1、Introduction
1)网络深度很重要
Deep networks naturally integrate low/mid/highlevel features and classifiers in an end-to-end multilayer fashion, and the “levels” of features can be enriched by the number of stacked layers (depth).
2)层数的增加将导致梯度消失/爆炸,归一化初始值和中间层的归一化可以解决上述问题
An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning.
3)Plain and residual networks
Plain networks将层简单地堆叠,类似VGG那样
4)degradation 问题
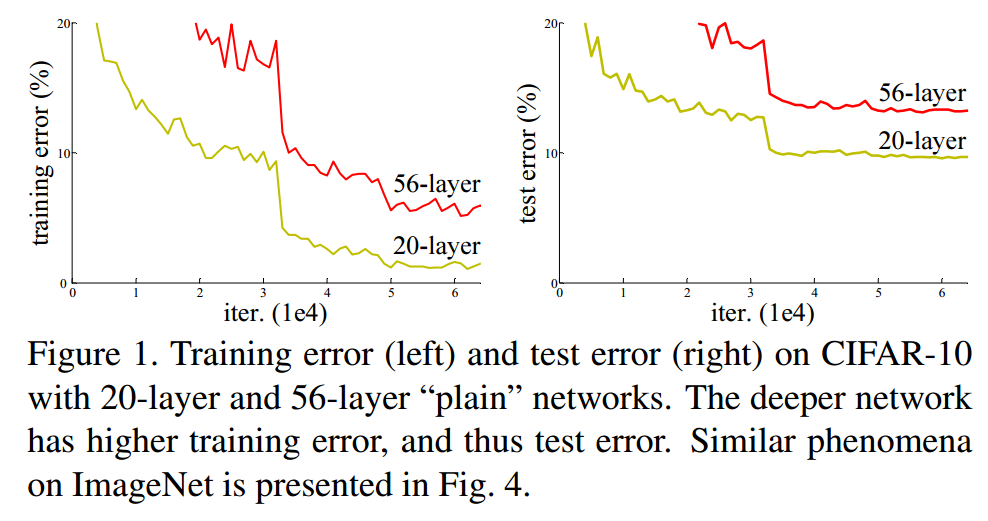
当更深层次的网络能够开始收敛时,一个退化的问题就暴露出来了:随着网络深度的增加,精度达到饱和(这可能并不奇怪),然后迅速退化。出乎意料的是,这种退化并不是由过拟合引起的,在一个合适的深度模型上增加更多的层会导致更高的训练误差。如果添加的非线性层可以作为对等映射,那么构造一个更深层次的模型的训练误差应该不大于其浅层的counterpart。退化问题表明由多个非线性逼近对等映射可能有困难,。
5)本文通过引入Deep Residual Learning来解决退化问题

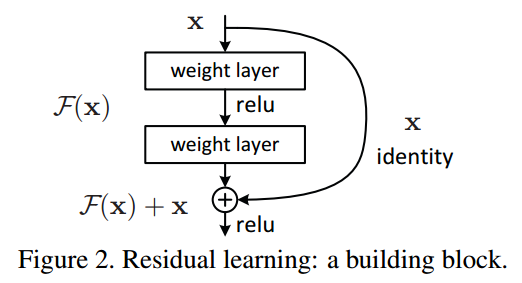
如果对等映射是最优的,那么就可以直接将中间的非线性层的参数置为零,即得到恒等映射。如果最优函数更接近于恒等映射而不是零映射,那么求解者就更容易找到与恒等映射相关的扰动,而不是将函数作为新的函数来学习。
2、Deep Residual Learning
1)Identity Mapping by Shortcuts
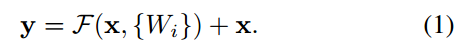
上式第一项称为residual mapping ,第二项称为shortcut connection。F(x)与x采用elementwise的形式进行相加,之后还会经过一个非线性层ReLU。如果输入输出width不相等,则可以采用下面的结构:
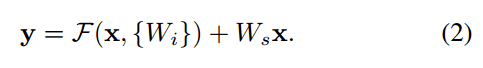
其中Ws为一个线性映射。后面文中有提到,Ws可以用2种方法实现:(A)用 0 padding增加的维度(通道),即identity shortcut,(B)用1*1卷积实现,即projection shortcut。两种方法都使用2步长
2)Network Architectures
采用与VGG类似的plain network进行比较。
3)实现
采用了图片增强,conv之后加BN,再ReLU。weight decay of 0.0001 and a momentum of 0.9
3、Experiments
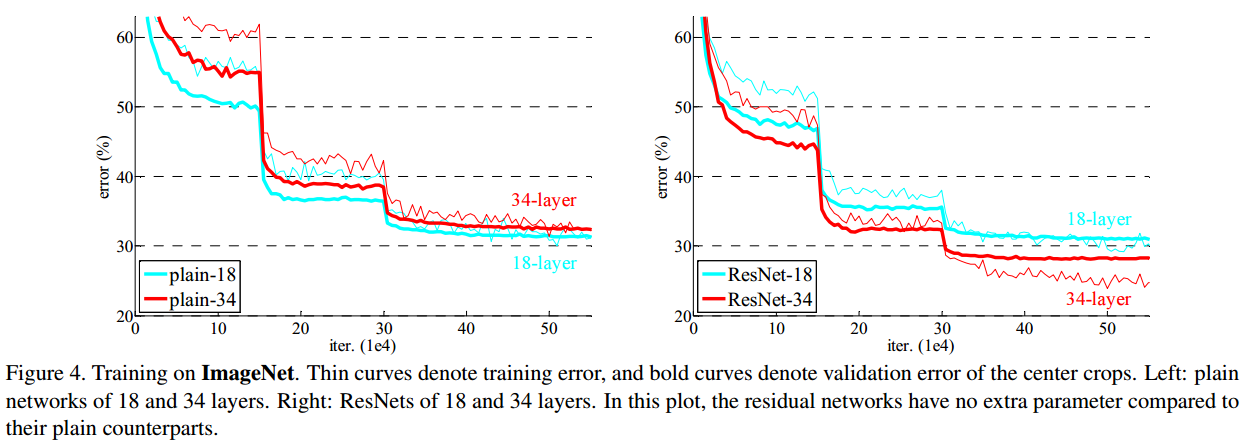
1)与plain网络的对比(参数、操作数相等(不考虑旁路的相加))

2)identity shortcut 和projection shortcut的对比

ResNet-34 A在升维的地方使用 0 padding,ResNet-34 B在升维的地方使用projection shortcut,维数不变时使用identity shortcut;ResNet-34 C都用projection shortcut
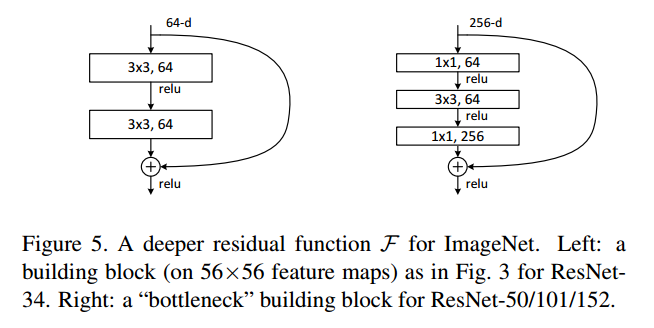
3)Deeper Bottleneck Architectures