这篇文章是kaiming大神的组的工作,在resnet上继续改进。一作谢赛宁,2013年从上海交大本科毕业后去UCSD读博士,现在他引1400+了(不知道我毕业时能不能有这个的一半QAQ),导师是Zhuowen Tu。
Introduction
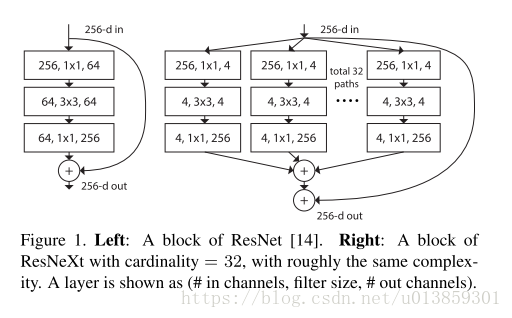
现代的网络设计中通常会次堆叠类似结构,如VGG,Inception,Resnet等,从而减少网络中超参数的数量,简化网络设计。
Inception使用了split-transform-merge策略,即先将输入分成几部分,然后分别做不同的运算,最后再合并到一起。这样可以在保持模型表达能力的情况下降低运算代价。
但是Inception的结构还是过于复杂了。作者想,我直接暴力均分输入,卷积层结构都是一样的,然后再merge。这样的话我只需要告诉网络分成几组就可以了,不就不需要再设计那么精巧的Inception了吗?
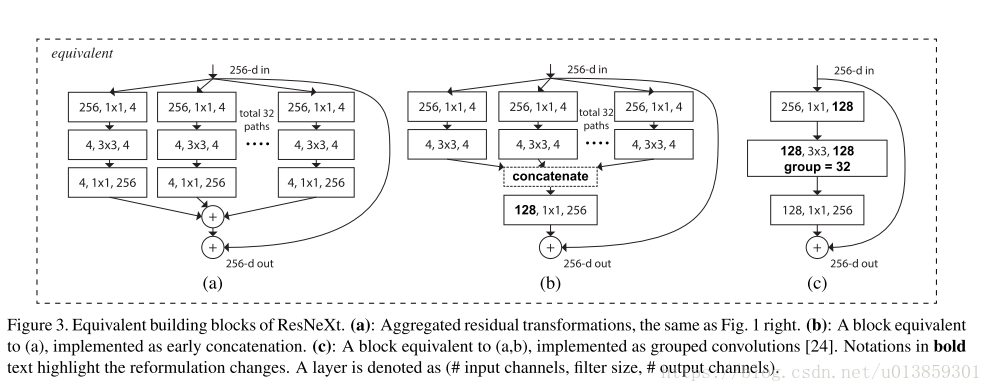
图3中的三种结构实际上是等价的。但是这种结构早在2012年AlexNet被发明出来的时候实际上已经被使用了。当初是因为一张显卡不够用,必须要将卷积放到两张显卡上算。因此现在几乎所有的神经网络框架的conv层都有group这个参数,但在作者之前就是没人把这个group作为超参数调一下(这是个很有意思的问题,明明框架里有,为啥大家不试试呢)。作者后来提到之前做网络压缩的人提出过group的方法,但是却极少有人研究其精度,这篇文章是从模型表达和精度的方向上写的。
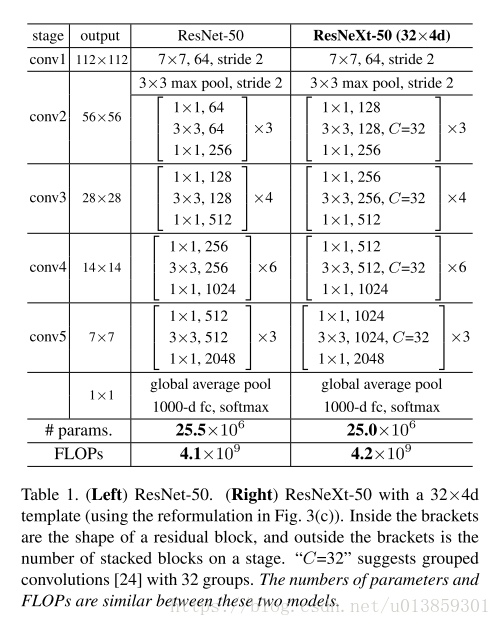
这种结构可以在保持网络的计算量和参数尺寸的情况下,提高分类精度。(论文里没有提到的是,虽然参数不变,但是显存增加了)。如表一中显示的,两边的网络具有相同的参数和计算量,但是右侧会有更好的精度。
就是这样一个看似简单的点子,却有很惊人的效果。作者把他的网络起名ResNeXt,意为ResNet的下一个版本。几乎在各方面表现吊打了ResNet,Inception等一系列网络。101层的ResNeXt吊打了计算量是他两倍的ResNet-200。在ImageNet上取得了第二名。
方法
这篇论文的方法其实用一句话就能说清了——卷积里加个group参数,或者是inception把不同的分支调到相同的结构。但是作者既然要发文章,就一定得强行解释一波他这个结构和conv group以及inception的区别。
模板
网络设计时遵循了两个原则:
- 如果相同尺寸的层共享相同的超参数。
- 如果图像经过了降采样层使尺寸除了2,那么要在通道数上乘2,以保证每个块的计算量大致相同。
有了上面两个约束,设计网络的自由度就小了很多。只需要定义出一个模板单元,就可以依次决定后面的单元。表1就是个栗子。
回顾简单神经元
简单神经元的形式满足
因此可以看作是一个集成转换的过程,即分割——转换——集成的过程。对于普通神经元来讲,分割就是把输入分成一个个的 ,变换就是乘权重,集成就是相加。
集成转换
其实在卷积内加分组的方法也可以看作是一个集成转换的过程。可以写成下面的形式:
这里面, 代表任意一种变换,而 则代表要给group。结合图3A图食用更佳。
那么问题来了,说这么多你这种方法和inception的区别是啥?
inception设计网络太复杂了,我们这个给个参数就行了呀XD
那你这种方法和直接对卷积层分组有什么区别?
直接对卷积层分组的话每个 对应的 都是一样的,我们这个可以让每个都不一样哦
可是你这个不是一样的吗?
都说了是可以不一样嘛。。我们取一样的是因为这种形式最简单。嗯。我们这个方法最牛逼。
模型能力
众所周知的是模型的表达能力和参数基本上是成正比的。但是采用这种结构后,刻意调整通道数,以保证每层的参数数量和计算量和普通的ResNet相同,结果表达能力居然提高了。
实现细节
这部分没什么好说的,用了BN,ReLU,sgd,等等。用了图3(c)的实现。
实验
在imagenet1000上做了ablation实验。把分组数量cardinility从1调到32,错误率持续走低。关键是在训练集上的误差也降低了。也就是说分组不是通过正则化的方法来提高精度的,而是的的确确增加了模型的表达能力。
在image-net5k上训练出来的模型,在1k上的错误率可以和直接在1k上训练出来的模型一战。作者认为这是个了不起的成就,毕竟5k的任务要更复杂一些。
之后又在CIFAR-10,100和COCO上测试了,都取得了不错的效果。
当然这些实验基本上都是直接和同算力的ResNet对比的。