一、回归与分类的区别
- 回归的Y变量为连续数值型,如房价、人数等
- 分类的Y变量为类别型,如是否生存、颜色、有无癌症等
二、单变量线性回归
使用一个简单的线性模型:

来拟合现有的数据集。可以看到这个线性模型是以x为自变量,
逼近的过程,其实就是不断调节

基准就是
因此定义了代价函数来衡量

可以看到该函数是以
为求
- 正规方程法:即求得使偏导为零的那些θ值
- 梯度下降法法:
(for j=0 and j=1)
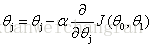
三、多变量线性回归
- 线性模型:

- 代价函数:
θ:
通过对J求偏导得:
单变量线性回归其实就是多变量线性回归的特例。
特征缩放:在进行模型训练之前,需要将特征进行特征缩放,一般是将其缩放为0~1,一般使用如下公式进行缩放:
将特征进行缩放,可以加快学习速率。α选择:α如果过小则会学习速率过慢,如果过大则会震荡,一般是选择一系列α,并画出J关于迭代次数的函数。如果选择手链且学习速率较大的那个α值。
多项式回归:多项式回归可以处理非线性的情况,通过将
表示为多项式,如
,就可以模拟非线性的情况。只需要使:


其他步骤和线性回归是一样的。

正规方程求解:
由于求解正规方程的运算时间是
