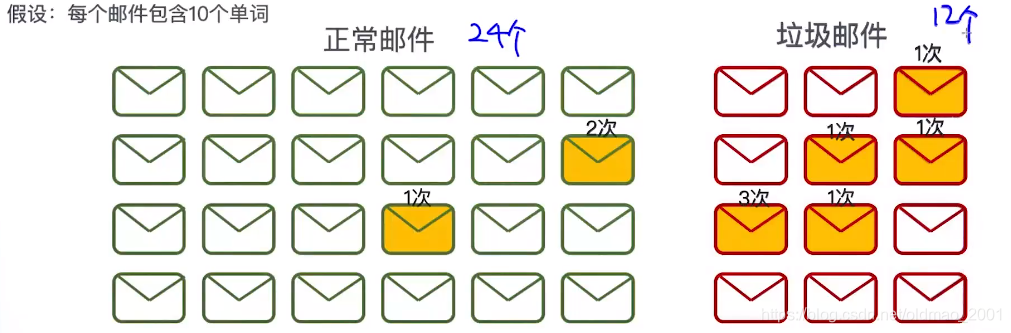
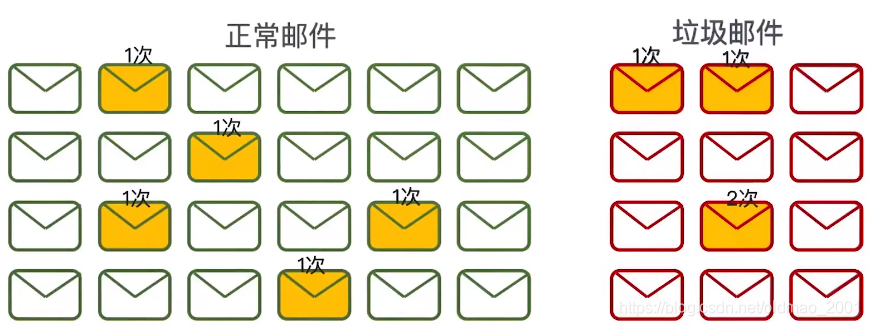
根据假设:正常邮件的单词总数为24*10,垃圾邮件为:12 *10
正常邮件含有“购买”词的概率多少?p(“购买”|正常)=3/240
垃圾邮件含有“购买”词的概率多少?p(“购买”|垃圾)=7/120
物品这个词的概率
和上面一样:
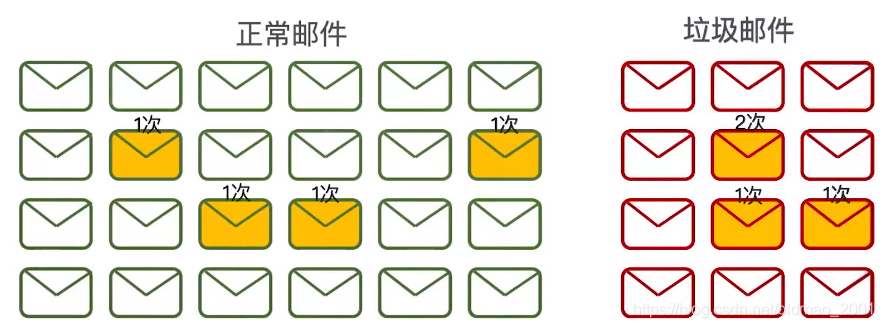
计算结果:
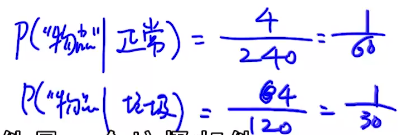
其他词的概率
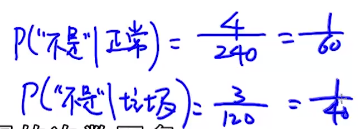
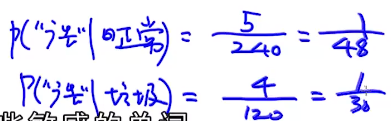
把词库中每个单词都按这个模式计算一遍就是训练一个朴素贝叶斯的模型了。
当然贝叶斯少不了先验概率:
Prior Information
先验就是我们已知的信息。
在这里:
有多少邮件是正常邮件?有多少邮件是垃圾邮件?
