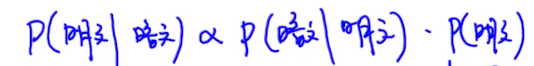文章目录
公式输入请参考: 在线Latex公式
Recap
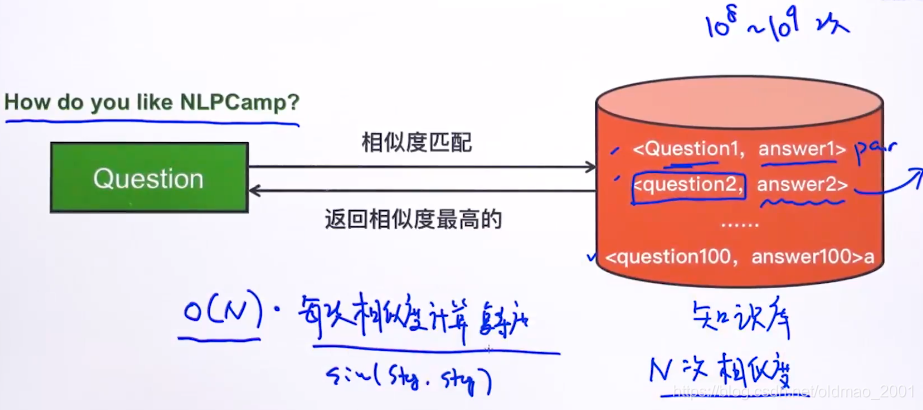
之前讲过要做一个问答系统,其构架如上图所示,但是有一个问题,就是每次提问后要去计算问题与知识库中每一个问题的相似度,再给出相应的答案,时间复杂度为
,如果知识库中的记录比较多(
条),比较次数也要这么多次,明显是无法满足问答系统实时的要求的。下面看如何来解决这个问题。
How to Reduce Time Complexity?
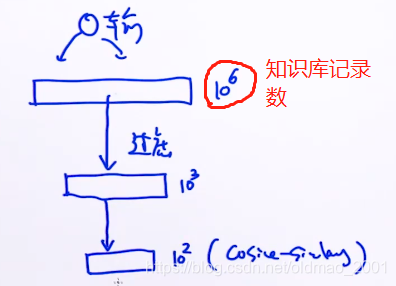
核心思路:“层次过滤思想”,通过类似下图中的层层过滤的方法,把不可能匹配提问的记录过滤掉,留到数量很少的记录在进行相似度计算。
那么整个问答系统构架就变成了:
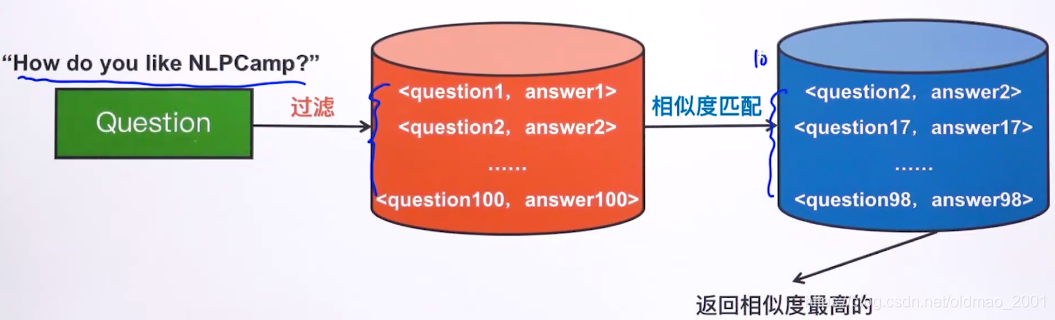
要用的的过滤技术就是:倒排索引
Introducing Inverted Index
直接通过例子来理解倒排表(索引),假如我们有四个文档:
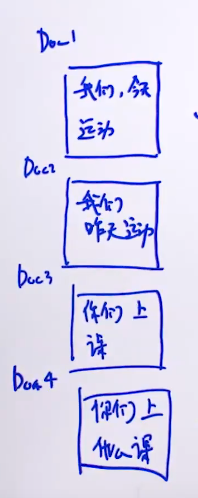
词典为:

那么,每个词出现在哪个文档就是倒排表:

当查询词为:“运动”的时候,我们根据倒排表知道,和这个词有关的文档是doc1,doc2
当查询词为:“我们 课”的时候,可以知道同时包含两个词的文档是没有的,这个时候可以返回包含两个词的文档并集或者包含单个词的文档集合。
回到问答系统构架图,过滤操作通过倒排表就很简单了,用户输入一个问题,那么可以把这个问题拆分为词,通过倒排表过滤掉知识库中没有包含这些词的记录。如何一次过滤后记录仍然很多,那么可以进行二次过滤,例如:同时包含两个词的记录,通过定义不同的过滤条件,最终得到比较少的需要匹配的记录。
Noisy Channel Model
把输入转换为一个文本的这类模型,就称为Noisy Channel Model
先上公式:
这个公式直接用贝叶斯公式可以推导,这里不写了。
应用场景:
语音识别,机器翻译,拼写纠错,OCR,密码破解
以上场景有一个共同的特点,就是都是把输入转换为文本。
机器翻译
如果是英译中,那么公式就是:
要寻找一个能够使得这个概率最大化的中文,然后把上面公式拆解为:
之前的课有说过:
$ p(英文|中文)
p(中文)$是language model
拼写纠错
公式如下:

语音识别
输入是一段语音波形,公式如下:

密码破解
输入是加密后的字符串,公式如下: