本篇内容参考《百面机器学习》《统计学习方法》
第一部分:理论概述
线性回归模型作为基础模型,或者说作为基石算法,是机器学习算法的入门算法
第二部分:模型理论
1 模型前提
1 )线性模型: (
,截距
以包含在内)
注意: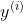 ,
,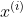 ,
,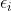 均为随机变量,
均为随机变量,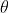 为系数,且满足独立同分布
为系数,且满足独立同分布
2) ,中心极限定理决定
3 )极大似然原理:假设一场试验中,发生A结果,并未发生B结果或者其他结果,那么说明该试验对A有利,进而数学上可以表达为,其中
为有利于A的条件
2 建立模型



注意:
-
X是m行n+1列矩阵,
-
残差和为0

3 最小二乘解析解的限制问题
1),其中要求
可逆
很明显发现:无法保证所有的数据集都满足该限制,那么数学上最优解,我们有的时候无法求出
故而增加n阶单位阵,以及参数
,从而模型最优解调整
这里一定可逆,证明思路如下

2)求逆矩阵困难问题
所以针对线性模型的平方损失函数,我们在计算机上不采用最小二乘解析解的方式,而是采用梯度下降算法近似求出
第三部分 模型过拟合与欠拟合问题
1 数据拟合中一般出现欠拟合与过拟合问题,当数据量足够的时候,一般过拟合问题成为算法的天花板,因而过拟合问题的解决成为主要问题,即如何保证数据拟合呈现鲁棒性(或者说使得模型具有鲁棒性)
注意:欠拟合:一般是指模型拟合数据的映射关系复杂度低,损失高
过拟合:一般是指模型拟合数据的映射关系复杂度高,损失低
2 欠拟合出现的原因以及解决方法
1)欠拟合出现的一般原因
- 算法学习能力不强
- 数据量不够
- 特征属性太少(特征属性和目标属性之间没有那么强的映射关系)
2)欠拟合问题的解决方法
- 换一种算法学习能力强的
- 增加数据量
- 增加特征
注意:增加特征常常采用多项式扩展,即低维度映射到高维度,将低维度非线性数据映射到高维度上成为线性数据
3 过拟合出现的原因以及解决方法
1)过拟合出现的一般原因
- 算法学习能力太强
- 数据量不够
- 进行训练的数据和实际数据相差比较大
2)过拟合问题的解决方法
- 对算法学习能力做出限制
- 增加数据量
- 一般不需要进行太深的维度扩展(比如多项式扩展)
4 线性模型过拟合问题(在算法学习上做出限制)
线性回归模型过拟合情况下,我们采用三种方式:Ridge回归,Lasso回归,ElasticNet回归
1)Ridge回归
通过对损失函数添加L2正则项(不对截距进行正则)

2)Lasso回归
通过对损失函数添加L1正则项(不对截距进行正则)

3)ElasticNet回归(不对截距进行正则)
通过对损失函数添加L1正则项和L2正则项以及赋予权重系数p

4)三种方法的优劣对比
在实际数据中,数据维度中是存在噪音和冗余的,而稀疏解是可以找到有用的维度,并减少噪音和冗余的影响,提高模型的鲁棒性和准确性
- 第一点 Ridge回归不具有稀疏解特性,但是具有更快的求解速度(采用了梯度下降方法)
- 第二点 Lasso回归具有稀疏解特性,可以更好的去除噪音冗余数据特征(采用了坐标轴下降方法)
- 第三点 ElasticNet回归既具有求解速度也具有稳定性
注意:实际应用中,由于数据在进行建模之后,已经去除了噪音和冗余特征,所以说Ridge回归采用的更为普遍
第四部分 线性回归模型的常用评价指标
1 MSE(越趋于0越好,取值范围为0到正无穷)

2 RMSE(越趋于0越好,取值范围为0到正无穷)

3 (越趋于1越好,取值范围为负无穷到1)