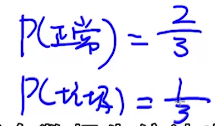
邮件分类标准
需要判断一个邮件不是垃圾邮件,那么就要满足:
p(正常∣内容)>p(垃圾∣内容)
根据贝叶斯公式:
p(内容)p(内容∣正常)p(正常)>p(内容)p(内容∣垃圾)p(垃圾)
分母消掉:
p(内容∣正常)p(正常)>p(内容∣垃圾)p(垃圾)
由先验概率可知:
p(内容∣正常)32>p(内容∣垃圾)p(垃圾)31
假如我们收到邮件:
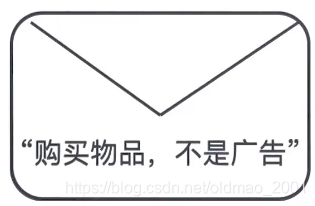
那么就可以计算:
p(内容∣正常)=p(购买,物品,不是,广告∣正常)
这里根据条件独立(Conditional Independence)概率的公式:
P(X,Y∣Z)=P(X∣Z)P(Y∣Z)
上面可以写成:
p(内容∣正常)=p(购买∣正常)p(物品∣正常)p(不是∣正常)p(广告∣正常)
这里面每一项我们都在朴素贝叶斯模型中训练好了,同理,
p(内容∣垃圾)也可以这样计算,那么最终二者可以进行比较并判断是否是垃圾邮件。
垃圾邮件分类实例
下面是我们已有的数据
垃圾邮件
点击 获得 更多 信息
购买 最新 产品 获得 优惠
优惠 信息 点击 链接
正常邮件
明天 一起 开会
开会 信息 详见 邮件
最新 竟品 信息
要判断的新邮件:
最新 产品 优惠 点击 链接
第一步、训练模型
先看先验:
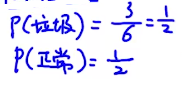
构建词库:
V={点击 获得 更多 信息 购买 最新 产品 优惠 链接 明天 一起 开会 详见 邮件 竟品}
维度为15
接下来计算每一个词在不同分类中的条件概率,为了防止出现一些概率为0的情况,朴素贝叶斯一般采用add-one smooth策略:
p(点击∣垃圾)=13+152+1=283
p(点击∣正常)=10+150+1=251
p(获得∣垃圾)=13+152+1=283
p(获得∣正常)=10+150+1=251
把新邮件的几个词算算:
p(最新∣垃圾)=13+151+1=141
p(最新∣正常)=10+151+1=252
p(产品∣垃圾)=13+151+1=141
p(产品∣正常)=10+150+1=251
p(优惠∣垃圾)=13+152+1=283
p(优惠∣正常)=10+150+1=251
点击上面有算过。。。
p(链接∣垃圾)=13+151+1=141
p(链接∣正常)=10+150+1=251
第二步、预测分类
先把预测推导出来的公式贴一遍:
p(内容∣正常)p(正常)>or<p(内容∣垃圾)p(垃圾)
直接把上面的带入即可:就是要比较(1)和(2)的大小:
p(最新∣正常)p(产品∣正常)p(优惠∣正常)p(点击∣正常)p(链接∣正常)p(正常)=25225125125125121(1)
p(最新∣垃圾)p(产品∣垃圾)p(优惠∣垃圾)p(点击∣垃圾)p(链接∣垃圾)p(垃圾)=14114128328314121(2)
明显(2)>(1),说明该邮件是垃圾邮件。
这里注意:
当词库中词很多,每个词语的条件概率会很小,连乘后会得到underflow的错误,可以在每个项前面加上log,再来比较。
log一来是严格递增函数,二来连乘可以变连加,不会越乘越小。
模型的评估
这个知识点在NG的课里面有提到过。
直接看这里,不写了
https://blog.csdn.net/Cheese_pop/article/details/78228156
准确率
acc:number of total samplesnumber of correctly classified samples
当我们的样本不平衡(正样本和负样本比例差距很大)的时候,准确率就不适合用来评估模型。
召回率
|
Correct |
not Correct |
| Selected |
TP(true positive) |
FP(false positive) |
| not Selected |
FN(false negitive) |
TN(true negitive) |
精确率
